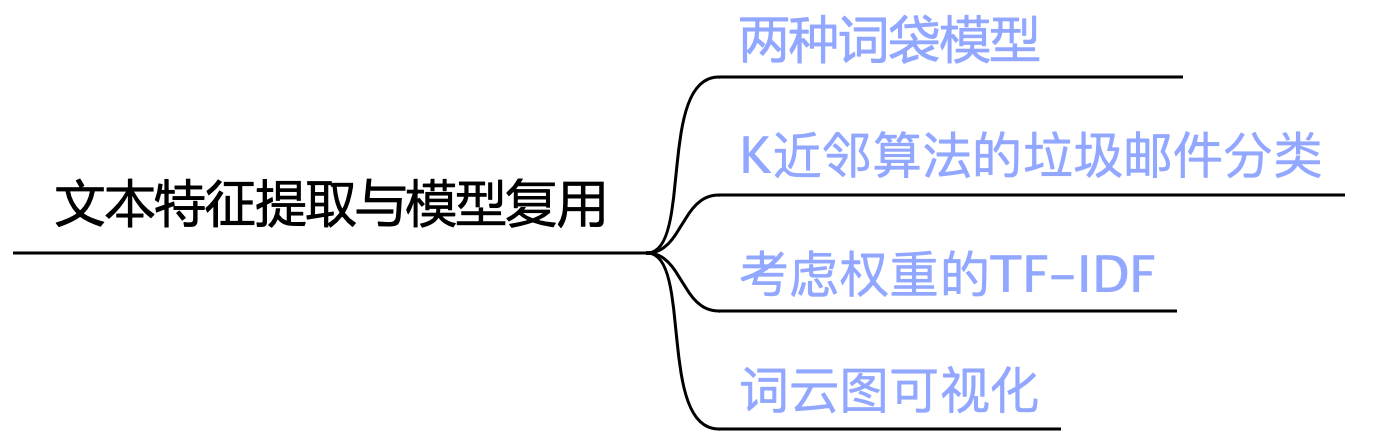
在前面几个章节的示例介绍中,我们所用到的数据集都是已经处理好的数据,换句话说这些数据集的每个特征维度都已经转换成了可用于计算的数值形式,但是在实际的建模任务中,我们获得的数据集可能并不是这样的形式。例如文本形式的这类数据是我们在实际场景中会经常遇到的。同时,对于一个训练完成的模型通常我们都需要将其进行持久化保存以便在实际预测场景中进行使用。在本章内容中,我们首先将会介绍3中常见的文本向量化方法,然后再介绍如何对训练完成的模型进行持久化保存。整个第6章的学习路线如图6-1所示。
6.1 词袋模型#
如何对文本内容进行表示是整个机器学习领域中的一个重要研究方向。例如,对于下面这样一个邮件来说,应该采用什么样的方式对其进行量化呢?同时,我们知道在建模过程中需要保证每个样本的特征维度数都一样,但是这里每一封邮件的长度却并不同,这又该怎么处理呢?接下来,我们开始介绍机器学习中的第1种文本向量化方法——词袋模型(Bag Of Words, BOW)。
“股权分置已经牵动全国股民的心,是机会?还是陷阱?如果是机会,则应该如何把握?如果是陷阱,则应该如何规避?请单击此网址索取和讯专家团针对股权分置的操作指导: http://www.spam.com/gwyqxjqxx/ ”。
6.1.1 理解词袋模型#
什么是词袋模型呢?其实词袋模型这个叫法非常形象,突出了模型的核心思想。所谓词袋模型是指,首先将训练样本中所有不重复的词放到这个袋子中构成一个有序词表(字典);然后以这个词表为标准来遍历每个样本。如果词表中对应位置的词出现在样本中,则词表对应位置就用1来表示,没有出现就用0来表示;最后,对于每个样本来讲都将其向量化成了一个和词表长度一样的只含有0和1的向量。
如图6-2所示,此示意图为一个直观的词袋模型转换示意图。左边为原始数据集(包含两个样本),中间为词表,右边为向量化的结果。

其中[1 1 0 1]的含义就是,在样本“机器学习是人工智能的子集”中有3个词出现在词表当中,分别是“机器学习”、“人工智能”和“子集”。
因此,词袋模型的处理流程可以总结为以下3步:
1. 文本分词
首先需要将原始数据的每个样本进行分词处理(英文语料可以跳过这步)。
2. 构造词表
然后在所有的分词结果中去掉重复部分,保证每个词语只出现一次,并且同时要以任意一种顺序来固定词表中每个词的位置。
3. 文本向量化
遍历每个数据样本,若词表中的词出现在该样本中,则对应位置为1,否则为0。
在图6-2中,对样本“机器学习是人工智能的子集”来讲,其中有3个词出现在词表中,所以词表中每个词的对应位置为1,而“深度学习”这个词并没有出现在样本中,所以对应位置为0。
可以看出,向量化后每个样本特征维度的长度都和词表长度相同(图6-2中为4)。虽然这样做的好处是词表包含了样本中所有出现过的词,但是却很容易导致维度灾难。因为通常一个一般大小的中文数据集,可能会出现数万个词语(而这意味着转化后向量的维度也有这么大),所以在实际处理中,在分词结束后通常还会进行词频统计这一步,即统计每个词在数据集中出现的次数,然后只选择其中出现频率最高的前K个词作为最终的词表。最后,通常也会将一些无意义的虚词,即停用词(Stop Words)去掉,例如“的”、“啊”、“了”等。
6.1.2 文本分词#
通过6.1.1节内容的介绍可以知道,向量化的第1步是需要对文本进行分词处理。下面我们将介绍一款常用的开源分词工具jieba。当然,使用jieba库的前提是先要安装,读者可以先进入对应的虚拟环境中,然后通过命令pip install jieba进行安装。
这里先用下面这段文本进行分词处理并做词频统计。
央视网消息: 当地时间11日,美国国会参议院以88票对11票的结果通过了一项动议,允许国会“在总统以国家安全为由决定征收关税时”发挥一定的限制作用。这项动议主要针对加征钢、铝关税的232调查,目前尚不具有约束力。动议的主要发起者——共和党参议员鲍勃·科克说,11日的投票只是一小步,他会继续推动进行有约束力的投票。
可以看到,这段文本中还包含了很多标点符号和数字,显然暂时不需要这些内容,所以在分词的时候可以通过正则表达式进行过滤。同时,jieba库分别提供了两种分词模式来应对不同场景下的中文分词,下面分别进行介绍。完整代码可参见AllBooKCode/Chapter06/C01_cut_words.py 文件。
1. 普通分词模式
普通分词模式指的是按照常规的分词方法,将一个句子分割成多个词语的组成形式,代码如下:
1 import jieba,re
2 def cutWords(s, cut_all=False):
3 cut_words = []
4 s = re.sub("[A-Za-z0-9\:\·\—\,\。\“ \”]", "", s)
5 seg_list = jieba.cut(s, cut_all=cut_all)
6 cut_words.append("/".join(seg_list))在上述代码中,第4行是将所有字母、数字、冒号、逗号、句号等过滤掉,第5行用来完成分词处理的过程,其中当cut_all = False时,表示普通分词模式;第6行是将所有分词后的结果以/进行分割展示。根据上述代码分词结束后便能看到以下所示的结果:
['央视网/消息/当地/时间/日/美国国会参议院/以票/对票/的/结果/通过/了/一项/动议/允许/国会/在/总统/以/国家/安全/为/由/决定/征收/关税/时/发挥/一定/的/限制/作用/这项/动议/主要/针对/加征/钢铝/关税/的/调查/目前/尚/不/具有/约束力/动议/的/主要/发起者/共和党/参议员/鲍勃/科克/说/日/的/投票/只是/一/小步/他会/继续/推动/进行/有/约束力/的/投票']但是,对于有的句子来讲可以有不同的分词方法,例如“美国国会参议院”这段描述,既可以分成“美国/国会/参议院”,也可以分成“美国国会/参议院”,甚至可以直接分成“美国国会参议院”,不同的人可能有不同的切分方式,因此,jieba还提供了另外一种全分词模式。
2. 全分词模式
当把上面代码中的cut_all设置为True后,便可以开启全分词模式,分词后的结果如下:
['央视/央视网/视网/消息/当地/时间/日/美国/美国国会/美国国会参议院/国会/参议/参议院/议院/以/票/对/票/的/结果/通过/了/一项/动议/允许/许国/国会/在/总统/以/国家/家安/安全/为/由/决定/征收/关税/时/发挥/一定/的/限制/制作/作用/这项/动议/主要/针对/加征/钢/铝/关税/的/调查/目前/尚不/不具/具有/约束/约束力/动议/的/主要/发起/发起者/共和/共和党/党参/参议/参议员/议员/鲍/勃/科克/说/日/的/投票/只是/一小/小步/他/会/继续/推动/进行/有/约束/约束力/的/投票']可以看出,对于有的句子,分词后的结果确实看起来结结巴巴,但这就是全分词模式的作用。在分词结束后,就可以对分词结果进行词频统计并构造词表。
6.1.3 构造词表#
上面介绍了,分词后通常还会进行词频统计,以便选取出现频率最高的前K个词来构造词表。对词频进行统计需要使用另外一个包collection中的Counter计数器(如果没有安装,则可自行安装,命令为pip install collection),但是需要注意的是,像上面那样分词后的形式并不能进行词频统计,因为Counter是将list中的一个元素视为一个词,所以要对上面的代码略微进行修改,示例代码如下:
1 def wordsCount(s):
2 cut_words = ""
3 s = re.sub("[A-Za-z0-9\:\·\—\,\。\“ \”]", "", s)
4 seg_list = jieba.cut(s, cut_all=False)
5 cut_words += (" ".join(seg_list))
6 all_words = cut_words.split()
7 c = Counter()
8 for x in all_words:
9 if len(x) > 1 and x != '\r\n':
10 c[x] += 1
11 vocab = []
12 print('\n词频统计结果:')
13 for (k, v) in c.most_common(5):
14 print("%s:%d" % (k, v))
15 vocab.append(k)
16 print("词表:", vocab)在上述代码中,第1~6行用来对文本进行分词处理,并把分词后的结果存放到一个列表中,列表中的每个元素为一个词语;第7~10行代码来完成词频统计;第12~16行是输出词频最高的前5个词。
在上述代码运行结束以后便可以得到前K(这里K=5)个词构成的词表,结果如下如式:
1 词频统计结果:
2 动议:3
3 关税:2
4 主要:2
5 约束力:2
6 投票:2
7 词表: ['动议', '关税', '主要', '约束力', '投票']6.1.4 文本向量化#
通过上面的操作,便可以得到一个最终的词表(Vocabulary)。最后一步的向量化工作则是遍历每个样本,查看词表中每个词是否出现在当前样本中。如果出现,则词表对应的维度用1表示。如果没有出现,则用0表示。完整代码可参见AllBooKCode/Chapter06/C02_vectorization.py 文件,示例代码如下:
1 def vetorization(s):
2 # #此处接文本分词和词频统计代码
3 x_vec = []
4 for item in x_text:
5 tmp = [0] * len(vocab)
6 for i, w in enumerate(vocab):
7 if w in item:
8 tmp[i] = 1
9 x_vec.append(tmp)
10 print("词表:", vocab)
11 print("文本:", x_text, x_vec)在上述代码中,第4行中x_text表示原始文本分词后的结果。第5行中tmp表示先初始化一个长度为词表长度的全0向量。第6~8行表示开始遍历每一句文本中的每个词,判断其是否存在于词表中,如果存在则将tmp向量对应处置为1。
这样,根据vetorization()函数便能够对输入的文本进行向量化表示,结果如下:
1 s=['文本分词工具可用于对文本进行分词处理','常见的用于处理文本的分词处理工具有很多']
2 vetorization(s)
3 词表: ['文本', '分词', '处理', '工具', '用于', '进行', '常见', '很多']
4 文本:[['文本','分词','工具','可','用于', '对','文本','进行', '分词', '处理'],
['常见', '的', '用于', '处理', '文本', '的', '分词', '处理', '工具', '有','很多']]
5 [[1, 1, 1, 1, 1, 1, 0, 0], [1, 1, 1, 1, 1, 0, 1, 1]]从上面的结果可以看出,这里选择了出现频率最高的前8个词来构造词表,然后得到了每个样本的向量化表示。
至此,我们就介绍完了第1种基本的文本向量化表示方法,即判断样本中每个词是否出现在词表中。如果出现,则词表对应位置就用1来表示,如果没有出现,则用0表示。最终就会得到一个仅包含0和1的向量来表示的这一样本,但是这样做的弊端之一就是没有考虑词的出现频率,即不管一个词出现了多少次,最后都仅仅用1来表示其出现过,但在一些场景下,词频又是十分重要的考量因素,因此,接下来再来看另外一种同时考虑词频的词袋表示模型。
6.1.5 考虑词频的文本向量化#
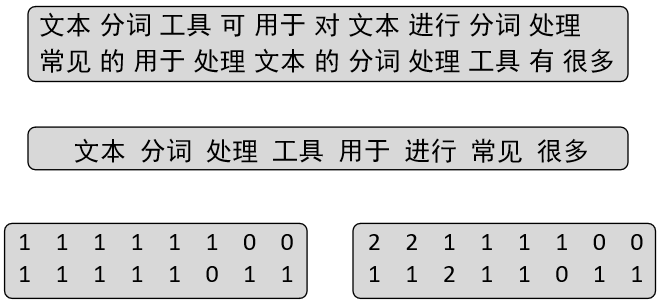
如图6-3所示,最上面为原始样本,中间为词表,最下边为两种词袋模型的表示结果。其中最下边左侧的表示方法就是我们在上面介绍的第1种文本表示方法,它只考虑词表中的单词是否出现而不关心出现频次,而最下边右侧的表示方法同时还考虑了每个词的出现频率。
因此,根据这一原理只需将6.1.4节中的代码稍做修改即可实现这一结果。完整代码可参见AllBooKCode/Chapter06/C03_vectorization_with_freq.py 文件,示例代码如下:
1 def vectorization_with_freq(s):
2 #此处接文本分词和词频统计代码
3 x_vec = []
4 for item in x_text:
5 tmp = dict(zip(vocab, [0] * len(vocab)))
6 for w in item:
7 if w in vocab:
8 tmp[w] += 1
9 x_vec.append(list(tmp.values()))
10 print("词表:", vocab)
11 print("文本:", x_text)
12 print(x_vec)在上述代码中,第5行用来初始化一个字典,其key为词表中的每个词,value的初始化值为0,表示每个词出现的次数为0。第6~8行用来遍历样本中的每个词,如果其出现在词表中,则对字典中对应词的计数值加1。最后第9行用来取字典对应的所有value值,以此作为这条文本的向量化表示。
上述代码运行结束以后便会得到如下所示结果:
1 s =['文本分词工具可用于对文本进行分词处理', '常见的用于处理文本的分词处理工具有很多']
2 vectorization_with_freq(s)
3 词表: ['文本', '分词', '处理', '工具', '用于', '进行', '常见', '很多']
4 文本: [['文本', '分词', '工具', '可', '用于', '对', '文本', '进行', '分词', '处理'],
['常见','的','用于', '处理','文本','的','分词','处理','工具','有','很多']]
5 [[2, 2, 1, 1, 1, 1, 0, 0], [1, 1, 2, 1, 1, 0, 1, 1]]这样,便得到了考虑词频的文本向量化表示。不过,其实这一方法在sklearn中已经实现了。接下来就通过sklearn中的方法再进行一次示例,完整代码可参见AllBooKCode/Chapter06/C04_bag_of_word.py文件。在sklearn中,可以通过导入CountVectorizer这一类方法完成上述步骤,示例代码如下:
1 from sklearn.feature_extraction.text import CountVectorizer
2 count_vec = CountVectorizer(max_features=8, token_pattern=r"(?u)\b\w\w+\b")
3 x = count_vec.fit_transform(s).toarray()
4 vocab = count_vec.vocabulary_
5 vocab = sorted(vocab.items(), key=lambda x: x[1])在上述代码中,第2行中的max_features=8表示取频率最高的前8个词构造词表。第4~5行代码分别用来获得词表,以及将词表按词频进行排序。
上述代码运行结束以后便能对文本进行向量化表示,结果如下所示:
1 [('分词', 0), ('处理', 1), ('工具', 2), ('常见', 3), ('很多', 4), ('文本', 5), ('用于', 6), ('进行', 7)]
2 [[2 1 1 0 0 2 1 1]
3 [1 2 1 1 1 1 1 0]]可以发现,通过CountVectorizer类得到的文本向量与上面我们自己编写的代码的输出结果存在一点差别。细心的读者可能已发现,导致这一差别的主要原因便是词表的顺序不一样。由于最后的文本向量化形式会依赖于每个词在词表中的位置顺序,所以根据不同顺序的词表最后得到的向量必定存在着不同,但这在本质上并没有什么不同,只要词表一样则两者得到的向量表示是等价的。
6.1.6 小结#
在本节中,我们首先介绍了第1种将文本转化为向量的词袋模型,接着介绍了一款常用的中文分词工具jieba库,并演示了如何通过jieba进行分词处理并进行词频统计;然后介绍了如何实现词袋模型的最后一步——向量化表示;最后还介绍了第2种词袋模型表示方法,该方法同时考虑了词语的出现频率,并且在长文本的表示中用得较多。