9.7 Seq2Seq网络#
在9.1节内容中,我们探讨了自然语言处理的核心概念,即理解与生成。其中,自然语言理解可以看作是自然语言生成的前置任务。在自然语言理解任务中,主要目标是对原始输入文本进行编码(Encode)操作,即将文本转换为特征向量表示,然再将其应用于文本分类、命名实体识别或信息抽取等场景中以完成对文本语义的理解。对于自然语言生成来说则是根据自然语言理解阶段得到的特征向量表示来完成特定场景下的自然语言文本生成任务,典型的应用包括文本摘要、语音识别、机器翻译等。此时可以看出,在这个过程中自然语言生成类似于一个解码(Decode)操作,将编码阶段得到的特征向量转换为人类可理解的文本内容。
尽管在7.6节内容中我们已经介绍了基于RNN结构的文本生成模型,但其编码和解码阶段使用的是相同的网络权重。然而,在类似翻译模型这样的场景下,这种方法是不适用的,因为翻译模型的输入和输出属于不同的语义空间,它们之间存在着显著的语言差异和词汇表的不同,因此需要采用不同的网络权重来编码和解码不同的语言特征。在本节及本章接下来的内容中,我们将会介绍另外一种新的网络架构编码器(Encoder)-解码器(Decoder),并围绕这一结构来介绍其它相关技术。
9.7.1 Seq2Seq动机#
在传统的深度神经网络中,由于输入和输出必须具有固定长度的限制,像机器翻译这样输入输出序列长度不固定的任务受到了极大的限制[1]。虽然RNN网络模型在一定程度上解决了序列长度固定的问题,但又面临着模型输入输出在同一个语义空间的限制。为了解决这一问题,我们需要考虑使用更加复杂但灵活又能同时解决上述两个问题的网络结构。
基于这样的动机,谷歌公司苏茨克维尔(Sutskever)等人于2014年提出了一种基于LSTM的序列到序列(Sequence to Sequence, Seq2Seq)神经网络机器翻译模型(Neural Machine Translation, NMT)[1],即输入和输出均为一个序列。Seq2Seq模型使用Encoder-Decoder架构来处理不同语义空间下的序列生成任务,其中编码器和解码器分别采用不同的网络权重以适应不同语义空间中的特征映射和转换。在模型训练过程中,它可以学习到输入和输出序列之间的复杂映射关系,从而实现有效的序列转换任务。
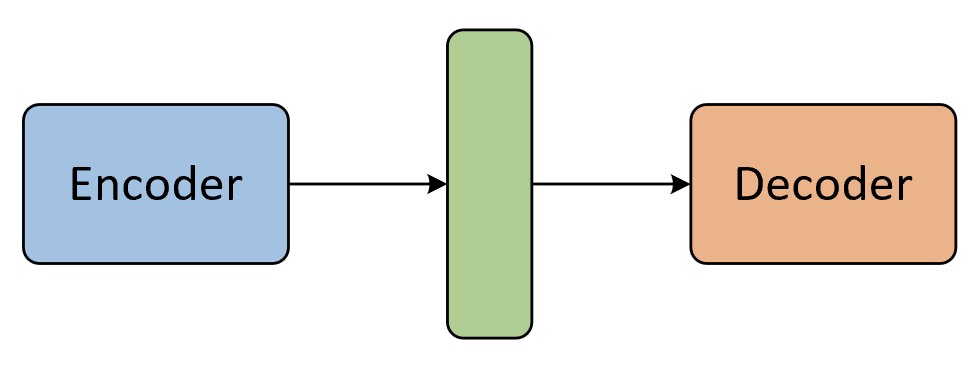
如图9-15所示便是基于Encoder-Decoder架构的Seq2Seq模型,其中编码器和解码器分别由一个LSTM网络所构成。在Seq2Seq模型中,Encoder先将一个可变长度的序列编码成一个固定维度的中间向量,然后Decoder再将这个中间向量解码成一个可变长度的目标序列。
此时我们需要明白的是,Seq2Seq其实是一类任务的总称,即根据源序列生成目标序列的场景,而Encoder-Decoder则是一种技术架构的总称。因此,对于Encoder和Decoder来说两者的网络结构并没有任何限制,可以分别采用不同的神经网络结构来满足实际的任务需求。所以在Encoder和Decoder中,除了可以是RNN、LSTM、GRU之外,也可以是之前已经介绍过的DNN、CNN和ConvLSTM等。例如对于8.6节中的流量预测任务来说,如果我们想要预测未来多个时刻的流量分布情况,那么Encoder-Decoder便可以采样ConvLSTM来进行建模。
9.7.2 Seq2Seq结构#
根据图9-15可知,Seq2Seq模型整体分为两个部分,编码器和解码器。编码器将不定长的输入序列转换为一个固定长度的上下文向量(Context Vector),然后解码器根据这个上下文向量逐步生成不定长的输出序列。如图9-16所示便是基于Seq2Seq的NMT翻译模型。
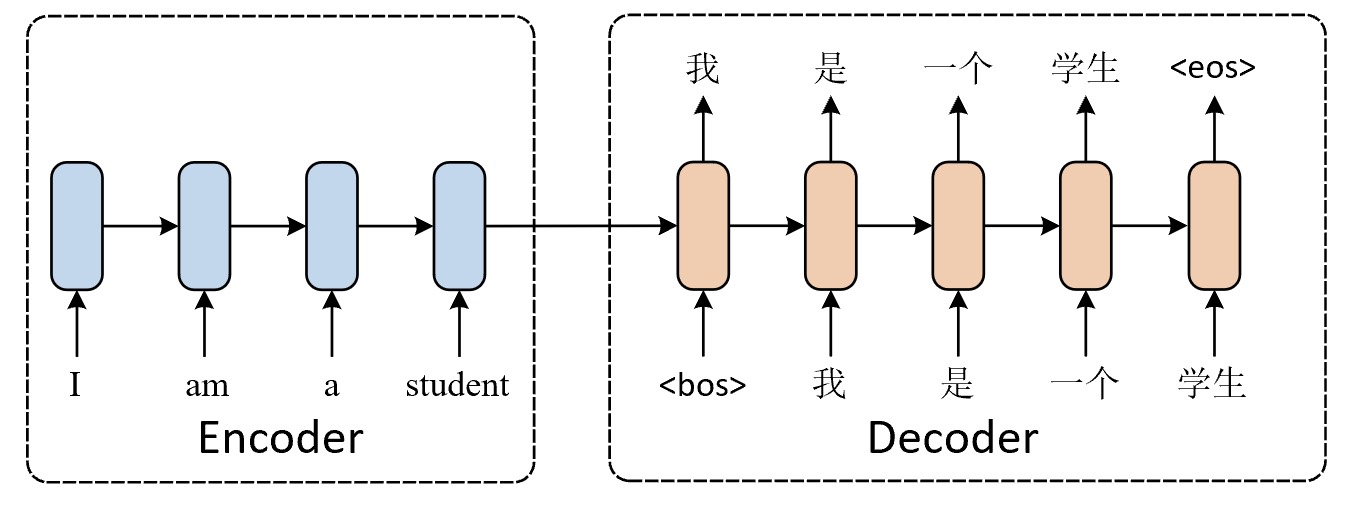
在图9-16中,左侧为编码器,论文中采用了4层LSTM来捕捉输入序列中的语义信息,然后再将编码器最后一个时间步长的隐含状态作上下文向量。右侧为解码器,同样也采用了4层LSTM结构,接收编码器产生的上下文向量作为初始隐含状态,并结合先前多个时刻的输出结果来逐步生成下一个时刻的输出概率分布,最终根据该概率分布采样生成实际的输出。可以看出,对于每个时刻的预测过程来说本质上都是一个分类任务,而分类类别数则是整个词表的大小,因此整个模型在计算损失时是以所有时刻的交叉熵损失来进行衡量。
具体地,对于图9-16˙中的示例来说,编码器接受4个时刻的输出"I am a stuednt",然后将其编码成一个固定维度的上下文向量$\mathcal{c}$,即第4个时刻对应的隐含状态。在解码器中,第1个时刻分别以上下文向量$\mathcal{c}$和<bos>作为输入,然后得到第1个时刻的预测结果“我”;第2个时刻再以上下文向量、<bos>和第1个时刻的输出作为输入来预测第2个时刻的输出,即此时将以$\mathcal{c}$、<bos>和“我”作为输入;同理,第3个时刻将以$\mathcal{c}$、<bos>、“我”和“是”作输入来预测第3个时刻的输出;以此循环,直到预测结果为<eos>或达到指定长度后停止。
这里需要注意的是,上述过程仅仅是Seq2Seq模型在推理阶段时的计算过程,对于训练过程来说在不同的场景下还会有不同的技巧。在9.9节内容中我们将以一个实际的翻译模型为例来详细介绍整个过程。同时,此处的<bos>和<eos>分别表示起始符(begin of sentence)和结束符(end of sentence)。
9.7.3 搜索策略#
根据9.7.2节内容的介绍可知,解码器在对每个时刻的输出进行预测时我们都需要选择其中一个分类类别作为当前时刻的预测值。同时,通过前面几个章节的介绍可知,对于分类任务来说通常我们可以选择概率分布中概率值最大的类标作为分类结果。但是对于序列生成任务来说,由于第$t+1$时刻的预测结果会依赖于第$t$个时刻的预测结果,因此如果在每个时刻中均选择当前概率分布中概率值最大的类标并不能保证整个生成序列的条件概率值最大[2]。
具体地,在序列生成任务中模型需要根据输入值$(x_1,...x_T)$来预测目标值$(y_1,...,y_{T^{\prime}})$,即最大化条件概率$p(y_1,...,y_{T^{\prime}}|x_1,...,x_T)$。在计算这一条件概率时,编码器首先需要根据输入值$(x_1,...x_T)$来编码得到上下文向量$\mathcal{c}$,然后再依次计算得到预测值$(y_1,...,y_{T^{\prime}})$对应的概率分布,即想要得到最优生成序列则需要最大化式(9-26)
$$ p(y_1,...,y_{T^{\prime}}|x_1,...,x_T)=\prod_{t=1}^{T^{\prime}}p(y_t|\mathcal{c},y_1,...,y_{t-1}) \tag{9-26} $$其中条件$p(y_t|\mathcal{c},y_1,...,y_{t-1})$的分布是解码时每个时刻输出的$\text{Softmax}$结果。
1. 贪婪搜索
贪婪搜索(Greedy Search)的基本原理是在解码每个时刻时,都选择概率分布中概率值最大的类标作为当前时刻的预测输出,一直持续到遇到终止符号或达到预先设定的输出序列长度时结束。虽然贪婪搜索简单高效且易于计算和实现,但是贪婪搜索也存在着一定的局限性。由于每次只考虑当前时刻的输出概率分布,并选择最大概率的输出,因此它可能无法得到全局最优的输出序列。
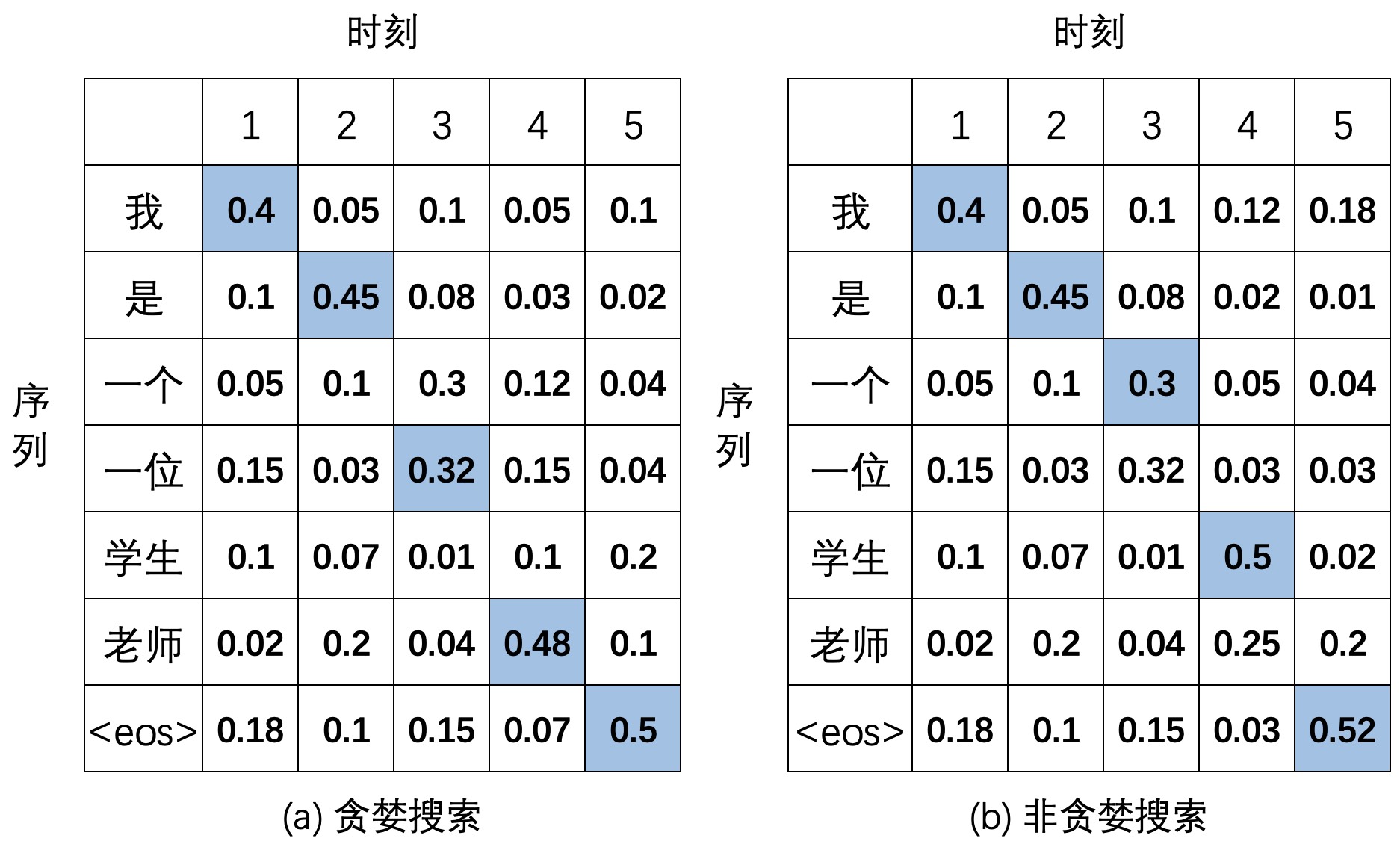
如图9-17所示是解码器在解码图9-16中输入“I am a student”时可能的两种搜索方式。对于图9-17(a)来说,解码器在每个时刻都选择了当前概率值最大结果,使得最终生成的序列“我 是 一位 老师”并不是正确的结果,此时对应的条件概率为$0.4\times0.45\times0.32\times0.48\times0.5\approx0.0138$。在图9-17(b)中,在解码第3个时刻时解码器选择了当前概率第二大的结果,并在前3个时刻输出结果的条件下依次得到后续两个时刻的输出,最终得到了最优学序列“我 是 一个 学生”,此时对应的条件概率为$0.4\times0.45\times0.3\times0.5\times0.52\approx0.0140$。通过这个例子也就说明了采用贪婪搜索并不能保证生成得到最优序列。
2. 穷举搜索
穷举搜索(Exhaustive Search),也被称为暴力搜索或完全搜索,它是一种简单而直接的搜索策略,通过枚举所有可能的发生情况来寻找问题的最优解。
在穷举搜索中,解码器在解码当前时刻时会考虑所有生成的结果,而在解码下一个时刻时又会基于上一个时刻的所有结果来生成当前时刻的结果并依旧考虑当前时刻的所有结果,以此循环直到预测结束。可以看出,穷举搜索的生成结果会随着时间步长而成指数增长,因此在复杂问题中穷举搜索将会变得非常耗时,尤其是当问题的规模很大时。例如在机器翻译或文本摘要中穷举搜索往往不可行,在这些情况下就需要使用更高级的搜索算法来寻找更优的解决方案。
3. 束搜索
束搜索(Beam Search)是一种用于在大规模的解空间中寻找近似最优解的搜索算法。与穷举搜索一次性考虑所有可能解不同,束搜索在每一个时刻中只会保留一定数量的最优候选解,称为束宽(Beam Width)或束大小(Beam Size),然后在所有候选解中选择条件概率最大的为最终输出结果。从这里可以看出,束搜索是在穷举搜索和贪婪搜索之间的一种折衷做法[4] [5]。
以图9-17中的结果为例,假设束宽$k=2$,那么对于$t$时刻的预测输出束搜索会选择概率值最大的前两个作为候选结果;然后$t+1$时刻再基于$t$时刻的两个候选结果各自得到预测输出,并在这两部分中整体再选择概率值最大的前两个作为$t+1$时刻的候选结果;最后,模型预