5.2 Tensorboard可视化#
在网络模型的训练过程中一般都需要通过观察模型损失值或准确率的变化趋势来确定模型的优化方向,例如学习率的动态调整、惩罚项系数等等。同时,对于图像处理方向来说可能还希望能够可视化模型的特征图或者是样本分类类别在空间中的分布情况等。虽然这些结果也可以在网络训练结果后取对应的变量通过matplotlib进行可视化,但是我们更希望在模型训练过程中就能对其各种状态进行可视化。
因此,对于上述需求我们可以借助谷歌开源的Tensorboard工具来进行实现。在接下来的这节内容中我们将会详细介绍如何在PyTorch中通过Tensorboard来对各类变量及指标进行可视化。
5.2.1 安装与启动#
如果需要在PyTorch中使用Tensorboard除了需要安装Tensorboard工具本身之外,还需要安装的便是TensorFlow本身。因为Tensorboard中的部分可视化功能在使用中会依赖于TensorFlow框架,例如 add_embedding()函数。
对于TensorFlow和Tensorboard的安装,我们只需要执行安装TensorFlow的命令便可以同时完成两者的安装:
1 pip install tensorflow同时,由于只是借助于Tensorboard来进行可视化,因此在安装TensorFlow的时候不用区分是GPU还是CPU版本两者都可以,也就是说假如某台主机上装了GPU版本的PyTorch,而不管你是装的GPU版本还是CPU版的TensorFlow,Tensorboard都可以正常使用。
在安装成功之后通过可以通过如下命令来进行测试:
1 tensorboard --logdir=runs并会出现如下提示:
1 TensorBoard 1.15.0 at http://localhost:6006/ (Press CTRL+C to quit)此时便可以通过http://127.0.0.1:6006这个链接来访问Tensorboard的可视化页面,如图5-1所示。
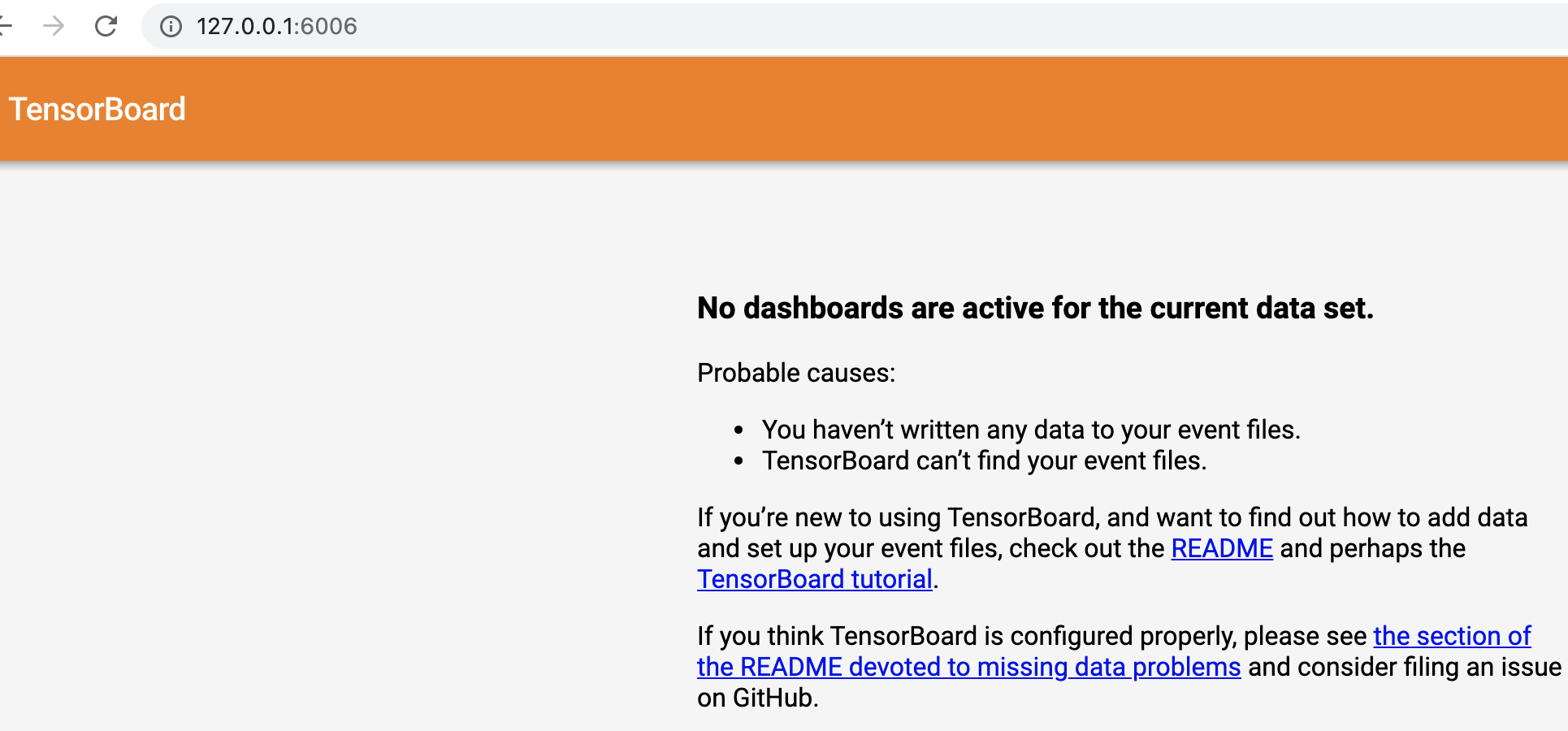
如果发现打不开这个地址,可以尝试通过如下命令来进行启动,然后再通过http://127.0.0.1:6006这个链接来访问。
1 tensorboard --logdir=runs --host 0.0.0.0其中--logdir用来指定可视化文件的目录地址,后续我们会详细介绍。
5.2.2 连接与访问#
上面我们介绍了如何在本地安装与启动Tensoboard,而更常见的一种场景便是在远程主机上运行代码但需要在本地电脑上查看可视化运行结果。如果需要实现这种目的通常来说有两种方法,下面我们分别进行介绍。
1. IP直接访问
在通过IP直接访问的方案中,不管是在类似于腾讯云或阿里云上租用的主机还是实验室的专用主机,在完成Tensoboard安装并启动后在自己电脑上都可以通过地址http://IP:6006来进行访问。但需要注意的是,上面的IP对于公网主机(如腾讯云)来说指的是主机的公网IP,对于实验室或学校的主机来说指的则是局域网的内网IP。同时,如果在远程主机上启动Tensoboard后发现在本地并不能够打开,那么可以通过如下方式来进行排查:
(1) 公网主机
-
在后台的安全策略里面查看一下
6006这个端口有没有被打开,如果没有则需要打开; -
查看IP是否为公网IP,在主机的后台管理页面可以看到。
(2) 局域网主机
-
查看本地电脑是否和主机处于同一网段;
-
查看主机的6006端口是否打开,如果没有可以参考如下命令打开
1 firewall-cmd --zone=public --list-ports # 查看已开放端口 2 firewall-cmd --zone=public --add-port=6006/tcp --permanent #开放6006端口 3 firewall-cmd --zone=public --remove-port=6006/tcp --permanent #关闭6006端口 4 firewall-cmd --reload # 配置立即生效
2. 端口转发访问
当然,除了通过IP直接访问外还可以借助SSH反向隧道技术来进行访问。例如服务器只开了22端口而且你没有权限打开其它端口的情况。在这种情况下可以通过下面两种方式来进行远程连接:
(1) 命令行终端
如果你的命令行终端支持SSH命令(例如较新的Windows10 的CMD或者Linux等)的话,可以直接通过下面这一条命令来进行连接:
1 ssh -L 16006:127.0.0.1:6006 username@ip这条命令的含义就是将服务器上6006端口的信息通过SSH转发到本地的16006端口,其中16006是本地的任意端口(无限制),只要不和本地应用有冲突就行,后面则是对应的用户名和IP。
上述命令连接成功并在远程主机上启动Tensorboard后,在本地通过浏览器打开地址http://127.0.0.1:16006即可访问。
(2) Xshell工具
如果你的电脑终端不支持SSH命令那么还可以通过Xshell工具来实现SSH反向代理访问。首先需要安装好Xshell工具,然后在安装完成后按照如下步骤进行配置。
第一步:新建连接
如图5-2所示,点击新建连接。
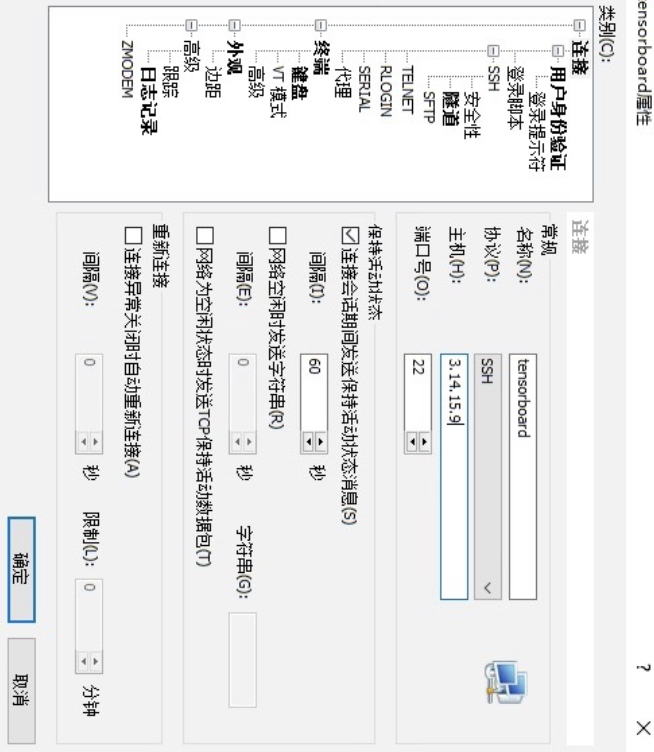
然后再根据图5-3所示的界面配置主机信息。
第二步:配置代理
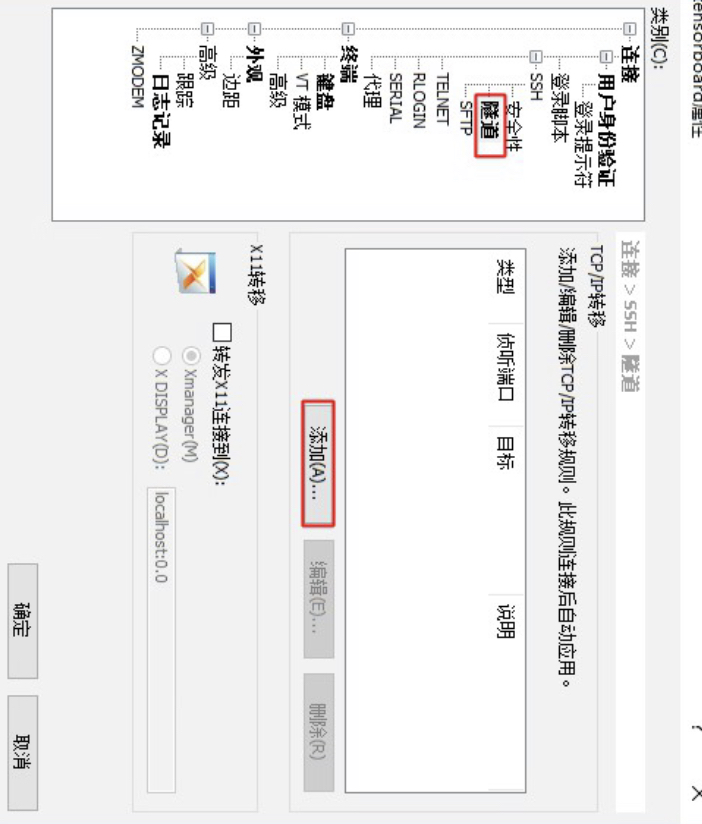
进一步,如图5-4所示点击侧边栏的隧道,并点击右侧的添加按钮。
接着再根据图5-5所示的示例进行端口代理配置。
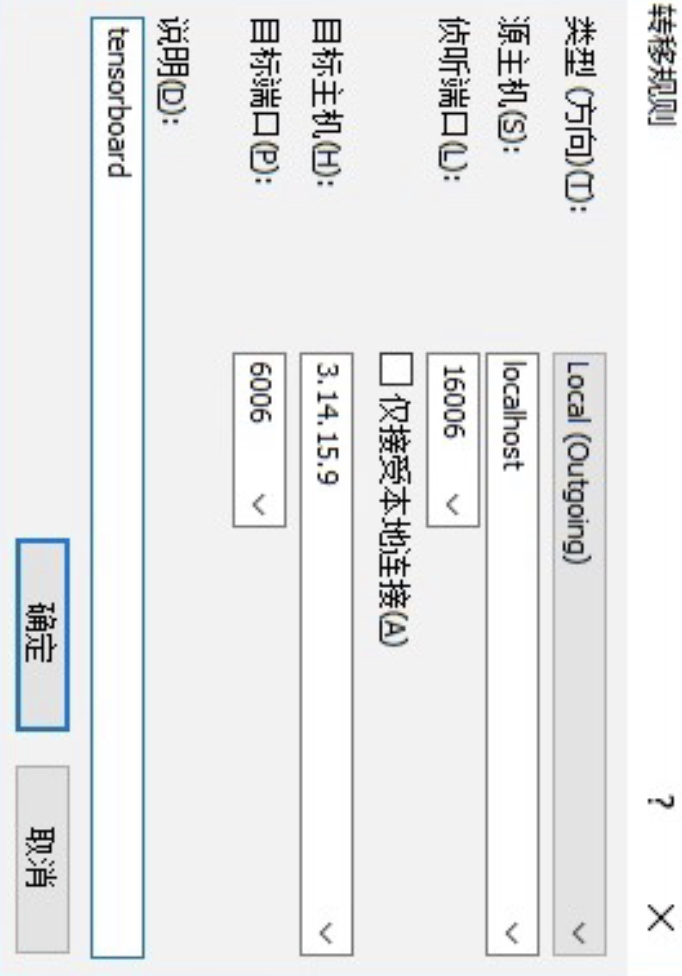
配置完成后点击图5-6中的确认即可。
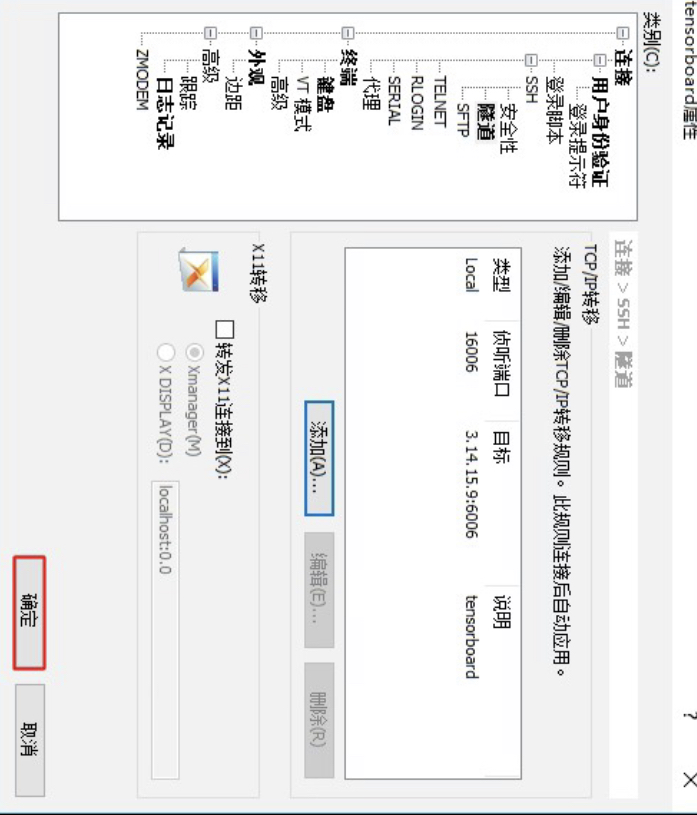
完成上述两步配置之后,再双击刚刚这个新建的连接输入用户名和密码之后即可登录到主机并对相应的端口进行了监听与转发。最后同样只需要先在当前远程主机上启动Tensorboard,然后在本地浏览器中通过地址http://127.0.0.1:16006即可访问。
5.2.3 Tensoboard使用场景#
在完成Tensorboard的安装和调试后,下面我们将逐一通过实际示例来介绍如何使用Tensorboard提供的不同可视化模块。下面先通过一个简单的标量可视化示例来完整介绍Tensoboard的使用方法。
1. add_scalar方法
这个方法通常用来可视化网络训练时的各类标量参数,例如损失、学习率和准确率等。如下便是add_scalar方法的使用示例:
1 from torch.utils.tensorboard import SummaryWriter
2 if __name__ == '__main__':
3 writer = SummaryWriter(log_dir="runs/result_1", flush_secs=120)
4 for n_iter in range(100):
5 writer.add_scalar(tag='Loss/train',
6 scalar_value=np.random.random(),
7 global_step=n_iter)
8 writer.add_scalar('Loss/test', np.random.random(), n_iter)
9 writer.close()在上述代码中,第1行用来导入相关的可视化模块。第3行是实例化一个可视化类对象,log_dir用于指定可视化数据的保存路径,flush_secs表示指定多少秒将数据写入到本地一次(默认为120秒)。第5~7行则是利用add_scalar方法来对相关标量进行可视化,其中tag表示对应的标签信息。
在上述代码运行之前,先进入到该代码文件所在的目录,然后运行如下命令来启动Tensoboard:
1 tensorboard --logdir=runs
2
3 TensorBoard 1.15.0 at http://localhost:6006/ (Press CTRL+C to quit)可以看出,logdir后面的参数就是上面代码第3行里的参数。同时,根据提示在浏览器中打开上述链接便可以看到如图5-1所示的界面。在运行上述程序后便会在当前目录中生成如图5-7所示的文件(夹),其中result_1便是前面所指定的子目录,而以events.out开始的文件则是生成的可视化数据文件。
当程序运行时Tensoboard便会加载图5-7中所示的文件并在网页端进行渲染,如图5-8所示。
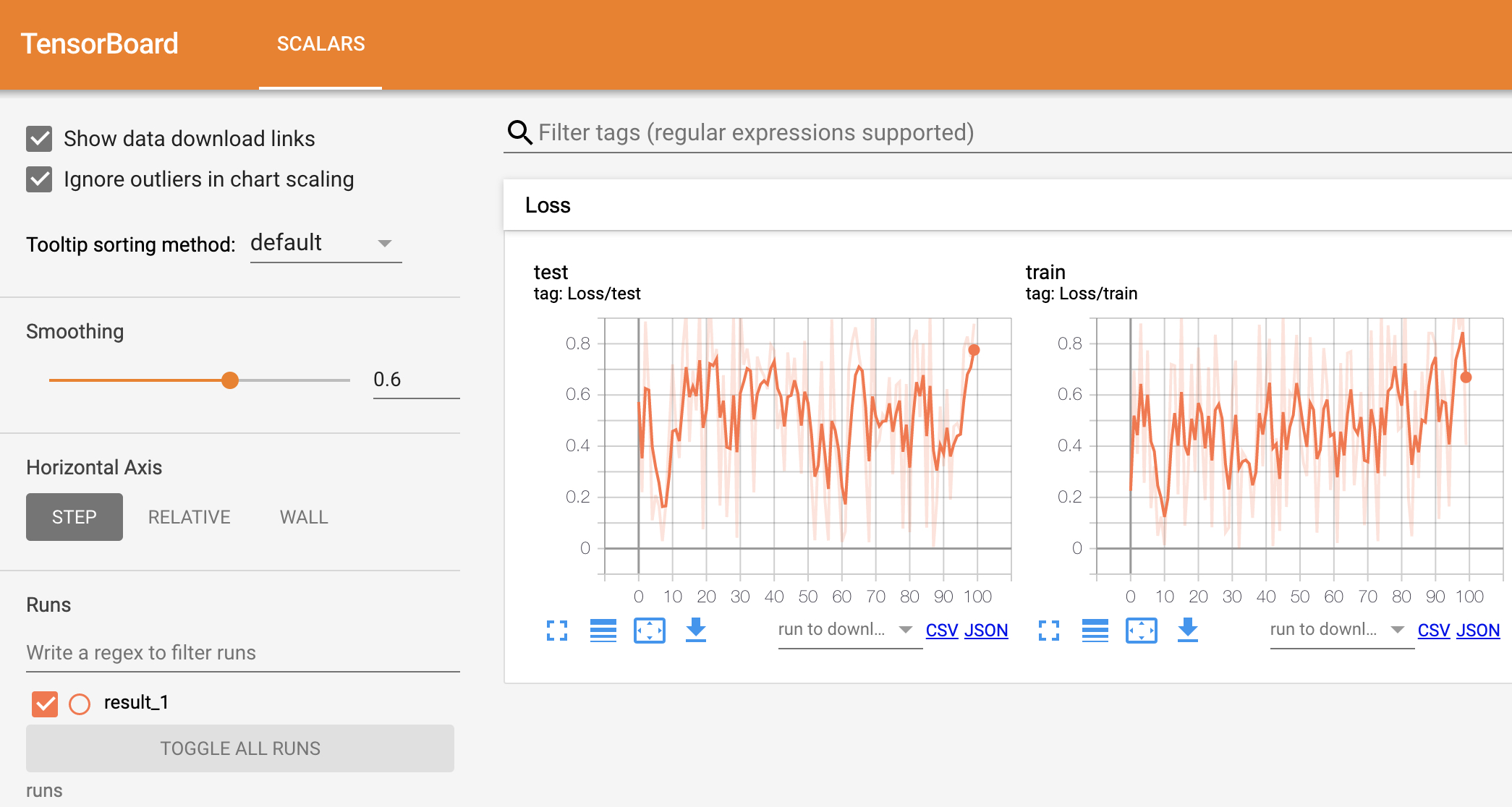
如图5-8所示为Tensoboard的可视化结果图,其中右边的Loss标签就是上面第5行代码中指定Loss/train参数的前缀部分,也就是说如果想把若干个图放到一个标签下,那么就要保持其前缀一致。例如这里的Loss/train和Loss/test这两个图都将被放在Loss这个标签下。同时,在勾选左上角的"Show data download links"后,还能点击图片下方的按钮来分别下载SVG矢量图、原始图片的CSV或JSON数据。
在图5-8的左边部分,Smoothing参数用来调整右侧可视化结果的平滑度,Horizontal Axis用来切换不同的显示模式,Runs下面用来勾选需要可视化的结果。例如后续在初始化SummaryWriter()时指定log_dir="runs/result_2",那么在result_1下方便会再出现一个result_2的选项,这时我们可以选择多个结果同时可视化展示。
2. add_graph方法
从名字可以看出add_graph方法是用于可视化模型的网络结构图,其用法示例如下:
1 import torchvision
2 def add_graph(writer):
3 img = torch.rand([1, 3, 64, 64], dtype=torch.float32)
4 model = torchvision.models.AlexNet(num_classes=10)
5 writer.add_graph(model, input_to_model=img) # 类似于TensorFlow 1.x 中的fed为了示例简洁,我们这里又把SummaryWriter()中的add_graph()方法写成了一个函数。在上述代码中,第4行用于返回一个网络模型。第5行则是对网络结构图进行可视化,其中input_to_model参数为模型所接收的输入,这类似于TensorFlow中的fed_dict参数。
上述代码运行完成后,便可以在网页端看到如图5-9所示的可视化结果。
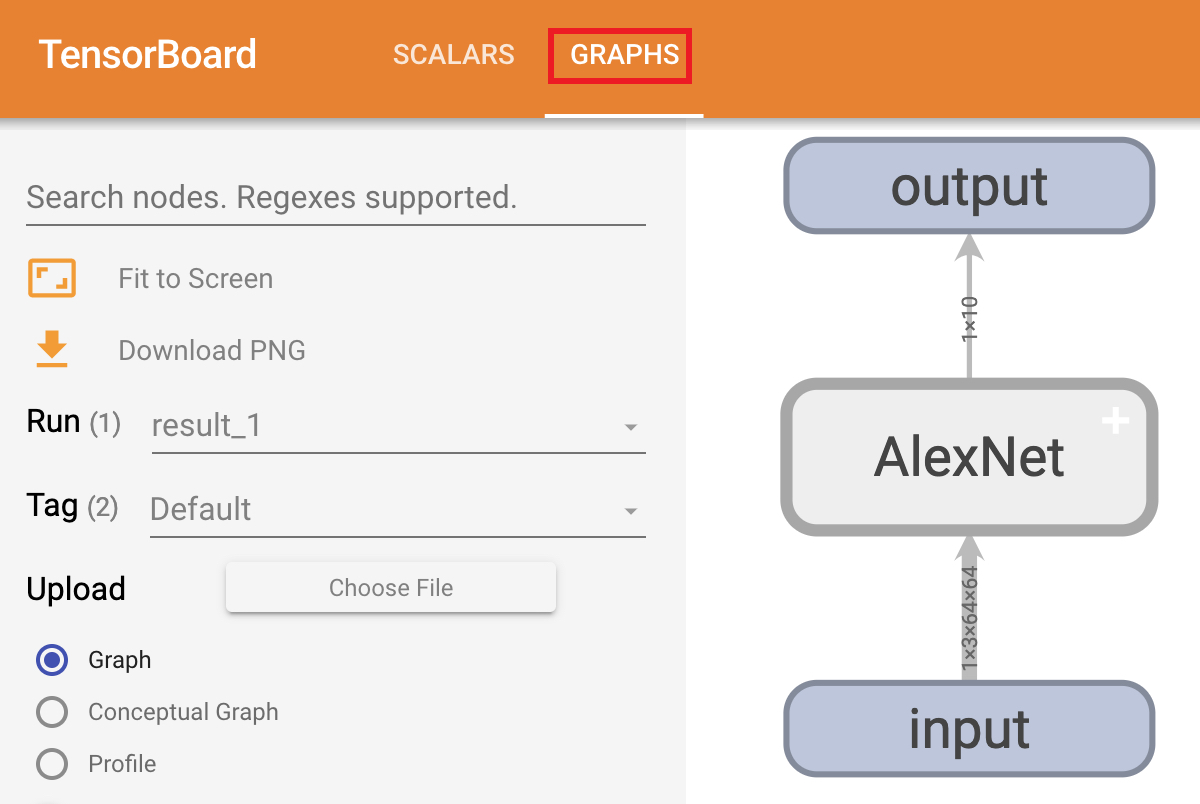
如图5-9所示便是可视化后的网络结构图,对于右侧网络结构中的每个模块都可以双击进行展开,而左边则是相关模式的切换。
3. add_scalars方法
这个方法与add_scalar的差别在于add_scalars在一张图中可以绘制多个曲线,我们只需要以字典的形式传入参数即可,如下为add_scalars方法的使用示例。
1 def add_scalars(writer):
2 r = 5
3 for i in range(100):
4 scalar_dict = {'xsinx': i * np.sin(i / r), 'xcosx': i * np.cos(i / r)}
5 writer.add_scalars(main_tag='scalars1/P1',
6 tag_scalar_dict=scalar_dict, global_step=i)
7 writer.add_scalars('scalars1/P2', {'xsinx': i * np.sin(i / (2 * r)),
8 'xcosx': i * np.cos(i / (2 * r))}, i)
9 writer.add_scalars('scalars2/Q1', {'xsinx': i * np.sin((2 * i) / r),
10 'xcosx': i * np.cos((2 * i) / r)}, i)
11 writer.add_scalars('scalars2/Q2', {'xsinx': i * np.sin(i / (0.5 * r)),
12 'xcosx': i * np.cos(i / (0.5 * r))}, i)在上述代码中我们一共画了4个图,分别对应代码中的4个add_scalars;同时在每张图里面都都对应了2条曲线,也即add_scalars方法里的tag_scalar_dict参数,并且我们这里一共用了2个标签来进行分隔,即scalars1和scalars2。最后可视化的结果如图5-10所示。
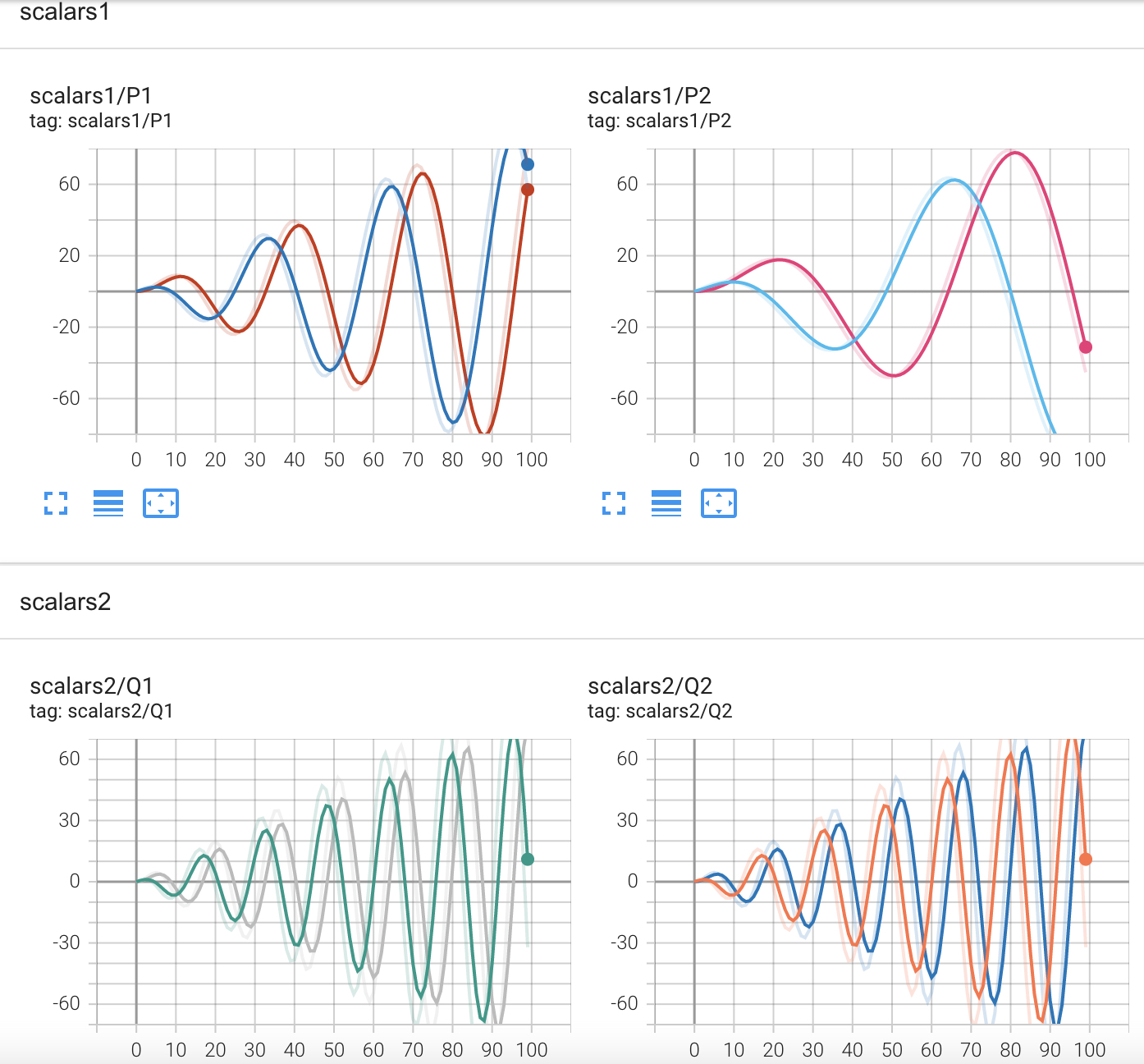
4. add_histogram方法
直方图的示例用法比较简单, 示例代码如下所示:
1 def add_histogram(writer):
2 for i in range(10):
3 x = np.random.random(1000)
4 writer.add_histogram('distribution centers/p1', x + i, i)
5 writer.add_histogram('distribution centers/p2', x + i * 2, i)上述代码运行结束后可视化结果如图5-11所示。
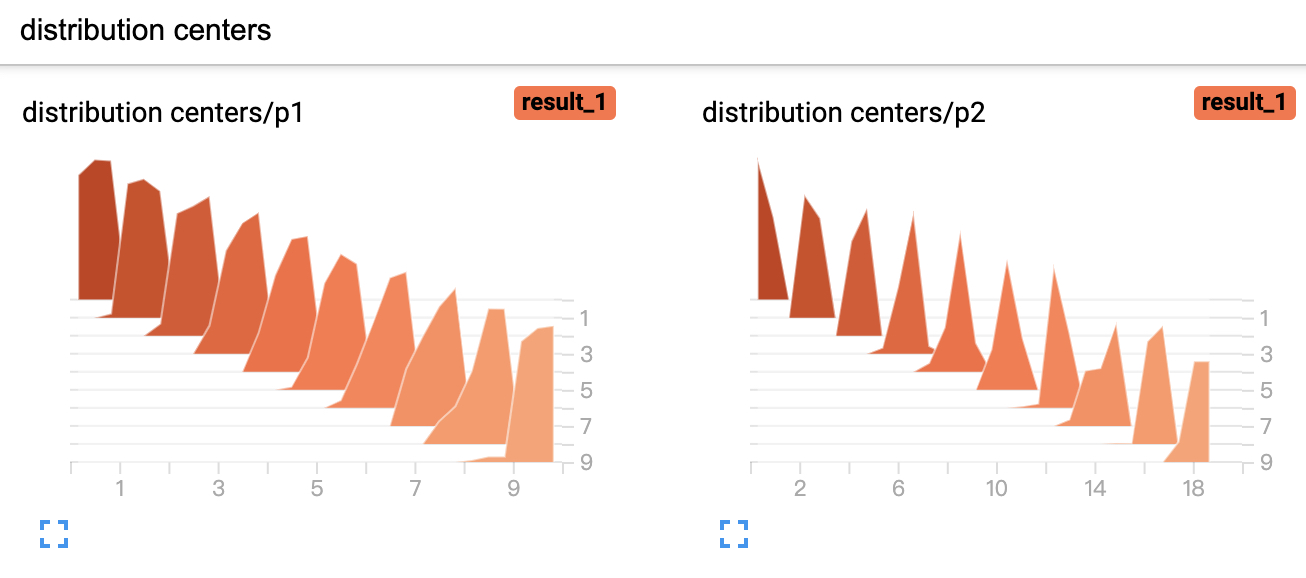
5. add_image方法
add_image方法是用来可视化相应的像素矩阵,例如本地图片或者是网络中的特征图等,示例代码如下所示:
1 def add_image(writer):
2 from PIL import Image
3 img1 = np.random.randn(1, 100, 100)
4 writer.add_image('img/imag1', img1)
5 img2 = np.random.randn(100, 100, 3)
6 writer.add_image('img/imag2', img2, dataformats='HWC')
7 img = Image.open('./dufu.png')
8 img_array = np.array(img)
9 writer.add_image(tag='local/dufu', img_tensor=img_array, dataformats='HWC')在上述代码中,第3~4行用于生成一个形状为[C,H,W]的3维矩阵并进行可视化。第5-~6行则是生成形状为[H,W,C]的3维矩阵并可视化,同时需要在add_image中指定矩阵的维度信息,因此可以看出add_image方法接受的默认格式为[C,H,W]。第7~9行则是先从本地读取一张图片,然后再对其进行可视化。最后,可视化的结果如图5-12所示。
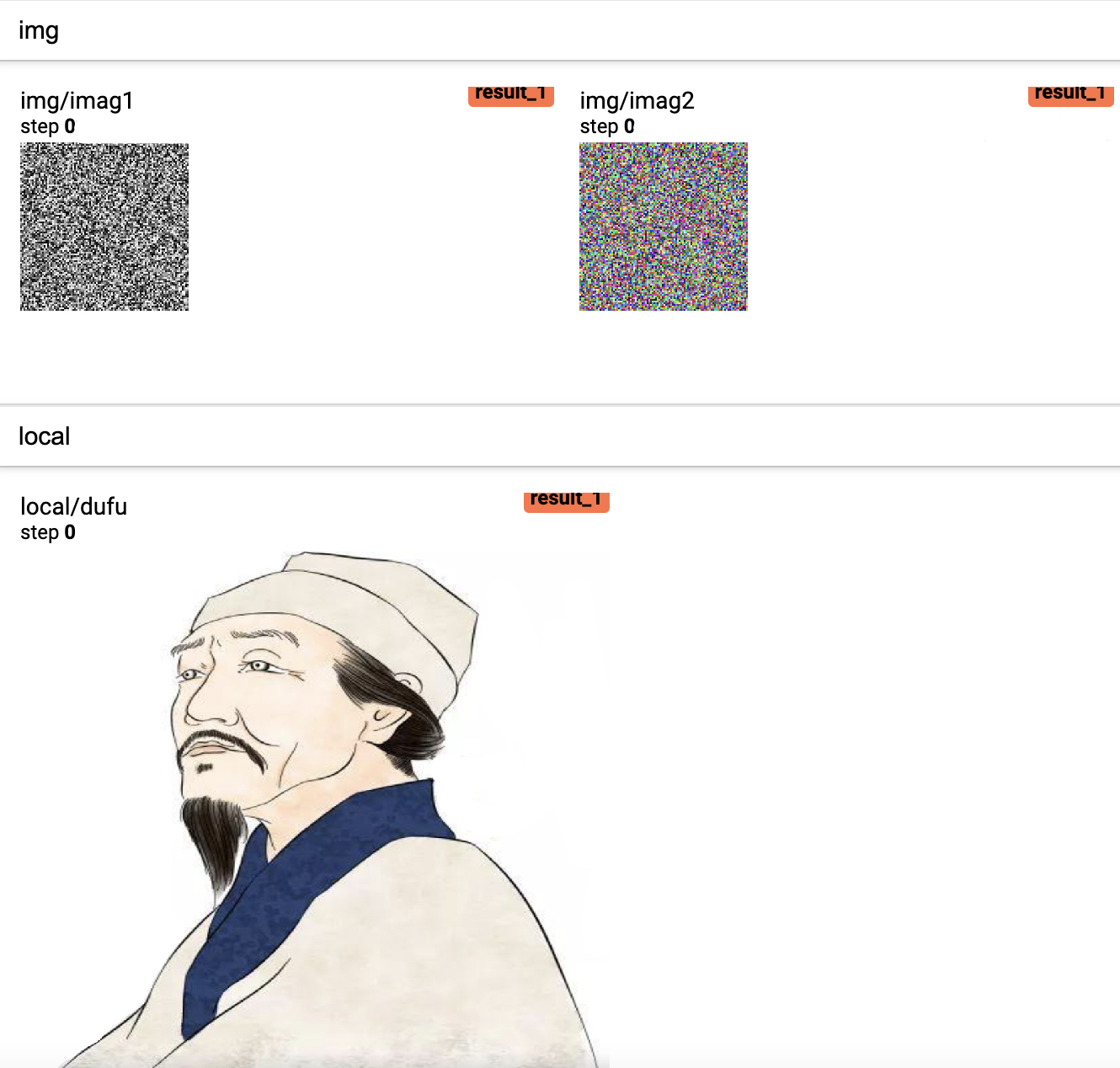
6 add_images方法
从名字可以看出,该方法是一次性可视化多张像素图,示例代码如下所示:
1 def add_images(writer):
2 img1 = np.random.randn(8, 100, 100, 1)
3 writer.add_images('imgs/imags1', img1, dataformats='NHWC')
4 img2 = np.zeros((16, 3, 100, 100))
5 for i in range(16):
6 img2[i, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 / 16 * i
7 img2[i, 1] = (1 - np.arange(0, 10000).reshape(100, 100) / 10000) / 16 * i
8 writer.add_images('imgs/imags2', img2) # Default is :math:`(N, 3, H, W)`在上述代码中,第2-3行用于生成8张通道数为1的像素图并进行可视化。第4-8行则是生成16张通道数为3的像素图并进行可视化。最后可视化的结果如图5-13所示。

7. add_figure方法
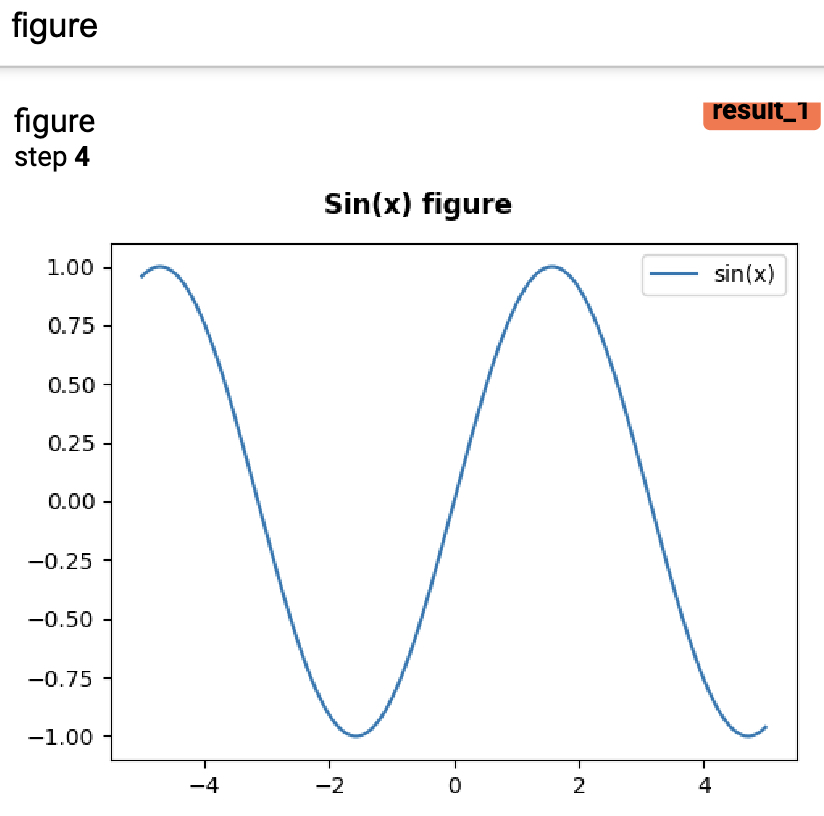
这个方法的作用是用来将matplotlib包中的figure对象可视化到Tensoboard的网页端,用于展示一些较为复杂的图片,其示例用法如下所示:
1 def add_figure(writer):
2 fig = plt.figure(figsize=(5, 4))
3 ax = fig.add_axes([0.12, 0.1, 0.85, 0.8])
4 xx = np.arange(-5, 5, 0.01)
5 ax.plot(xx, np.sin(xx), label="sin(x)")
6 ax.legend()
7 fig.suptitle('Sin(x) figure\n\n', fontweight="bold")
8 writer.add_figure("figure", fig, 4)在上述代码中,第2-7行为根据matplotlib包绘制相应的图像,其中第3行用来指定图片的坐标信息,分别表示[left, bottom, width, height]。第8行则是将其在Tensoboard中进行可视化。最后可视化的结果如图5-14所示。
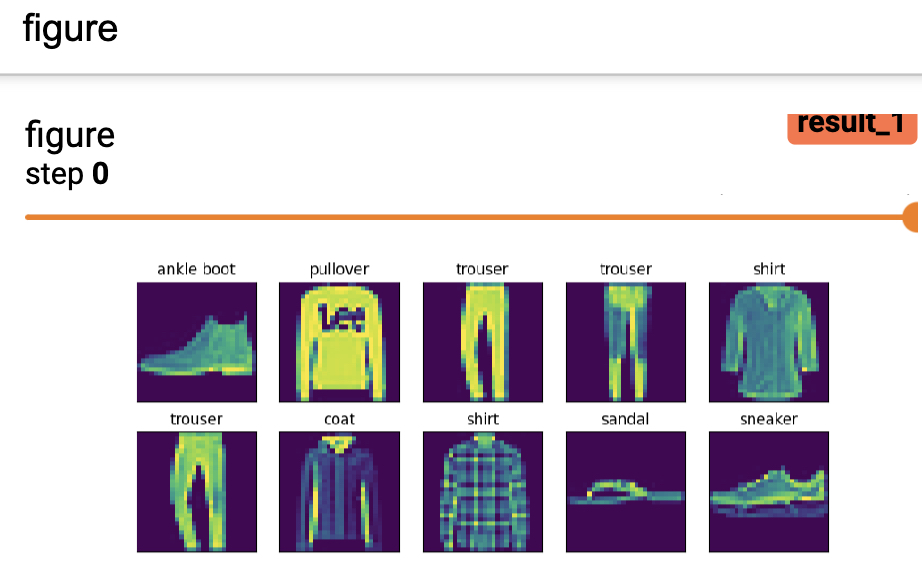
如果需要一次在Tensoboard中可视化一组图像的话,可以通过如下方式来进行实现:
1 def add_figures(writer, images, labels):
2 text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
3 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
4 labels = [text_labels[int(i)] for i in labels]
5 fit, ax = plt.subplots(len(images) // 5, 5,
6 figsize=(10, 2 * len(images) // 5))
7 for i, axi in enumerate(ax.flat):
8 image, label = images[i].reshape([28, 28]).numpy(), labels[i]
9 axi.imshow(image)
10 axi.set_title(label)
11 axi.set(xticks=[], yticks=[])
12 writer.add_figure("figures", fit)在上述代码中,我们选择是的FashionMNIST数据集进行的可视化。第5~6行代码用来生成一个包含有若干个子图的画布。第7~11行是分别用来画出每一个子图,其中第11行用来去掉横纵坐标的信息。第12行则是将其在Tensoboard中进行展示。最终可视化后的结果如图5-15所示。
8. add_embedding方法
这个方法作用是在三维空间中对高维向量进行可视化,默认情况下是对高维向量以PCA方法进行降维处理。add_embedding()方法主要有三个比较重要的参数mat、metadata和label_img,下面掌柜依次来进行介绍。
mat:用来指定可视化结果中每个点的坐标,形状为$(N, D)$,不能为空,例如对词向量可视化时mat就是词向量矩阵,图片分类时mat可以是分类层的输出结果;
metadata:用来指定每个点对应的标签信息,是一个包含$N$个元素的字符串列表,为空时则默认为['1','2',....,'N'];
label_img:用来指定每个点对应可视化信息,形状为$ (N, C, H, W)$,可以为空,例如图片分类时label_img就是每一张真实图片的可视化结果。
进一步,我们便可以通过如下代码来进行三维空间的高维向量可视化: