11.9 聚类K值选取与分析#
在前面几节内容中,我们陆续介绍了3种常见的聚类算法原理及其实现 、4种常见的聚类外部评价指标和3种常见的聚类内部评价指标,对于聚类算法的主体内容算是介绍得差不多了,但是还遗留了最后一个问题——K值的选取。通常来说在实际场景中数据集的标签都是未知的,相反恰好需要通过聚类结果来辅助将各个簇的样本区分开。那到底应该如何选取K值呢?
经过上一节内容的介绍,有读者可能会说,以不同的K值为超参数,以某种内部评价指标为标准,通过交叉验证来选择最佳K值不就行了吗?虽然这种想法看起来有道理,但实际上却行不通。以轮廓系数为例,根据轮廓系数的原理可知我们并不能够严格得出在最佳K值的情况下轮廓系数同样也能够取得最大值。因此,我们常常就需要借助一些其它手段来对K值进行分析。
在聚类分析中,有两种常见的方法用于K值的选择,分别是肘部法和轮廓系数法,下面分别逐一进行介绍。
11.9.1 K值分析肘部法原理#
根据11.1节内容的介绍我们知道,基于Kmeans聚类框架下的聚类算法在最小化目标函数时本质上就是最小化整个簇内距离。根据簇内距离的定义可知,当K值越小时那么簇内距离便会越大;而当K值越大时那么簇内距离便会越小,极端一点在K值等于样本数量时,那么此时的簇内距离可以取到最小值0。
进一步,根据分析可知,在K值由小变大的过程中,随着K值的增大簇内距离便会逐步减小,但是当K值取得最优解后簇内距离便不会出现明显的降幅。此时可以想象这么一个场景,假设某数据集以不同的K值进行聚类处理并同时计算得到对应的簇内距离和,再以不同的K值为横坐标,簇内距离为纵坐标进行可视化,便可以得到类似如图11-19所示的结果。
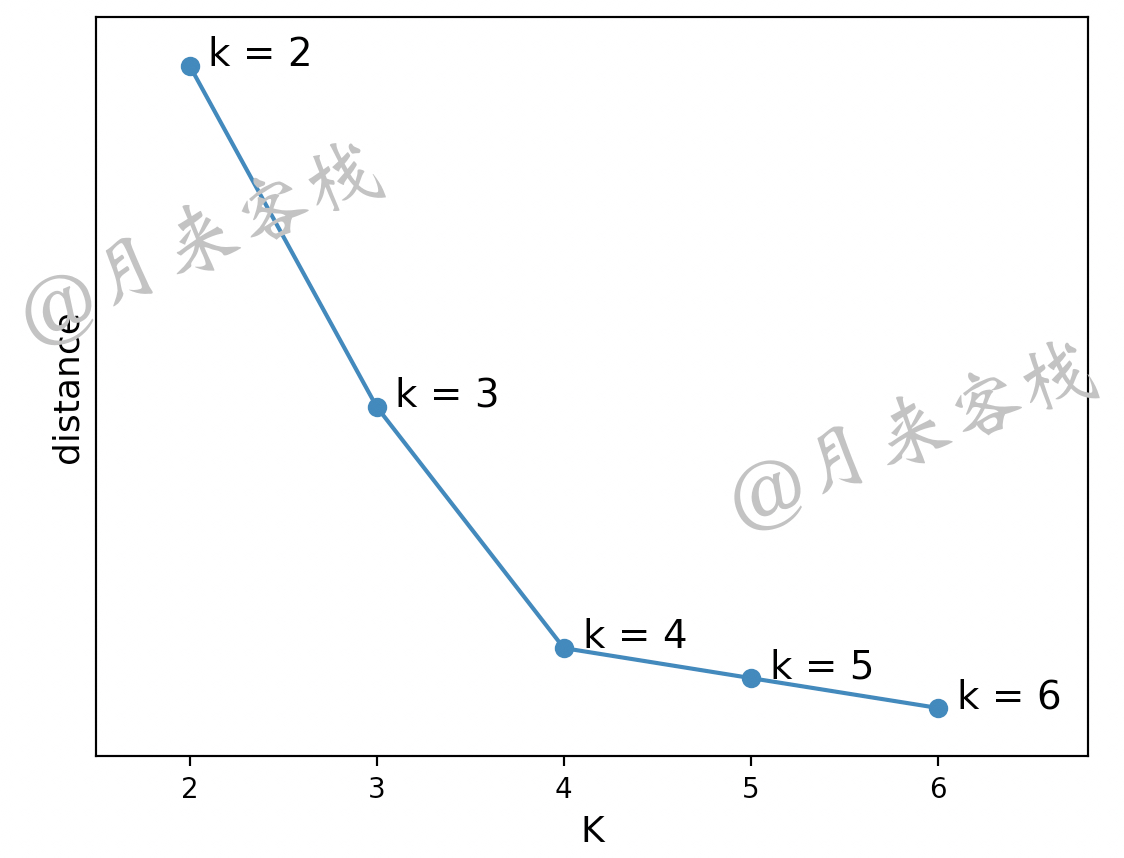
如图11-19所示,可以发现刚开始随着K值的增大簇内距离开始急剧减小,当K值大于4之后簇内距离的减少幅度便开始明显降低,因此便可以经验性地得出4是该数据集对应K值的最优解。之所以可以凭借这样的经验进行判断是因为,当K值小于最优解时K值每增加1也就代表多了1个簇结构,整个簇内距离和自然会得到大幅下降;而当K值大于最优解之后K值每增加1也就仅仅只是将原本一个正常的簇结构一分为二了,因此即便整个簇内距离和有所降低,但是幅度也不会太大。
基于这样的经验性准则便可以根据类似图11-19中的方法来进行K值的选取。同时,由于图11-19中的变化曲线类似于我们手臂的肘部,因此该方法被称之为肘部法。
11.9.2 K值分析肘部法实现#
在介绍完肘部法的分析原理以后再来看如何实现这一可视化过程,完整示例代码可参见 AllBooKCode/Chapter11/C12_elbow_analysis.py 文件。这里首先需要定义一个函数来根据聚类结果计算簇内距离和并进行可视化,示例代码如下:
1 def elbow_analysis(X, range_n_clusters, all_cluster_labels, all_centers):
2 all_dist = []
3 for n, n_clusters in enumerate(range_n_clusters):
4 cluster_labels = all_cluster_labels[n]
5 centers = all_centers[n]
6 dist = 0
7 for i in range(n_clusters): # 遍历每一个簇,计算当前簇的簇内距离
8 x_data = X[cluster_labels == i]
9 tmp = np.sum((x_data - centers[i]) ** 2, axis=1)
10 dist += np.sum(np.sqrt(tmp)) # 累计当前聚类结果下所有簇的簇内距离和
11 all_dist.append(dist)
12 plt.plot(range_n_clusters, all_dist) # 绘制肘部曲线
13 plt.scatter(range_n_clusters, all_dist) # 绘制各个点
14
15 for i in range(len(range_n_clusters)): # 在图上进行K值标记
16 plt.annotate(f"k = {range_n_clusters[i]}",
17 xy=(range_n_clusters[i], all_dist[i]), fontsize=14,
18 xytext=(range_n_clusters[i] + 0.1, all_dist[i]))
19 plt.xlim(range_n_clusters[0] - 0.5, range_n_clusters[-1] + 0.8) # 调整范围
20 plt.ylim(all_dist[-1] * 0.9, all_dist[0] + all_dist[-1] * 0.1)
21 plt.yticks([]) # 去掉y轴上的刻度显示
22 plt.xlabel("K", fontsize=13)
23 plt.ylabel("distance", fontsize=13)
24 plt.show()在上述代码中,第1行X表示原始的训练样本为一个 [n_samples, n_features]的二维矩阵;range_n_clusters是K值的取值范围,为一个普通的列表;all_cluster_labels是一个普通列表,每个元素为一个一维向量,即某一K值下的聚类标签;all_centers也是一个普通的列表,每个元素为一个[n_clusters,n_features]的二维矩阵,即某一K值下的聚类簇中心。第3~5行开始遍历不同的K取值,并取对应的聚类结果和聚类簇中心。第7~10行是遍历每一个簇并累加得到所有簇的簇内距离和。第12~13行是对计算得到的结果进行可视化。第15~18行是在图中进行标记。第20~24行是调整坐标轴范围等。
最后,可以通过如下代码来根据不同的K值进行聚类,并调用上述函数对结果进行可视化:
1 if __name__ == '__main__':
2 X, y = make_blobs(n_samples=500, n_features=2, centers=4, cluster_std=1,
3 center_box=(-10.0, 10.0), shuffle=True, random_state=1)
4 range_n_clusters = [2, 3, 4, 5, 6]
5 all_cluster_labels, all_centers = [], []
6 for n_clusters in range_n_clusters: # 对不同K值进行聚类处理
7 clusterer = KMeans(n_clusters=n_clusters, random_state=10)
8 cluster_labels = clusterer.fit_predict(X)
9 centers = clusterer.cluster_centers_
10 all_cluster_labels.append(cluster_labels)
11 all_centers.append(centers)
12 elbow_analysis(X, range_n_clusters, all_cluster_labels, all_centers)在上述代码中,第2~3行是得到一个人造数据集。第6~11行是根据不同K值对数据集进行聚类处理并保存对应的聚类结果。第12行则是对结果进行可视化。
进一步,根据类似的做法,还可以对一些常见的数据集进行簇内距离随K值变化的曲线图可视化,如图11-20所示。
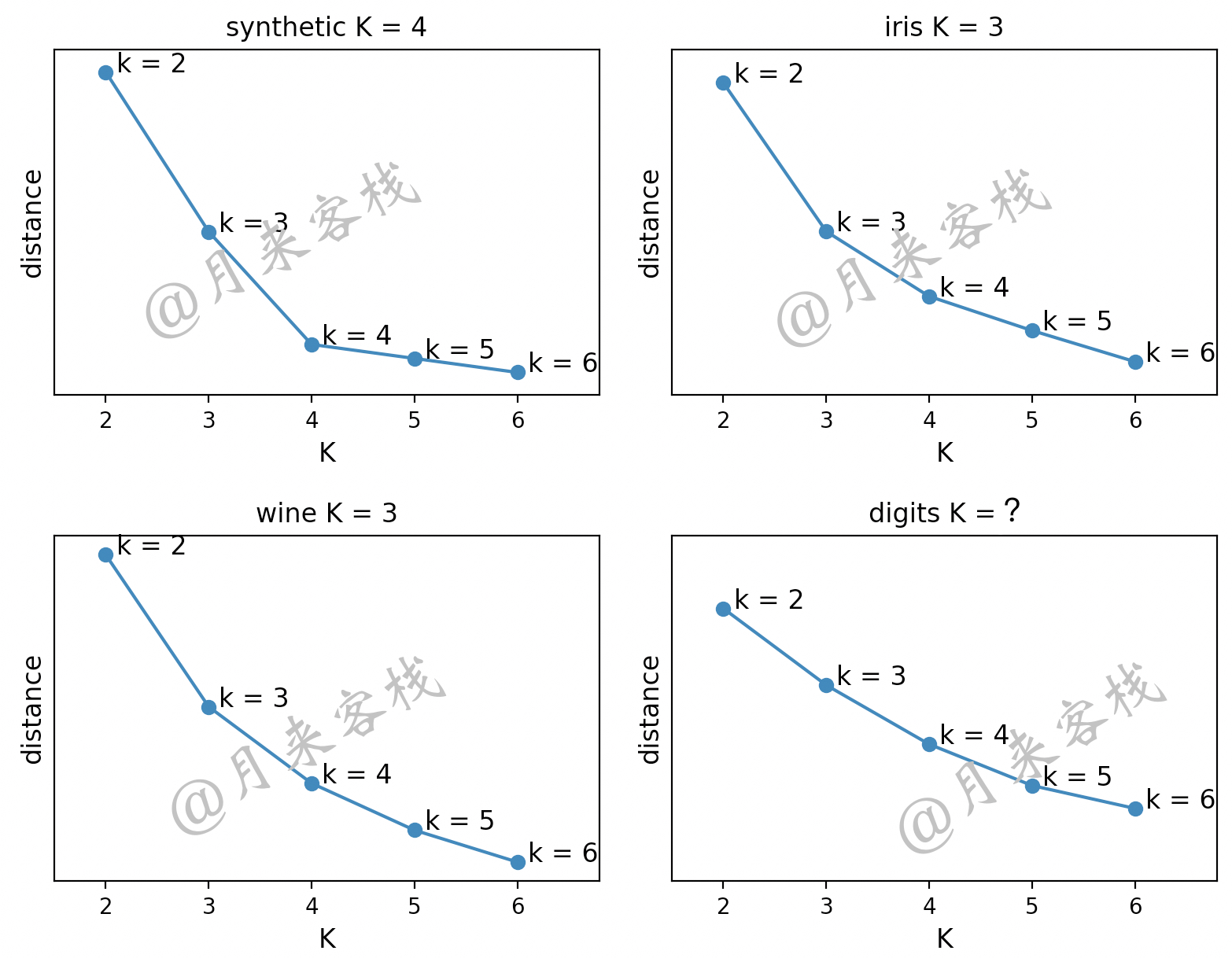
如图11-20所示,在簇内距离随K值变化的曲线中我们利用肘部法能够很容易地判断前3个数据集(synthetic、iris和wine)的K值。但是对于最后一个数据集digits(数据集原本一共有10个类别,这里只取了其中若干个类别)来说,K值应该取多少呢?此时还可以借助轮廓系数法来进行分析。
11.9.3 K值分析轮廓系数法原理#
在第11.9.1节内容中,我们介绍了第1种用于K值选取的肘部法。虽然该方法一定程度上能够帮助我们有效地对K值进行选取,但是在某些情况下依旧存在着肘部法失效的情况。如图11-20中最后一幅图所示,随着K值的增大簇内距离和并没有出现明显的骤降情况,而是稳步地在进行减少,此时利用肘部便无法选择正确的K值。下面,开始介绍第2种K值分析方法,轮廓系数法。
轮廓系数法的核心思想是观察每个簇中样本数量的分布情况,以及簇中每个样本点轮廓系数偏离整体轮廓系数的程度来进行K值的分析判断。根据轮廓系数分析方法,图11-19中所列的人造数据集经过不同K值聚类后便可得到如图11-21所示的分析结果。