1.2 RAG 流程概览#
在上一节中,我们介绍了 RAG 出现的背景以及要解决的问题。我们知道,大语言模型虽然拥有强大的知识理解和生成能力,但其知识来源于预训练阶段的数据,因此无法获取用户私有数据,也无法掌握训练完成后产生的新知识。
为了解决这一问题,RAG 通过引入外部知识库,使模型能够在回答问题时动态获取相关信息,从而提升回答的准确性、时效性和可解释性。本节将从整体视角出发,介绍 RAG 的基本工作流程以及各个阶段的核心任务,帮助读者建立对 RAG 的全局认识。
1.2.1 RAG 处理流程#
从用户视角来看,RAG 的工作流程其实非常简单。当用户提出一个问题时,系统并不会直接将问题发送给大语言模型,而是首先从外部知识库中查找与问题最相关的信息,然后再将这些信息与用户问题一起发送给模型进行回答。因此,可以将 LLM 看作一种新型智能操作系统的“内核”,通过连接外部实时信息来向模型动态注入知识内容。
整个过程可以概括为3个步骤:用户提出问题、系统从知识库中检索相关内容、以及大语言模型结合检索结果生成最终答案。对于 RAG 的整体工作机制,可以通过图 1-2 进行直观理解。
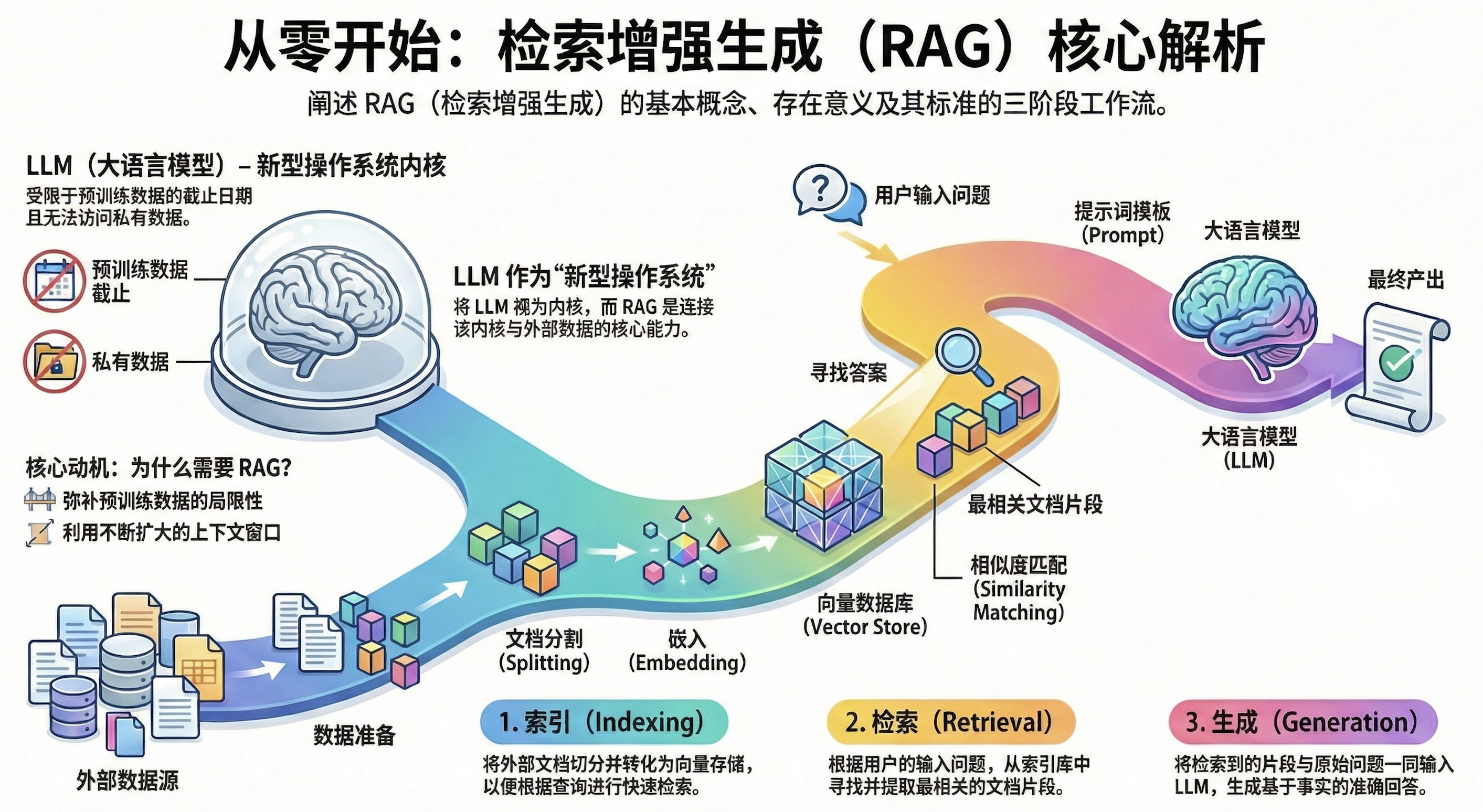
1.2.2 RAG 的 3 个核心阶段#
从系统实现的角度来看,RAG 通常由3个核心阶段组成:
- 索引(Indexing):构建知识库,使文档能够被高效检索;
- 检索(Retrieval):根据用户问题查找最相关的知识内容;
- 生成(Generation):结合检索结果生成最终答案。
对于索引阶段来说,它的目标是将原始文档,例如企业知识库、网页内容、产品手册等,加工成适合检索的形式,并建立知识库,包括文档加载、文档切分、向量化以及向量存储。
对于检索阶段来说,它的作用是当用户发起问题时系统首先会使用与索引阶段相同的嵌入模型将用户问题转换为向量表示,随后在向量数据库中寻找与该问题语义最接近的文档片段,并选择其中的 Top-K 返回。
对于生成阶段来说,在完成检索后,系统会将用户问题与检索到的文档内容组合成一个新的提示词。例如:
你是一个问答助手,请根据以下提供的参考资料回答用户问题。如果参考资料中不存在相关信息,请明确说明。
参考资料: {retrieved_documents}
用户问题: {question}
随后,将构造好的 Prompt 提交给大语言模型进行推理。此时,大语言模型不仅能够利用自身预训练阶段掌握的知识,还能够参考实时检索到的外部信息,从而生成更加准确和可靠的回答。
至此,我们已经完成了对 RAG 整体工作流程的介绍。通过本章内容,相信读者已经对 RAG 的基本组成和运行机制有了初步认识。从下一章开始,我们将正式进入 RAG 开发实践,逐步学习构建一个完整 RAG 系统所需的核心技术与实现方法。