10.13 GPT-1模型#
经过10.2节和10.6节内容的介绍,我们对基于多头注意力机制的网络模型已经有了深刻的认识。根据10.6节内容可知,BERT模型本质上只是一个基于Transformer编码器的网络结构,它通过多层多头注意力机制来对输入序列进行编码并完成后续下游任务。这种通过对整个文本序列同时进行编码理解并完成后续下游任务的过程我们称之为自然语言理解。在接下来几节内容中,我们将会介绍另外一种以自然语言生成方式来进行建模的网络模型。
10.13.1 GPT-1动机#
在第9章内容开始我们介绍到自然语言处理可以分为自然语言理解和自然语言生成两大部分。对于自然语言理解来说它包括的场景有文本蕴含、问题回答和文本分类等,并且对于这类任务来说它们都有两个共同的地方——特定任务下的网络结构和高质量的标注数据。在传统的判别式模型训练过程中——例如RNN、CNN这类分类模型——标注数据总是一件成本高昂的事情,但与此同时却又存在着海量的非标注数据却无法有效利用。从BERT模型的预训练过程我们知道,如果能通过合理的预训练任务使用无标签数据来训练一个通用的预训练模型,然后分别在每个特定的下游任务中进行有监督微调将会有效改善标注数据不足的问题。
基于这样的动机,2018年6月OpenAI团队拉德福德(Radford)[1]等人以Transformer中解码器为基础提出了一种通过自然语言生成方式来进行建模的预训练语言模型(Generative Pretrained Transformer, GPT),而这也是第1代GPT模型,下称GPT-1。GPT-1模型的核心思想在于它首先使用生成式任务在大规模未标记的文本语料上进行预训练,使模型学习到通用的结构、语法、语义等信息;然后在下游任务上通过有监督的方式进行参数微调以实现模型的迁移运用,并且通过特定的输入方式实现了模型结构调整的最小化。这里需要注意的一点是,GPT-1模型的提出时间要早于BERT模型。最后,实验表明GPT-1在12个任务场景中有9个任务的结果超越了传统完全以有监督方式训练的网络模型。
10.13.2 GPT-1结构#
1. 预训练阶段
类似于BERT网络模型,GPT-1模型也分为预训练和微调两个部分,不同的地方在于GPT-1模型是以Transformer中的解码器为基础构建得到的标准语言模型,即在模型预训练过程中通过以前$k$个字符来预测第$k+1$个字符的方式来训练模型。具体地,假设给定语料$\mathcal{U}=\{u_1,...,u_n\}$,则模型将最大化如下目标函数
$$ L_1(\mathcal{U})=\sum_{i=k+1}^n\log P(u_i|u_{i-k},u_{i-k+1},...,u_{i-1};\Theta) \tag{10-12} $$其中$k$表示预训练任务中构建样本时的窗口大小,$\Theta$表示模型参数,这里相加是因为取$\log$后的缘故。
同时,整个模型的前向传播计算过程为
$$ \begin{aligned} h_0&=UW_e+W_p\\[1ex] h_l&=\text{transformer\_block}(h_{l-1}), \forall\;l\in[1,L]\\[1ex] P(u)&=\text{softmax}(h_L,W^T_e) \end{aligned}\tag{10-13} $$其中$U$为输入文本序列对应的词表索引形状为[src_len, batch_size],$W_e$为字符嵌入层对应的权重参数形状为[vocab_size, hidden_size],$W_p$为位置编码层对应的权重参数形状为[max_position_embeddings, hidden_size],$L$表示解码器的层数,$h_l$为解码器第$l$层的输出结果形状为[tgt_len, batch_size, hidden_size],$h_L$为最后一层的输出结果,而$P(u)$则是对应每个时刻预测结果的概率分布。这里需要注意的是此处的位置编码同样是可训练的模型参数,而非原始Transformer中的公式变换。
最后,在大规模语料上根据上述过程利用梯度下降算法便可以训练得到对应的预训练模型。
2. 微调阶段
在预训练阶段结束以后,我们便可以通过如下过程来针对特定任务场景进行模型参数的微调。现假设某下游任务的输入序列为$x^1,x^2,...,x^m$,对应标签为集合$\mathcal{C}$,则需最大化如下目标函数
$$ \begin{aligned} &P(y|x^1,x^2,...,x^m)=\text{softmax}(h^m_L,W_y)\\[1ex] &L_2(\mathcal{C})=\sum_{(x,y)}\log P(y|x^1,x^2,...,x^m)\\[1ex] &L_3(\mathcal{C})=L_2(\mathcal{C})+\lambda*L_1(\mathcal{C}) \end{aligned}\tag{10-14} $$其中$h^m_L$表示第$L$层最后一个位置的输出结果,$W_y$为最后分类层对应的权重参数,$\lambda$为平衡目标函数$L_1$和$L_2$的一个超参数。之所以这样构造目标函数一是为了提高模型的泛化性,二是为了加速模型的收敛速度。
同时,在传统的深度学习模型中对于不同的下游任务场景均需要修改网络结构以满足不同形式的输入。GPT-1为了解决这一问题采用了一种统一的输入形式,即将所有待输入部分以特殊字符进行分割构造成一个序列作为模型的输入,并且整个序列的首尾以<s>和<e>进行标识
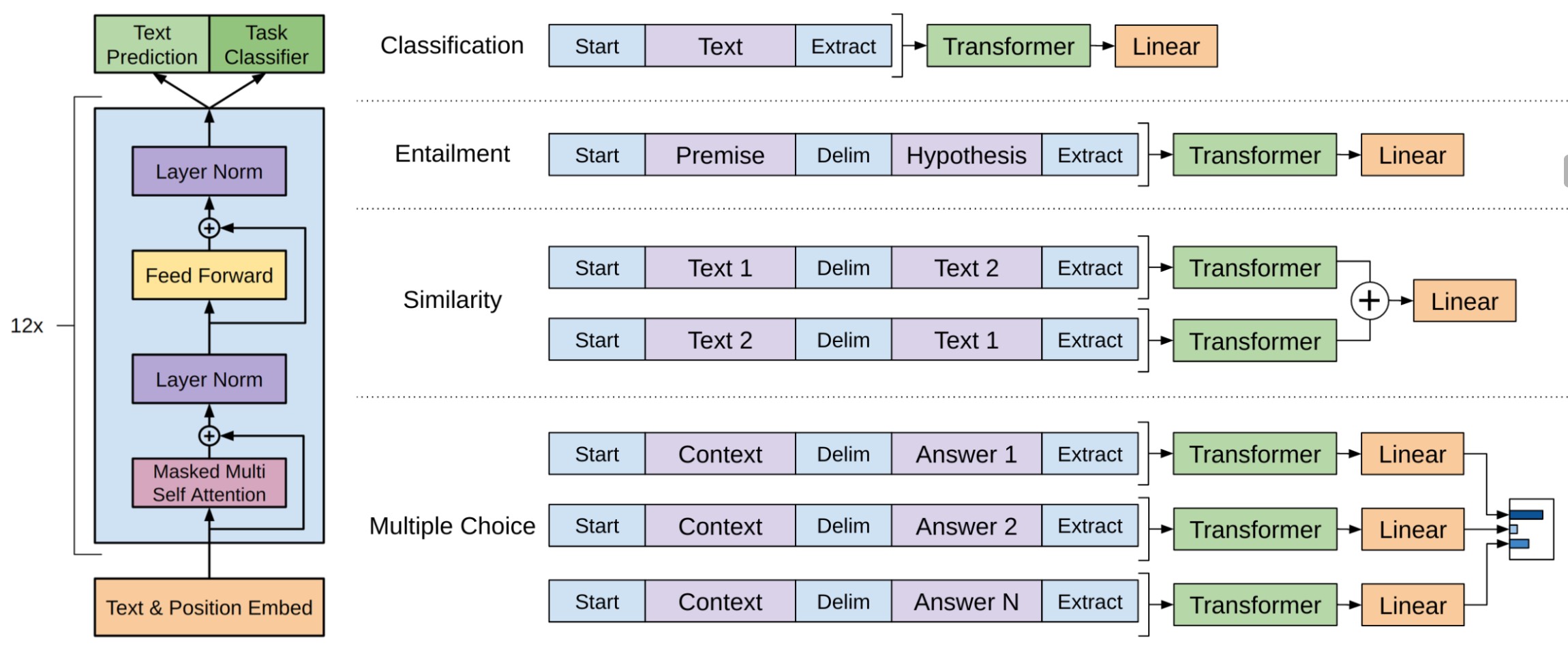
如图10-41所示为4种常见下游任务场景的输入构建方式。对于文本分类任务来说可以直接取最后一个时刻的生成结果进行分类即可;对于文本蕴含任务来说可以将描述和假设拼接成一个序列,并且两者之间用特殊分隔符标识,然后再将其输入到GPT-1模型中进行特征提取并取最后一个时刻的生成结果进行分类;对于相似性比较任务来说可以分别以不同的顺序将两个序列拼接到一起,且两者中间同样用分隔符标识,然后分别将两者经GPT-1特征提取后的向量按位相加进行分类即可;对于问题选择任务来说分别将上下文与不同的选项构造形成一个序列,并且上下文与选项之间同样以特殊分隔符标识,然后分别通过GPT-1进行特征提取完成分类即可,细节可以参考10.10节内容。可以看出BERT模型中在构造不同下游任务的输入时也参考借鉴了GPT-1的处理方式。
同时,对于问题回答和阅读理解这类任务来说,给定上下文$z$,问题$q$以及一系列答案选项$\{a_k\}$,我们只需要将它们拼接在一起中间用特殊分隔符标识,即$[z;q;a_k]$,然后输入到模型中进行分类。
10.13.3 GPT-1实现#
在介绍完GPT-1的相关原理后我们再来看如何借助PyTorch从零实现一个简单版GPT-1模型。从整体上来看GPT-1模型是基于Transformer解码器的多层网络结构,同时由于没有了与编码器交互的部所以此时解码器中将只有一个带掩码的多头注意力机制模块。基于10.3节内容中已经实现的多头注意力机制,我们下面先实现GPT-1中的解码器。本节内容完整示例代码可参见Code/Chapter10/C05_ToyGPT文件。
1. 解码器实现
同10.4节内容中实现Transformer解码器逻辑一样,此处解码器我们同样通过MyTransformerDecoder和MyTransformerDecoderLayer这两个模块来构建。首先,对于MyTransformerDecoderLayer模块来说其实现过程如下所示:
1 class MyTransformerDecoderLayer(nn.Module):
2 def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
3 super(MyTransformerDecoderLayer, self).__init__()
4 self.self_attn = MyMultiheadAttention(d_model, nhead, dropout)
5 self.linear1 = nn.Linear(d_model, dim_feedforward)
6 self.linear2 = nn.Linear(dim_feedforward, d_model)
7 self.norm1 = nn.LayerNorm(d_model)
8 self.norm2 = nn.LayerNorm(d_model)
9 self.dropout1 = nn.Dropout(dropout)
10 self.dropout2 = nn.Dropout(dropout)
11 self.dropout3 = nn.Dropout(dropout)
12 self.activation = nn.ReLU()
13
14 def forward(self, tgt, tgt_mask=None, key_padding_mask=None):
15 tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
16 key_padding_mask=key_padding_mask)[0]
17 tgt = self.norm1(tgt + self.dropout1(tgt2))
18 tgt2 = self.activation(self.linear1(tgt))
19 tgt2 = self.linear2(self.dropout2(tgt2))
20 return self.norm2(tgt + self.dropout3(tgt2))