10.18 百川大模型使用#
在前面几节内容中,我们陆续介绍了GPT系列模的技术原理和使用方法,对于GPT相关模型整体上也有了一定的了解。在本节内容中,我们将以百川大模型为例,先来详细介绍其使用具体使用方法,然后在下一节内容中具体介绍其内部的构建原理。
10.18.1 模型简介#
1. 模型介绍
百川大模型是由前搜狗公司CEO王小川于2023年4月创立的百川智能所发布的开源可商用的大规模预训练语言模型( Large Language Model, LLM)。截止到2023年12月,百川智能基于Transformer解码器结构已经陆续发布了Baichuan和Baichuan 2两款大模型,本文将要介绍的便是以Baichuan2大模型为基座的聊天模型[1]。
Baichuan2是百川智能推出的新一代开源大语言模型,采用了2.6万亿词元的高质量语料训练 [2]。根据模型的参数规模来看Baichuan2有Baichuan2-7B-Base和Baichuan2-13B-Base这两个基座模型,前者的隐藏层个数和多头个数均为32、隐藏层维度为4096整体相当于表10-2中GPT-3 6.7B的规模,后者的隐藏层个数和多头个数均为40、隐藏层维度为5120整体相当于表10-2中GPT-3 13B的规模。除此以外,百川智能基于这两个基座模型还分别微调得到一个聊天模型,即Baichuan2-7B-Chat和Baichuan2-13B-Chat这两个模型。为了便于加载以及下载预训练模型,后续我们将以Baichuan2-7B-Chat这个模型为例来进行介绍。同时,百川智能还提供了这两个聊天模型对应的4bits量化(Quantize)版本。所谓模型量化是一种用于减少模型大小和提高模型计算速度的技术,它通过将浮点计算转换为低比特(如4bits和8bits)定点计算的方式来降低模型的参数量、计算量和内存消耗,但这种方法也会给模型带来一定的精度损失。
2. 在线使用
如同使用ChatGPT一样,通过百川智能提供的在线服务[3]我们便能够直接使用到百川大模型。相比于ChatGPT,百川智能推出的对话服务还支持在线联网搜索内容,我们可以直接向它提问某个链接里的相关内容。同时,它还能使用到ChatGPT中付费用户才能使用的文件上传功能。下面我们展示几个简单的使用示例。

如图10-59所示是聊天服务中示例的相关用法。这里我们同样以“请你解释一下什么是登月,需要注意的是生成结果的面向对象是一个6岁的儿童。” 这个问题来测试百川大模型的理解能力。
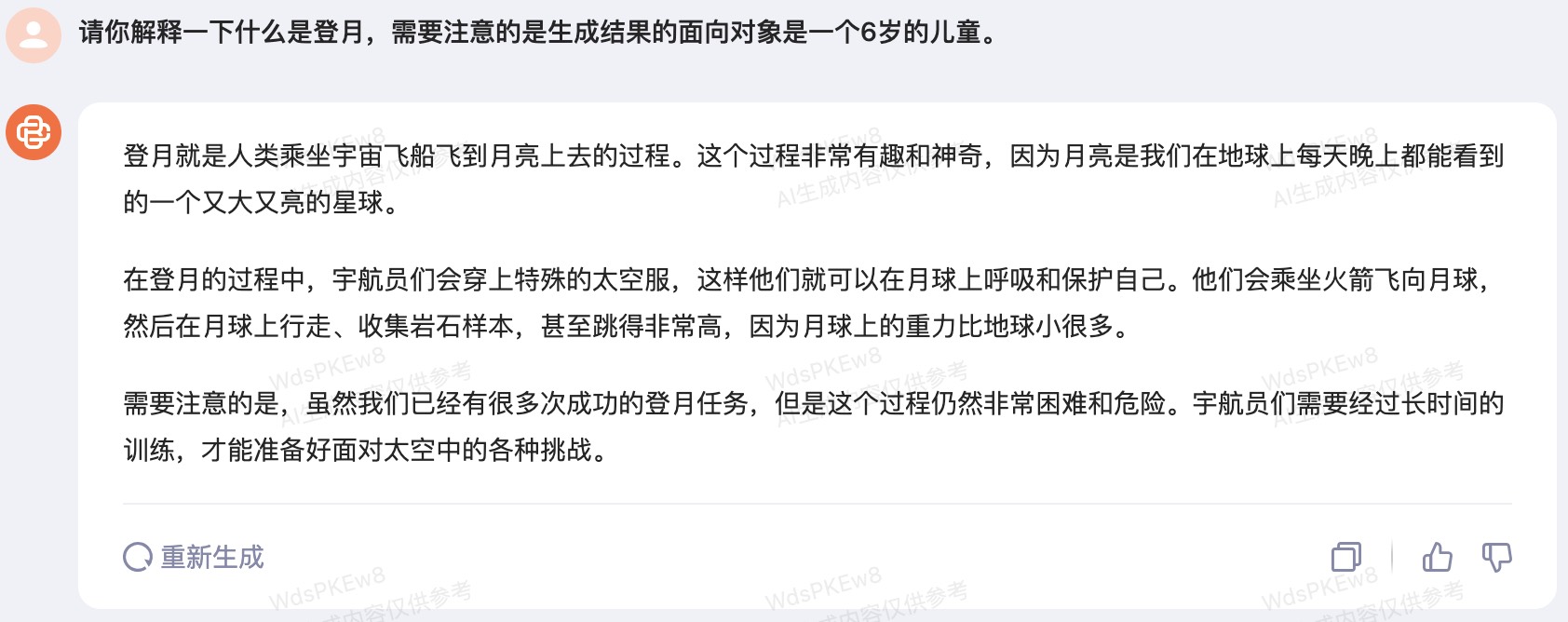
如图10-60所示便是百川大模型的生成结果,各位读者可以将其与10.17.2节中ChatGPT的生成结果对比。进一步,可以针对本地上传的附件使用百川大模型进行分析。
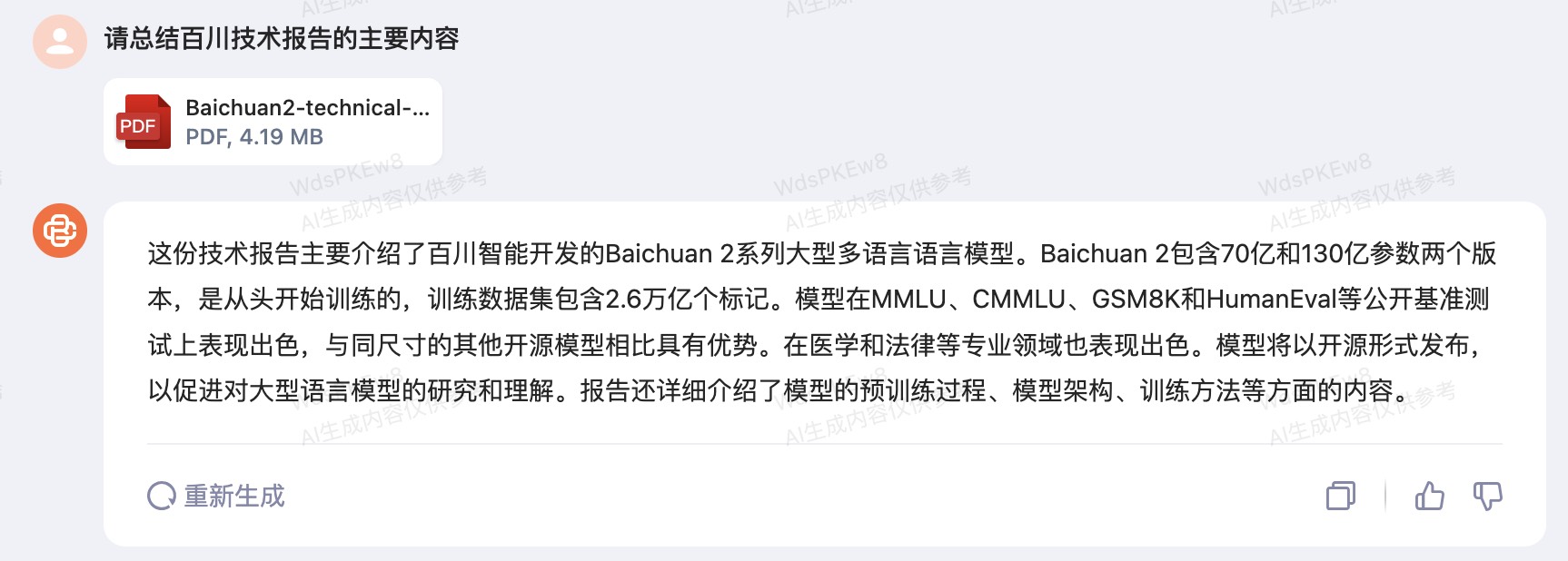
在图10-61所示的结果便是百川大模型根据上传的PDF总结的内容,同时,我们还可以针对PDF中的内容继续进行提问交
10.18.2 项目介绍#
为了便于学习这个项目的代码,所以我们需要在Huggingface[2]下载整个工程对应的代码文件,并且在使用时需要直接导入对应的模块而不是通过类似AutoModelForCausalLM()这样的方式来通过模型名称自动下载并加载模型。这里建议各位读者直接使用本书所维护工程下的项目代码[4],详见Code/Chapter10/C07_BaiChuan2/Baichuan2_7B_Chat目录。
1.工程结构
在下载完成后该目录下一共会有11个文件,这里逐一简单介绍一下。config.json是记录整个模型超参数的配置文件,例如多头数量、隐藏层数量等;tokenizer_config.json是记录词元切分器的相关配置参数;special_tokens_map.json是记录特殊词元的相关信息;generation_config.json是记录推理时模型的相关超参数,例如temperature、top_k和top_p等;tokenizer.model是一个实例化的模型文件,保存的是原始语料对应的词表;tokenization_baichuan.py是百川大模型对应词元切分器BaichuanTokenizer的实现模块;configuration_baichuan.py是百川大模型对应配置类BaichuanConfig的实现模块;modeling_baichuan.py是百川大模型BaichuanModel相关的实现模块;generation_utils.py是模型推理时对输入进行预处理的相关功能模块;quantizer.py是对模型参数进行4bits或8bits量化的功能模块;pytorch_model.bin则是对应的预训练模型。
2. 环境安装
由于Baichuan2使用到了Pytocrch 2.0版本中的新特性,即一种高效计算多头注意力的模块,所以这里我们这里需要使用2.0版本以上的Pytorch框架。首先,我们根据2.2节内容所介绍的步骤,通过项目中所提供的requirements.txt(包含有78个依赖包)文件完成Python环境的安装。同时,需要将下载好的预训练模型pytorch_model.bin(大约15GB)放到工程下的Baichuan2_7B_Chat目录中。
10.18.3 模型结构#
从整体上来百川大模型也是基于Transformer解码器架构的大语言模型,只是对其中各个小的模块进行了优化和改进,这里我们进行一个简单的介绍。如图10-62所示便是Baichuan2模型对应的网络结构图。
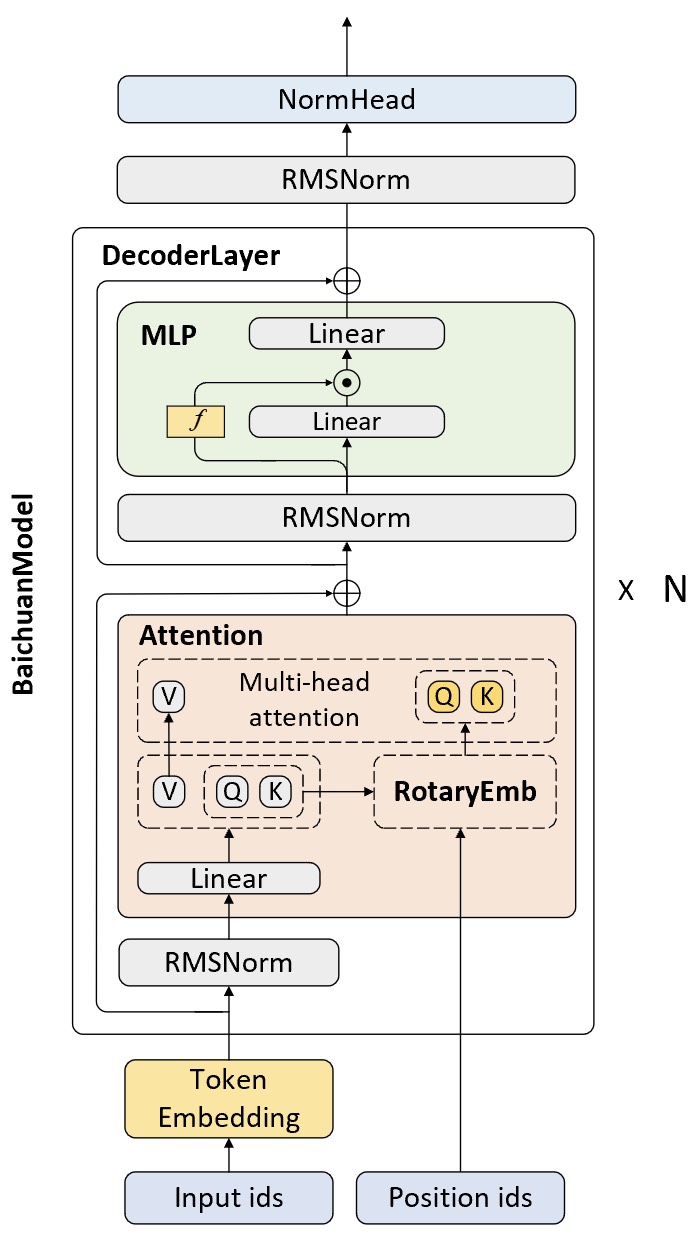
从图10-62可以看出,相较于原始的Transformer解码器,Baichuan2中最明显的变化在于归一化层、多头注意力层和多层感知机层。在自注意力层中,百川大模型采用了旋转位置编码(Rotary Position Embedding)[5]来对输入序列进行位置编码。简单来说,旋转编码通过引入旋转矩阵来改善模型的位置编码信息,随着输入序列相对长度地增加旋转编码能够灵活地处理各个位置上的依赖关系,以此来提高模型的泛化能力。虽然Baichuan2训练过程中最大长度为4096,但是实际测试中模型可以很好的扩展到5000以上[2]。在解码层的多层感知机中,Baichuan2使用了类似于LSTM中的门控机制来对信息流进行筛选。同时,对于各层之间的归一化方式,Baichuan2采用了更为轻量级的均方根归一化方式(Root Mean Square Normalization),即先对每个神经元计算平方并取均值,然后再将均值的平方根作为系数来归一化对应的神经元。
到此,对于Baichuan2模型网络结构部分的内容就介绍完了,下面我们继续从使用的角度来介绍Baichuan2模型。
10.18.4 模型推理#
在对Baichuan2模型有了一个整体的了解之后,我们再来看如何使用它完成推理过程,即实现完整的对话流程。在官方开源的项目中一共提供两种方式来使用模型进行推理:一个是在命令行终端中进行使用,另一个则是提供了以网页端访问的方式进行使用。下面分别就这两种方式进行介绍。
1. 命令行终端使用
对于命令行终端这一使用方式来说,我们只需要激活上面创建好的虚拟环境并进入到工程根目录中,然后执行python cli_demo.py命令即可运行该程序。紧接着大约30秒钟后,我们便会看到命令行中出现如下提示:
欢迎使用百川大模型,输入进行对话,vim 多行输入,clear 清空历史,CTRL+C 中断生成,stream 开关流式生成,exit 结束。
用户:进一步,我们便可以输入问题让模型输出相关的回答。
用户:什么是深度学习?
Baichuan 2:深度学习是一种人工智能技术21137a686964616fe59b9ee7ad9如上所示便是模型对于问题”什么是深度学习?“所给出的回答。可能由于我们这里使用的是7B版本的模型,所以模型大约在生成13个字以后便开始胡言乱语了。
2. 网页端使用
对于网页端的使用来说,首先同样需要激活上面创建好的虚拟环境并进入到工程对应的根目录下,然后执行streamlit run web_demo.py命令岂可启动模型服务。默认端口为8502,如果需要指定端口可以通过命令streamlit run web_demo.py --server.port 8888进行启动。紧接着同样大概30秒以后我们便会看到命令行中出现如下提示:
1 You can now view your Streamlit app in your browser.
2
3 Network URL: http://172.2.3.1:8888
4 External URL: http://139.10.39.216:8888进一步,我们只需要在我们本地浏览器中打开上面的链接即可访问该对话服务。这里需要提醒的是,如果使用的云服务器可能需要在控制页面的网络安全策略组里面打开上面对应的端口,否则该链接无法打开。
在浏览器中打开该链接以后我们将会看到类似如图10-63所示的结果。
最后,我们便可以在网页端同模型进行对话交互。以上就是Baichuan2对话模型的两种使用方式,各位读者也可以将模型更换成13B的版本来进一步测试模型的回答效果。
10.18.5 模型微调#
在清楚模型的基本使用方法以后我们再来看如何基于百川智能开源的基座模型通过自定义语料来微调一个聊天对话模型。在进行模型微调时,首先我们需要去项目对应的主页 [7]下载整个工程包括其中的预训练模型,大约15GB,这里建议各位读者直接使用本书维护的工程Code/Chapter10/C08_Baichuan2FineTune目录下对应整理好的代码[4]。
此时,我们可以在C08_Baichuan2FineTune目录下看到有两个文件夹Baichuan2_7B_Base和data,其中我们需要将下载完成的两个模型文件放到Baichuan2_7B_Base目录中。在data目录下则是存放的是训练用的数据文件,我们在微调时只需要将聊天对话数据整理成对应的标准格式,然后使用官方提供的脚本微调模型。
如下所示便是训练数据的标准格式:
1 [{"id": "27684","conversations":
2 [{"from": "human","value": "你好,请问你能帮我查一下明天的天气吗?\n"},
3 {"from": "gpt","value": "当然,你在哪个城市呢?\n"},
4 {"from": "human","value": "我在上海。\n"},
5 {"from": "gpt","value": "根据天气预报,明天上海多云转阴气温在20到25摄氏度之间。需要查询其他信息吗?"}]
6 },{},...]在上述示例中,每个样本即为列表中的一个元素,并且一个样本中包含有多轮的上下文对话。进一步,我们只需要通过如下命令即可开始进行模型微调:
1 deepspeed fine_tune.py \
2 --report_to "none" \
3 --data_path "data/belle_chat_ramdon_10k.json" \
4 --model_name_or_path "Baichuan2_7B_Base" \
5 --output_dir "output" \
6 --model_max_length 512 \
7 --num_train_epochs 4 \
8 --per_device_train_batch_size 16 \
9 --gradient_accumulation_steps 1 \
10 --save_strategy epoch \
11 --learning_rate 2e-5 \
12 --lr_scheduler_type constant \
13 --adam_beta1 0.9 \
14 --adam_beta2 0.98 \
15 --adam_epsilon 1e-8 \
16 --max_grad_norm 1.0 \
17 --weight_decay 1e-4 \
18 --warmup_ratio 0.0 \
19 --logging_steps 1 \
20 --gradient_checkpointing True \
21 --deepspeed ds_config.json \
22 --bf16 True 在执行上述命令以后,便可以在控制台看到类似如下输出信息:
1 {'loss': 12.0625, 'learning_rate': 2e-05, 'epoch': 0.09}
2 {'loss': 12.1875, 'learning_rate': 2e-05, 'epoch': 0.09}
3 {'loss': 10.9888, 'learning_rate': 2e-05, 'epoch': 1.0}
4 100%|███████████████████████████████| 625/625 [01:21<00:00, 7.67it/s]最后,待模型微调结束以后我们只需要使用其持久化后的模型文件替换掉上面Baichuan2_7B_Chat文件中模型文件即可使用。关于这部分内容的细节之处我们将在下一节内容中进行介绍。
10.18.6 小结#
在本节内容中,我们首先介绍了百川大模型的基本信息以及如何使用百川大模型对应的线上服务;然后介绍了Baichuan2这个项目的基本信息以及如何安装模型运行的环境;进一步,我们介绍了Baichuan2模型的整体网络结构和如何使用Baichuan2进行推理;最后,我们介绍了如何基于基座模型根据自定义的聊天对话数据来微调一个对话模型。在下一节内容中,我们将进一步详细介绍Baichuan2模型的实现细节。
引用#
[1] https://github.com/baichuan-inc/Baichuan2
[2] https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/tree/main
[3] https://www.baichuan-ai.com/chat
[4] https://github.com/moon-hotel/DeepLearningWithMe/
[5] Su J, Ahmed M, Lu Y, et al. Roformer: Enhanced transformer with rotary position embedding[J]. Neurocomputing, 2024, 568: 127063.