9.12 含注意力的RNN网络#
在9.10节和9.1节内容中我们分别介绍了注意力机制的原理以及它在Seq2Seq翻译模型中的具体应用。在Seq2Seq这个翻译场景中,我们明确地知道在解码器在解码每一个时刻时,query来自于当前解码时刻对应的隐含向量,并且这样做的动机也十分合理。但是,在某些场景中尽管我们也想引入注意力这一机制,但是却不存在对应的query向量。
例如在8.2节内容中介绍的使用RNN进行文本分类的场景中,我们完全可以利用注意力机制的思想来得到一个注意力权重,然后作用于每个时刻的隐含状态并得到一个上下文向量,最后再利用上下文向量完成后续的分类任务。
9.12.1 含注意力的RNN结构#
对于这种不存在query向量的场景中,我们可以自己定义一个全局的query向量来完成注意力权重的计算过程,然后再将其作用于RNN输出的每个时刻的向量上,进而得到上下文向量。值得注意的是,这里定义的全局query向量也是一个可训练的模型参数。整个网络结构如图9-28所示。
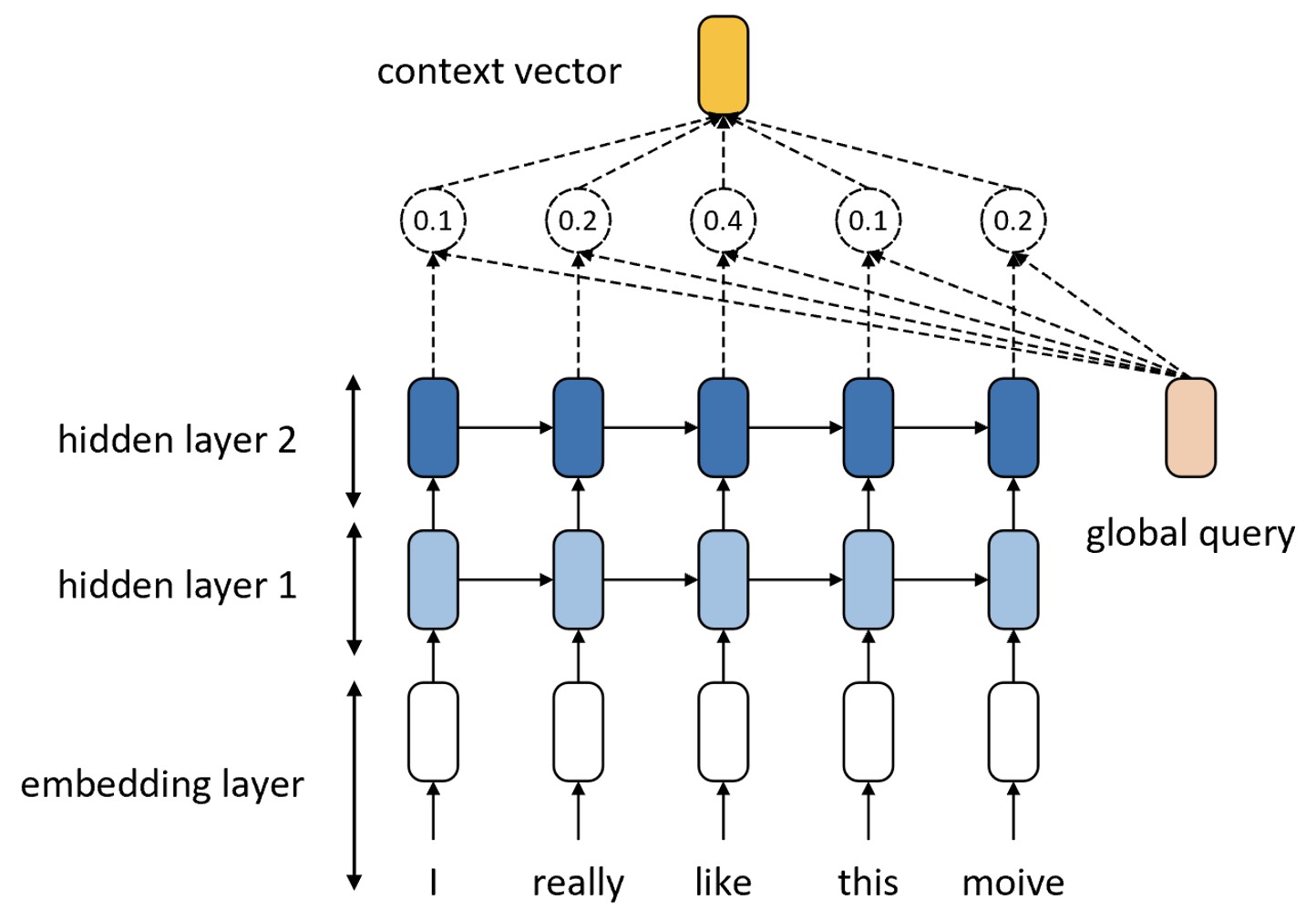
如图9-28所示便是含有注意力机制的RNN网络结构图,其中右侧的 global query便是我们自己定义的全局query向量。输入文本”I really like this moive“在经过RNN编码后便会得到5个时刻的输出向量。此时,global query 将会同这个5个向量分别计算得到一个注意力值并进行归一化。同时,在这里计算注意力值的时候可以是任何一种你认为合理的方式,例如可以是最简单两个向量的内积、也可以是一次线性变换后的内积等等,后续我们将以9.10节中的Luong注意力计算法来进行实现。在计算得到每个时刻对应的注意力权重以后,再将其作用于每个时刻的隐含向量便可以得到最终的上下文向量。最后,使用一个分类层对上下文向量进行分类即可。
9.12.2 含注意力的RNN实现#
这里我们以8.2节内容中实现的TextRNN模型为基础进行改造,我们只需要在原有RNN编码结束以后再加上一个注意力层即可。以下完整示例代码可参见Code/Chapter09/C08_TextRNNAtt/TextRNN.py文件。
1. 注意力层实现
由于此时的 global query是一个固定的向量,不会随着样本数量的变化而变化,所以我们在实现Luong注意力机制时需要做一点小的改动,实现代码如下所示:
1 class LuongAttention(nn.Module):
2 def __init__(self, hidden_size, dropout=0.):
3 super(LuongAttention, self).__init__()
4 self.linear = nn.Linear(hidden_size, hidden_size)
5 self.drop = nn.Dropout(dropout)
6
7 def forward(self, query, key, value, src_key_padding_mask=None):
8 scores = torch.matmul(key, self.linear(query).transpose(0, 1))
9 scores = scores.squeeze(-1)
10 if src_key_padding_mask is not None:
11 scores = scores.masked_fill(src_key_padding_mask, float('-inf'))
12 attention_weights = torch.softmax(scores, dim=-1)
13 context_vec = torch.bmm(self.drop(attention_weights).unsqueeze(1), value)
14 return context_vec, attention_weights在上述代码中,第7行query便是上面的我们定义的global query,形状为[1, hidden_size];key和value则均是RNN编码完成后每个时刻对应的隐含状态,形状为[batch_size, src_len, hidden_size];src_key_padding_mask则是输入序列的填充情况,形状为[batch_size, src_len]。在第8行中,query经过线性变换且转置后的形状为[hidden_size,1],scores的形状为[batch_size, src_len, 1]。第9行是进行维度压缩,之后scores的形状为[batch_size, src_len]。第10~11行则是将填充部分的注意力权重置为负无穷大。第12~13行则是分别对注意力权重进行归一化并计算得到上下文向量,形状为[batch_size, 1, hidden_size]。
2. 模型实现
在完成上述注意力层的实现以后,我们继续基于之前的TextRNN代码进行修改,并且只需在对应条件下添加一个注意力层即可,示例代码如下所示(以下仅为关键部分的代码,各位读者请直接阅读源码):
1 class TextRNNAtt(nn.Module):
2 def __init__(self, config):
3 super(TextRNNAtt, self).__init__()
4 if config.cell_type == 'RNN':
5 rnn_cell = nn.RNN
6 elif config.cell_type == 'LSTM':
7 rnn_cell = nn.LSTM
8 out_hidden_size = config.hidden_size * (int(config.bidirectional) + 1)
9 self.config = config
10 if config.cat_type == 'attention':
11 self.global_query = nn.Parameter(torch.randn((1, out_hidden_size)))
12 self.attention = LuongAttention(out_hidden_size)
13
14 def forward(self, x, labels=None):
15 x = self.token_embedding(x)
16 x, _ = self.rnn(x)
17 if self.config.cat_type == 'last':
18 x = x[:, -1]
19 elif self.config.cat_type == 'mean':
20 x = torch.mean(x, dim=1)
21 elif self.config.cat_type == 'attention':
22 x, atten_weights = self.attention(self.global_query, x, x)
23 x = x.squeeze(1) 在上述代码中,第10~12行以及第21~23行代码便是我们本次引入注意力机制所新增的部分,其余部分保持不变。在第10~12行代码中,我们根据判断条件使用Parameter类来初始化了一个global query向量,以将其作为模型的权重参数;进一步我们实例化了一个注意力层。在第21~23行代码中,则是根据判断条件计算注意力的前向传播过程,其中x便是最后返回的上下文向量,经过维度压缩后的形状为[batch_size, out_hidden_size]。
最后,我们使用与8.2节内容中相同的模型配置与数据集来进行对比,运行结果如下所示:
1 Epochs[1/50]--batch[0/2093]--Acc: 0.0625--loss: 2.8678
2 Epochs[1/50]--batch[50/2093]--Acc: 0.2344--loss: 2.355
3 Epochs[1/50]--batch[100/2093]--Acc: 0.5156--loss: 1.6447
4 Epochs[1/50]--batch[150/2093]--Acc: 0.6641--loss: 1.3592
5 Epochs[1/50]--batch[200/2093]--Acc: 0.6406--loss: 1.3263
6 Epochs[1/50]--batch[250/2093]--Acc: 0.6719--loss: 1.1439
7 Epochs[1/50]--batch[300/2093]--Acc: 0.6484--loss: 1.1429
8 Epochs[1/50]--batch[350/2093]--Acc: 0.6016--loss: 1.2412
9 Epochs[1/50]--Acc on val 0.8079
10 Epochs[8/50]--Acc on val 0.8624从上述结果可以看出,模型在完成1轮训练以后在测试集上的准确率将会达到0.8079,8轮训练之后将会达到0.8624。然而,在没有使用注意力机制的情况下,这两个值分别是0.7475和0.7922,这也说明在这一场景中引入注意力机制的做法对模型的分类效果具有显著提升。
9.12.3 小结#
在本节内容中,我们首先引入了一种新场景下的注意力机制运用方法,并介绍了其出现的动机;然后我们详细介绍了整个模型的构建原理与过程;最后,我们基于TextRNN模型来实现了含注意力的RNN文本分类模型,并与原始的TextRNN的分类结果进行了对比。值得一提的是,注意力机制的思想其实是比较灵活的,不管使用什么样的形式我们只要能通过某种方式计算得到一个权重向量,并将其作用于对应的多个输出值(例如RNN中的多个时刻、CNN中的多个通道亦或是不同网络层的输出结果等),这都算是对注意力机制的运用。