9.3 Word2Vec训练与使用#
在9.2节内容中,我们详细介绍了Word2Vec中CBOW和Skip-gram这两种建模语言模型来训练词向量的方法。根据式(9-8)和式(9-13)可知,由于目标词(在CBOW中指中心词,在Skip-gram中指上下文词)可以是词表$\mathcal{V}$中的任意一个,因此在计算条件概率时需要计算每个目标词与所有其他词之间的相似度,这就导致模型在计算梯度时同样需要计算大量的求和项(项数同词表长度一致)。但是由于在实际情况中词表的长度通常可以达到几十万或数百万,所以直接采取这样的方法来训练模型开销巨大[1]。
9.3.1 近似训练#
为了降低模型训练在计算梯度时的复杂度提高模型的训练效率,托马斯(Tomas)等人[2]又提出了两种近似训练方法分层Softmax(Hierarchical Softmax)和负采样(Negative Sampling)来解决这一问题。
分层Softmax的核心思想在于利用霍夫曼树的结构来表示词表中词之间的概率关系,树中的每个叶子节点表示词表中的一个词,每条路径则通过每个词的词频进行构建(频率越高的词离根节点越近),同时每个非叶子节点都对应着一个二分类器用于判断目标词在该节点左孩子或者右孩子中的概率,最终通过依次计算路径上各二分类器概率的乘积得到目标词与上下文词之间的条件概率。
负采样的思想是将滑动窗口中的非目标词看做是正样本,并同时在整个词表中(不包括滑动窗口中的词)随机采样部分词作为负样本,而负采样方法的目标则是最大化目标词与正样本一同出现的概率,并同时最小化目标词与负样本一同出现的概率[1]。由于这部分内容过于繁杂我们这里就暂不做介绍,下面我们直接使用开源工具库Gensim来构建相应模型。
9.3.2 载入预训练词向量#
1. Gensim介绍
Gensim是Generate Similar的简称,它是一个免费开源的Python库,主要用于高效地将文本转换为向量表示等自然语言处理任务,并且Gensim还提供了一套简单而强大的API,使得处理大规模语料库和构建语言模型变得更加简单便捷[3]。

Gensim中的核心功能包括9.2节内容中介绍的Word2Vec模型以及在9.4节中将要介绍的FastText模型和LDA模型等。通过Gensim我们可以轻松地进行文本数据的预处理、特征提取和模型训练,从而支持各种与文本分析和语义相关的任务。由于其简洁易用的设计和高效的性能使得Gensim成为了自然语言处理领域中广泛应用的工具之一。
在使用Gensim之前首先需要通过命令pip install --upgrade gensim完成Gensim库的安装。接下来我们来看如何使用Gensim载入已经持久化到本地的词向量文件。
2. 英文词向量
在这里,我们首先以Word2Vec论文中谷歌开源的词向量为例进行介绍。首先需要去谷歌官网下载该文件[4],下载完成后将会得到一个名为GoogleNews-vectors-negative300.bin.gz的文件。
进一步,我们可以通过如下方式载入该词向量文件并进行相关计算,示例代码如下所示:
1 from gensim.models import KeyedVectors
2
3 def load_third_part_wv_en():
4 path_to_model = os.path.join(DATA_HOME, 'Pretrained',
5 'GoogleNews-vectors-negative300.bin.gz')
6 model = KeyedVectors.load_word2vec_format(path_to_model, binary=True)
7 vec_king = model['king']
8 vec_queen = model['queen']
9 logging.info(f"vec_king: {vec_king}")
10 logging.info(f"vec_queen: {vec_queen}")在上述代码中,第1行便是从Gensim中导入KeyedVectors类来加载本地词向量文件。第4~5行是构造词向量文件的路径。第6行便是用于载入本地的词向量文件,其中binary用于指定该文件为一个二进制文件。第7~8行是取单词king和queen对应的词向量。
上述代码运行结束后将会看到类似如下结果:
1 KeyedVectors lifecycle event {'msg': 'loaded (3000000, 300) matrix of type float32'}
2 [ 0.12597656 0.02978515 0.00860595 0.13964843....
3 [ 0.00524902 -0.14355469 -0.06933594 0.12353516....从上述输出信息可以知道,词向量文件中一共包含有300万个词,每个词向量的维度为300维。第2~3行则是单词king和queen对应词向量的部分结果输出。
3. 常见用法
在完成词向量的载入后再来介绍几个KeyedVectors中常见的词向量使用方法。
①通过similarity()方法来计算两个词的相似度
1 sim1 = model.similarity('king', 'queen') # 0.6510956
2 sim2 = model.similarity('king', 'soldiers') # 0.1256730如上所示便是通过余弦距离来计算两个词的相似度。
②通过distance()方法计算两个词之间的距离
1 dist = model.distance('king', 'soldiers') # 0.8743269距离的计算公式为1减去两个词之间的余弦距离。
③通过most_similar()方法查找与给定词最相似的前K个词
1 sim_words = model.most_similar(['king'], topn=3)其输出结果为
1 [('kings', 0.713804), ('queen', 0.651095), ('monarch', 0.641319)]同时,也可以通过该方法计算与多个词相似的词
1 sim_words = model.most_similar(['king', 'queen'], topn=3)其输出结果为
1 [('monarch', 0.704206), ('kings', 0.678086), ('princess', 0.673155)]在计算上述结果时,本质上是计算的是离king和queen这两个词词向量均值最近的前K个词。
进一步,也可以通过该方法来查找与词A相似,但是与词B不相似的前K个词
1 sim_words = model.most_similar(positive=['apple'], negative=['fruit'], topn=3)对于上述代码来说,其含义表示需要查找与apple相似的词,但是又要尽可能的排除掉与fruit相似的词。
最后的输出结果为
1 [('Apple', 0.333127), ('Appleâ_€_™', 0.321516), ('Ipod', 0.317912), ('designer_Jonathan_Ive', 0.313949),
('ipod', 0.305660), ('ipod_nano', 0.305071)]从输出结果可以看出,此时找打的是与苹果电子产品相关的词而非与水果相关的词,其中Jonathan Ive为苹果公司的首席设计官。
④通过doesnt_match()方法查找给定词中与其它词差异最大的词
1 model.doesnt_match(['king', 'queen', 'soldiers']) # soldiers4. 中文词向量
在介绍完英文词向量之后我们再来看一下中文词向量的加载。下面我们使用到的是一个开源的中文词向量项目[5],里面包含有百度百科、维基百科和人民日报等多种训练训练得到的中文词向量。这里以人民日报训练得到的词向量为例,下载完成后将会得到一个名为sgns.renmin.word.bz2的文件。
进一步,可以通过类似上面的方法来载入该词向量文件,示例代码如下所示
1 def load_third_part_wv_zh():
2 path_to_model = os.path.join(DATA_HOME,'Pretrained', 'sgns.renmin.word.bz2')
3 model = KeyedVectors.load_word2vec_format(path_to_model, binary=False)
4 vec_china = model['中国']
5 logging.info(f"中国: {vec_china}") 在上述代码中需要注意的是第4行,由于sgns.renmin.word.bz2并不是一个二进制文件,所以参数binary需要设置为False。
上述代码运行结束后将会看到类似如下结果:
1 KeyedVectors lifecycle event {'msg': 'loaded (355987, 300) matrix of type float32'}
2 [0.0266010 0.238758 0.0367000 -0.173718 -0.145088...同时,我们也可以使用most_similar()等方法来完成相应的词向量计算。例如与"上海市"最相似的5个词为
1 sim_words = model.most_similar(['上海市'], topn=5)
2 [('天津市', 0.7273417), ('南京市', 0.711648), ('杭州市', 0.708043), ('上海', 0.670013), ('重庆市', 0.658153)]以上完整示例代码及注释可以参见Code/Chapter09/C01_Word2Vec/main.py文件。
9.3.3 可视化与类别计算#
1. 可视化
在介绍完词向量的使用之后下面再来看如何对词向量进行可视化。这里我们需要借助TSNE算法[6]来将300维度的词向量降低到2维的结果。具体地,通过实现一个函数来完成降维过程,示例代码如下所示:
1 from sklearn.manifold import TSNE
2 def reduce_dimensions():
3 path_to_model = os.path.join(DATA_HOME, 'Pretrained', 'sgns.renmin.word.bz2')
4 model = KeyedVectors.load_word2vec_format(path_to_model, binary=False, limit=2500)
5 num_dimensions = 2
6 vectors = np.asarray(model.vectors)
7 labels = np.asarray(model.index_to_key)
8 tsne = TSNE(n_components=num_dimensions, random_state=0)
9 vectors = tsne.fit_transform(vectors)
10 x_vals = [v[0] for v in vectors]
11 y_vals = [v[1] for v in vectors]
12 return x_vals, y_vals, labels在上述代码中,第1行是导入TSNE降维模块。第4行是载入词向量文件,其中limit参数用来指定数量的词向量以减少载入时间。第6~7行是分别取词向量以及对应的词。第8~9行是实例化一个TSNE对象,并对300维的词向量进行降维。第10~11行表示分别取降维后的两列值。
进一步,通过matplotlib来对降维后的结果进行可视化,示例代码如下所示:
1 def plot_with_matplotlib():
2 x_vals, y_vals, labels = reduce_dimensions()
3 plt.figure(figsize=(8, 8))
4 plt.scatter(x_vals, y_vals)
5 indices = list(range(len(labels)))
6 selected_indices = random.sample(indices, 70)
7 for i in selected_indices: # 展示标签
8 plt.annotate(labels[i], (x_vals[i], y_vals[i]), fontsize=14)
9 plt.show()在上述代码中,第4行是可视化降维后的每个词向量。第5~8行是随机选择其中70个词向量的标签进行展示。
最终将得到如图9-9所示的词向量可视化结果。
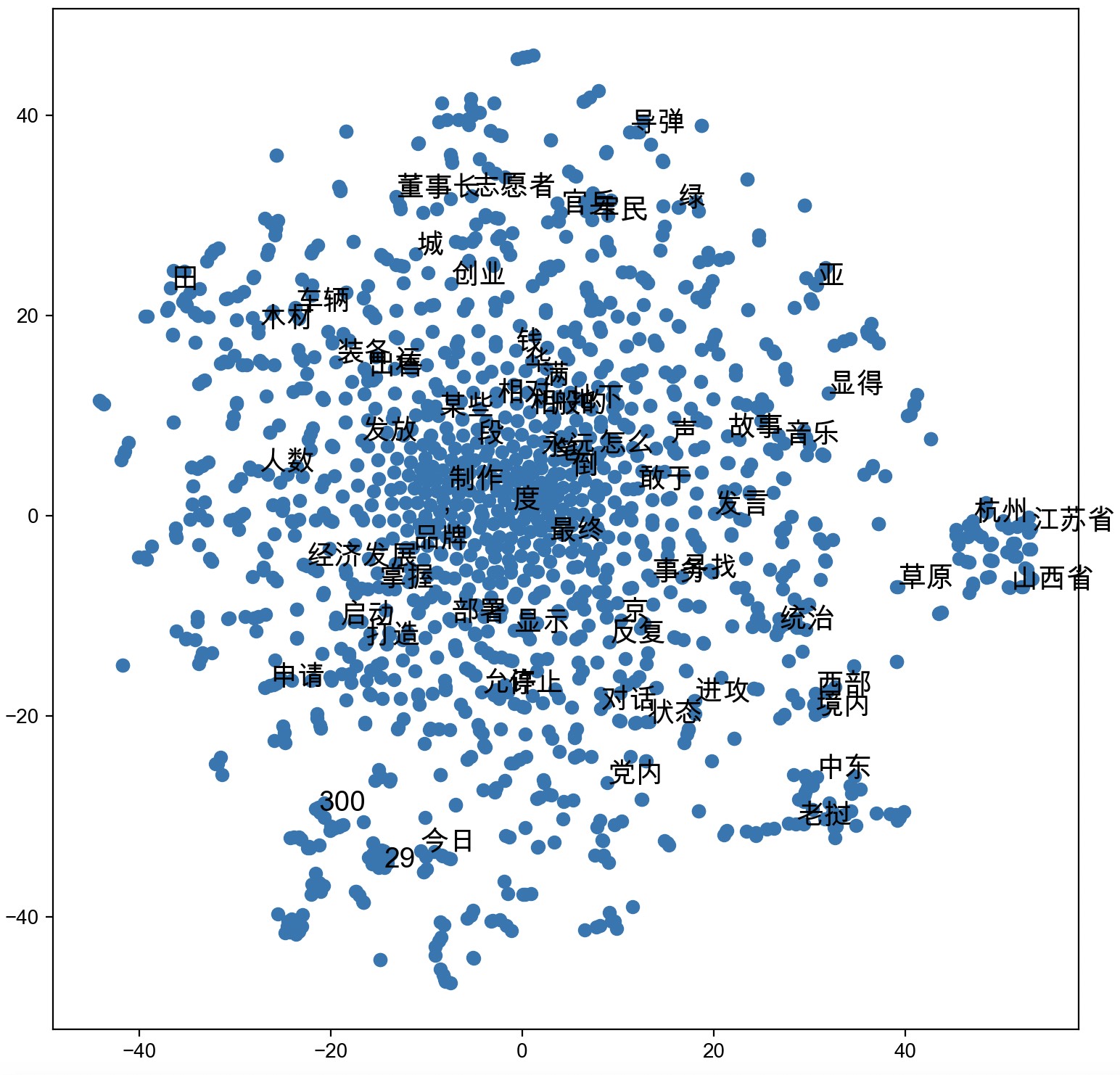
从图9-9可以看出,大部分具有相似语义的词向量都处于相邻位置。
2. 类比计算
此时可以对Word2Vec论文中所提出来的语义类比进行验证。首先,通过上面介绍的most_similar()方法可以找到与‘queen’最相似的前3个词分别为
1 [('queens', 0.739944), ('princess', 0.707053), ('king', 0.651095)]进一步,将类比计算得到的向量进行对比,示例代码如下所示:
1 def vector_relation():
2 path_to_model = os.path.join(DATA_HOME, 'Pretrained',
3 'GoogleNews-vectors-negative300.bin.gz')
4 model = KeyedVectors.load_word2vec_format(path_to_model, binary=True, limit=50000)
5 vec_king, vec_man = model['king'], model['man']
6 vec_queen, vec_woman = model['queen'], model['woman']
7 result = vec_king - vec_man + vec_woman
8 sim1 = np.dot(matutils.unitvec(result), matutils.unitvec(model['queen']))
9 sim2 = model.similarity('queens', 'queen')
10 logging.info(f"queen和推算结果的相似度为: {sim1:.4f}") # 0.7301
11 logging.info(f"queen和queens的相似度为: {sim2:.4f}") # 0.7399在上述代码中,第5~6行是取各个次对应的真实词向量表示。第7行是通过类比计算得到词queen的词向量表示。第8~9行是分别以词‘queen’为基准,计算其与‘queens’和类比结果的相似度,可以发现两者的相似度几乎一致。此时可以得出,通过类比计算得到的‘queen’对应的词向量可以近似代替‘queen’真实的词向量表示。
进一步,我们还可以通过类似的方法来验证等式’king’ - ‘queen’ = ‘man’ - ‘woman’的成立性,各位读者可以自行尝试。
以上完整示例代码及注释可以参见Code/Chapter09/C01_Word2Vec/visualization.py文件。
9.3.4 词向量训练#
在介绍完词向量的加载和使用方法后我们再来看如何根据语料从零开始训练词向量。这里我们使用到的语料是搜狗新闻,下载地址见代码仓库。为了提高语料的加载速度和降低内存开销,gensim库已经提供了相应的数据集构建模块,只需要将原始语料按每一行为一篇文档且按空格进行分词放在一个文件中即可。下面开始介绍原始数据的预处理过程。
1. 构建数据集
对于该语料来说,文件解压后将会得到9个文件夹,每个文件夹中大约有2000个文本文件,需要依次进行读取并进行相应清洗后写入到本地文件中,示例代码如下所示:
1 class SougoNews(object):
2 DATA_DIR = os.path.join(DATA_HOME, 'SougoNews')
3
4 def __init__(self, use_in='word2vec'):
5 self.use_in = use_in
6 self.PROCESSED_FILE_PATH = os.path.join(self.DATA_DIR, f'SougoNews_{use_in}.txt')
7 self.make_corpus()
8
9 def make_corpus(self):
10 self.corpus_path = self.PROCESSED_FILE_PATH
11 if not os.path.exists(self.PROCESSED_FILE_PATH):
12 self.data_process()在上述代码中,第2行定义了语料的路径。第4行定义的是该语料用于何种模型,因为在不同模型中语料的预处理会有略微差别,这里主要是用于Word2Vec和后续fastText模型词训练,前者需要分词处理而后者不需要。第6行是根据不同的模型构造预处理结束后新文件的文件名。第7行表示在初始化时完成语料的构建。第9~12行是判断预处理后的文件是否存在,不存在则重新构建。
进一步,对数据进行读取和预处理,关键代码示例如下:
1 def data_process(self, ):
2 new_file = open(self.PROCESSED_FILE_PATH, 'w', encoding='utf-8')
3 dir_lists = os.listdir(self.DATA_DIR)
4 for dir in dir_lists:
5 dir_name = os.path.join(self.DATA_DIR, dir)
6 file_lists = os.listdir(dir_name)
7 for file in file_lists:
8 file_path, result= os.path.join(dir_name, file), []
9 with open(file_path, 'r', encoding='gbk') as f:
10 for line in f:
11 line = line.strip().replace(' ', '')
12 if len(line) < 30:
13 continue
14 line = unicodedata.normalize('NFKC', line)
15 if self.use_in == 'word2vec':
16 line = tokenize(line, cut_words=True)
17 elif self.use_in == 'fasttext':
18 line = [line]
19 result += line
20 new_file.write(" ".join(result) + '\n')
21 new_file.close()在上述代码中,第2行是本地新建一个文件并获得操作句柄。第3行是获取对应目录下所有文件夹的名称。第4~6行是获取每个文件夹下所有文件的文件名。第7~9行是循环读取每个文件夹中的每个文件。第10~13行是读取文件中的每一行并进行简单的清洗和过滤。第14行是将全角字符转换为对应的半角字符。第15~16行是对每一行进行分词并保存到一个列表中。第17~18行是不进行分词处理,直接当成整行处理。第20行则是将文件中的所有文本看做一行写入到新文件中。
上述代码在执行完毕之后,SougoNews文件夹中将会生成一个名为SougoNews_word2vec.txt的文件,其内容类似如下:
在 昨天 国家劳动和社会保障部 公布 的 第六批 14 个 新 职业 信息 中 , 信用 管理 师听 上去 最具 诱惑力 。 那么 , 信用 管理 师 的 主要 工作 职能 是 什么 ? 从业 门槛 有 多 高 ? 发展前景 又 如何 呢 ? 所谓 信用 管理 师是 指 运用 现代 信用 经济 、 信用 管理 及其 相关 学科 的 专业知识 , 遵循 市场经济 的 基本 原则 , 使用 信用 管理 技术 与 方法 , 从事 企业 和 消费者 信用风险 管理工作 的 专业 人员 。 信用 管理 师 具体 从事 哪些 工作 呢 ? 最后,只需要调用gensim提供的相应接口即可完成数据集的构建,示例代码如下所示:
1 class MyCorpus(SougoNews):
2 def __init__(self):
3 super(MyCorpus, self).__init__()
4 pass
5
6 def __iter__(self):
7 for line in open(self.PROCESSED_FILE_PATH):
8 yield utils.simple_preprocess(line)以上完整示例代码及注释可以参见[Code/utils/data_helper.py`文件。
2. 模型训练