5.6 多GPU训练#
在深度学习中一些大型的网络模型往往需要大量的计算资源才能进行训练,因为每一层神经网络都需要对输入数据进行复杂的矩阵乘法和非线性变换操作。由于单个GPU的计算能力及显存有限可能无法满足大规模深度神经网络的训练需要,因此我们便需要使用多个GPU来加速网络的训练速度。在接下来的这节内容中,我们将会简单介绍几种多GPU模型训练的基本思想,并就其中一种最常见的方法进行详细讲解。
5.6.1 训练方式#
从理论上来讲,实现模型多GPU训练的策略有模型并行、数据并行和混合并行3种,然而在实际情况中并不是每一种都具有较高的可行性。
1. 模型并行
模型并行是指将模型的不同层或不同计算逻辑分配到不同GPU上进行训练的技术,此时每个 GPU 只负责处理部分逻辑的计算。通常这种方法适用于模型较大且无法在单个GPU上容纳的情况,例如现阶段各个大模型的训练过程通常都会采用模型并行技术。常见的模型并行技术有:层并行(Layer Parallelism),把模型的不同层分配给不同的 GPU;张量并行(Tensor Parallelism),把一个层内部的张量(如 Linear 权重矩阵)按维度切块分配到多个 GPU 上,如 LaMMA 和 DeepSeek 等就是采用的张量并行策略。
2. 数据并行
数据并行是指将输入网络的训练数据分成多个批次,每个批次在不同的GPU上进行并行计算。此时每个GPU上的模型权重都相同,只是处理的数据不同,每个GPU在训练完自己的批次数据后再将梯度更新汇总到主GPU上,从而实现模型参数的更新。这种方法的优点是简单易实现不容易出错,因此也是实现多GPU训练中使用最多的一种策略。
3. 混合并行
混合并行是一种同时使用数据并行和模型并行的技术。在混合并行中网络模型将会被拆分为多个子模型,并将每个子模型分配到不同的GPU上进行计算然后将计算好的结果传递给下一个GPU进行处理,同时在每个GPU也将使用数据并行技术进行处理。混合并行的优点在于它可以同时利用数据并行和模型并行的优势,因为数据并行可以处理大规模数据集,而模型并行可以扩展深度神经网络的规模。但混合并行也存在一些挑战,例如需要更多的硬件资源、实现难度较大、调试和优化复杂等问题。
以上便是3中并侧策略的基本思想,但是需要注意的是多 GPU 并不是越多越好,过多数量的 GPU 可能会造成通信延迟和资源浪费,并极有可能出现多个 GPU 的训练速度反而比单 GPU 更慢的情况。在实际使用中,我们需要根据具体的硬件条件和数据规模选择合适的多GPU训练策略。
下面,我们对使用最为常见的数据并行策略进行详细介绍。
5.6.2 数据并行#
在使用数据并行策略实现多GPU训练时,首先会将整个小批量数据再划分成多个小批次并分配到不同的GPU上,同时整个模型也将被复制到每个GPU上,然后在每个GPU上模型均各自独立地完成损失和梯度的计算,随后将每个GPU上计算得到的损失和梯度汇聚到主GPU上得到整个小批量数据样本的平均梯度,最后再将该梯度分配到其它GPU中进行各自模型参数的更新以完成一次迭代训练过程[1]。
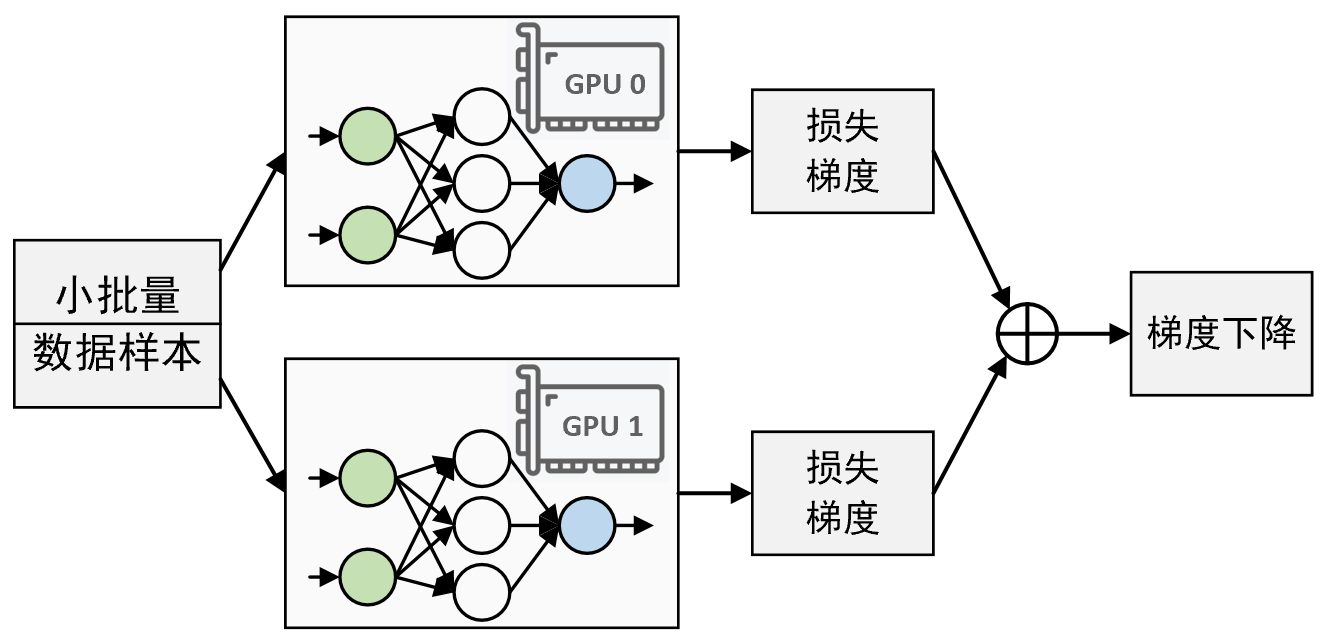
如图5-23所示便是含有两个GPU的数据并行原理图。例如此时每个小批量数据都含有256个样本,那么图示中每个GPU将会被分配得到128个样本进行后续的计算处理。同时,每个GPU上也都有着一模一样的网络模型,并且它们在各自拿到128个样本后会分别计算损失和梯度,然后再将两部分的梯度汇聚到主GPU上得到256个样本的平均梯度,最后再用该梯度通过梯度下降算法并行对每个GPU上的模型进行参数更新。
由此可以发现,对于数据并行这一多GPU训练策略来说,本质上就相当于每个GPU各自完成了部分数据样本的训练过程,且在整个前向传播和反向传播中每个GPU之间均是相互独立的,只有在进行整体损失和梯度的计算时才进行交互,因此基于数据并行的多GPU训练方法相对来说较为容易实现。但在实践中该方法也需要权衡计算资源、通信开销和同步效率等因素。
5.6.3 使用示例#
下面,我们以4.9节中介绍的ResNet18为例来介绍如何通过PyTorch框架实现网络模型的多GPU训练过程。在这里首先需要清楚的是,对于是否使用多GPU进行模型训练与模型的定义即前向传播过程无关,也就是我们只需要修改模型训练部分的代码即可。以下完整示例代码可参见Code/Chapter05/C07_MultiGPUs/train.py文件。
1. 获取GPU
首先,我们需要定义一个辅助函数来获取得到指定的GPU设备,示例代码如下所示:
1 def get_gpus(num=None):
2 gpu_nums = torch.cuda.device_count()
3 if isinstance(num, list):
4 devices = [torch.device(f'cuda:{i}')
5 for i in num if i < gpu_nums]
6 else:
7 devices = [torch.device(f'cuda:{i}')
8 for i in range(gpu_nums)][:num]
9 return devices if devices else [torch.device('cpu')]在上述代码中,第1行num如果为list,则返回list中对应编号的GPU设备,如果num为整数,则返回主机中前num个GPU设备。第2行是得到当前主机上GPU设备的个数。第3~5行是根据num为list的情况获取对应的GPU设备。第7~8行是根据num为整数情况获取得到对应的GPU设备。第9行则是判断是否有GPU设备,没有则返回CPU设备。
上述代码运行结束后结果如下所示:
1 [device(type='cpu')] #无GPU时的情况
2 [device(type='gpu', index=0), device(type='gpu', index=1)] # 有两块GPU设备2. 数据并行