第 9 章 自然语言处理#
在前面两章内容中我们已经初步接触了与文本处理相关的任务模型,例如7.2节和8.1节中介绍的文本分类任务、7.6节中介绍的文本生成任务以及后续将会介绍到的机器翻译、问答模型和命名体识别任务等,而这些任务场景在人工智能领域也有一个特定的称谓——自然语言处理(Natural Language Processing, NLP)。自然语言处理是人工智能的一个子领域,它涉及计算机对人类自然语言的理解和生成,即自然语言理解(Natural Language Understanding, NLU)和自然语言生成(Natural Language Generation, NLG),其目标是使计算机能够理解、分析、生成语言并且能够实现与人类语言进行交互。在本章内容中,我们将会以整个自然语言处理的发展路线为主干来梳理其中几项关键技术出现的动机和相关原理。
9.1 自然语言处理介绍#
自然语言处理起源于 20 世纪 50 年代。 早在 1950 年,计算机科学与人工智能之父艾伦·图灵(Alan Turing)就发表了一篇名为“计算机器与智能”的文章,并提出了著名的图灵测试,即一个是正常思维的人(代号B)、一个是机器(代号A),如果经过若干询问以后C不能得出实质的区别来分辨A与B的不同,则此机器B通过图灵测试[1]。
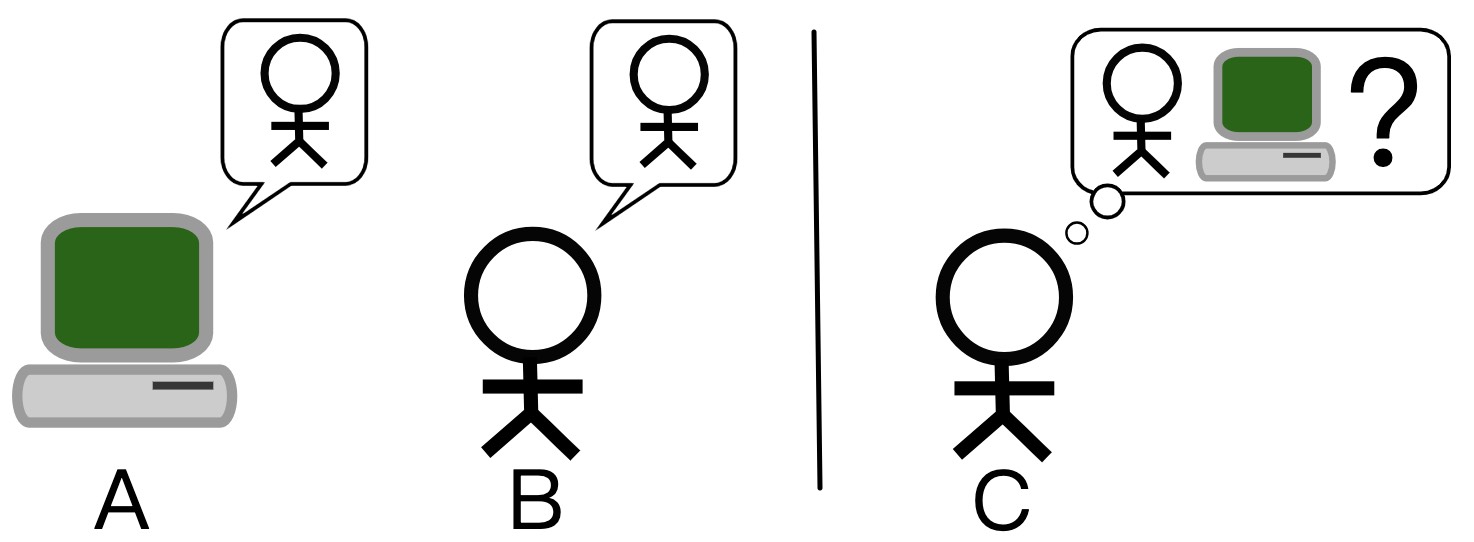
可以看出,如果需要实现机器和人类的交互,那么首先需要实现的便是机器对于人类自然语言的理解,因此一般认为自然语言处理的历史可以追溯到那个时候,至今已经过去了70多年[2]。
从自然语言处理整个技术路线的发展来看大致可以分为3个阶段:20世纪50年代至20世纪90年代早期主要是基于规则的语言模型,20世纪90年代至21世纪早期主要是基于统计的语言模型,21世纪早期到现在主要是基于神经网络的语言模型 [3]。
9.1.1 语言模型#
自然语言处理的本质是理解并生成语言,而对于计算机来说理解的本质便是根据语料训练得到文本序列的概率分布 [4]。因此,所谓语言模型便是根据给定文本序列来估计序列的联合概率,即对于任意长度为$T$的序列来说,语言模型的目的便是用来估计联合概率$P(x^{(1)},...,x^{(T)})$,如式(9-1)所示[4] [5] [6]
$$ \begin{aligned} P(x^{(1)},...x^{(T)})=&P(x^{(1)})\times P(x^{(2)}|x^{(1)})\times P(x^{(3)}|x^{(2)},x^{(1)})\times\cdots\times P(x^{(T)}|x^{(T-1)},...,x^{(1)})\\[2ex] =& \prod_{t=1}^TP(x^{(t)}|x^{(t-1)},...,x^{(1)}) \end{aligned}\tag{9-1} $$其中等式右边的条件概率便是根据语料训练得到的语言模型。
语言模型可以用来衡量一个句子或文本序列在语言中的合理性或流畅度,因此广泛应用于自动语音识别、机器翻译、文本生成和文本补全等自然语言处理任务中,例如常见的搜索引擎关键词联想功能,如图9-2所示。

在图9-2中,我们输入序列“Natural Language”之后,搜索引擎便自动给出了若干种(这里只给出了前3种)可能的联想结果,而这一过程便可以通过分别计算各个序列对应的联合概率再以概率降序排序得到[5]。例如对于图9-2中这3种情况来说,其联合该分别为
$$ \begin{aligned} P(\text{'N'},\text{'L'},\text{'P'})&=P(\text{'N'})\times P(\text{'L'}|\text{'N'})\times P(\text{'P'}|\text{'N'},\text{'L'})\\[2ex] P(\text{'N'},\text{'L'},\text{'I'})&=P(\text{'N'})\times P(\text{'L'}|\text{'N'})\times P(\text{'I'}|\text{'N'},\text{'L'})\\[2ex] P(\text{'N'},\text{'L'},\text{'U'})&=P(\text{'N'})\times P(\text{'L'}|\text{'N'})\times P(\text{'U'}|\text{'N'},\text{'L'}) \end{aligned}\tag{9-2} $$其中$\text{'N'},\text{'L'},\text{'P'},\text{'I'},\text{'U'}$分别指Natural、Language、processing、inference和understanding这5个单词。
9.1.2 基于规则的语言模型#
受到人类对于传统语言学习过程的影响,直到20世纪80年代末大多数科学家依旧认为分析句子语法结构是理解自然语言的基础,要想理解句子就必须弄清其中的语法规则或词性结构。
例如对于句子“小明昨天买了一本书”来说,通过句法分析我们可以识别出这个句子的主语是名词“小明”,谓语是动词“买了”,宾语是名词短语“一本书”,状语是名词“昨天”。同时,我们可以得出“小明”和“买了”之间的关系是动作的执行者和动作的行为,而“买了”和“一本书”之间的关系是动作的对象。在有了这些基本的语法分析结果后,便可以使用规则来完成对整个句子的语义理解过程。
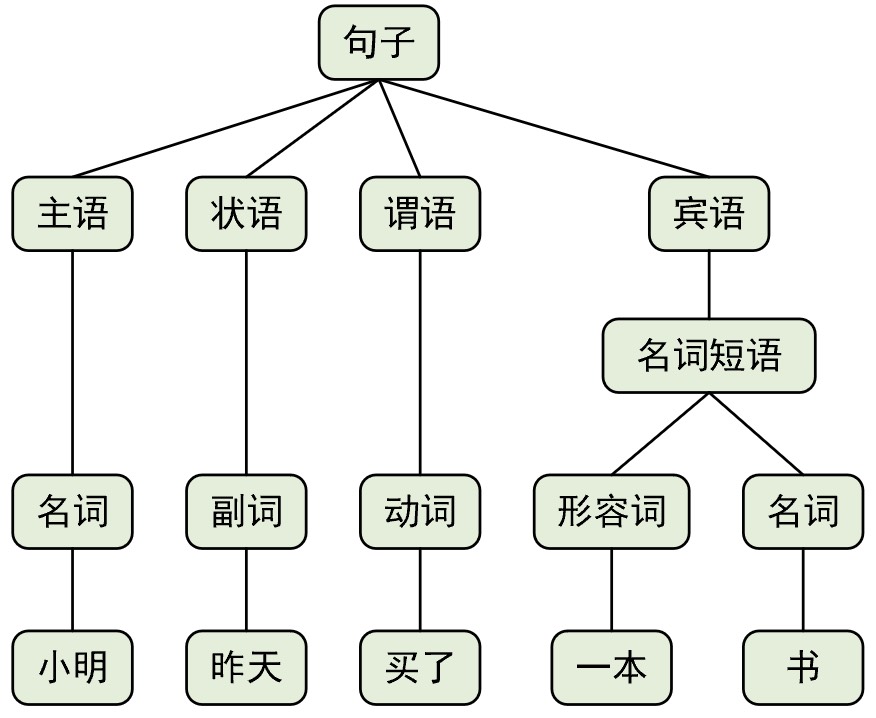
尽管基于规则的模型在一定程度上能够完成句子的语义理解任务,但是通常都需要手动编写和维护大量的规则来覆盖不同场景下的语法规则和语义结构,并且这样的规则往往是繁琐且容易出错的,它难以捕捉到所有语言现象尤其是在面对复杂的句法结构和语义关系时。同时,基于规则的模型通常是针对特定任务和语言问题所设计,很难泛化到其他语言和任务上,当遇到新的语言规则或语言现象时需要手动调整和更新规则,导致模型的可扩展性和适应性受限。正是由于上述种种原因使得基于规则的自然语言处理模型并没有在这一领域取得实质性的成果。
9.1.3 基于统计的语言模型#
随着计算机处理能力的提升和大规模语料库的可用性,基于数学统计的方法开始兴起,即自然语言处理中的统计语言模型(Statistical Language Model)。统计语言模型是一种使用统计方法来建模自然语言的概率模型,它基于观察到的文本语料(Corpus)数据通过最大似然估计来估算得到词语之间的概率关系,即整个语言模型对应的模型参数。
根据式(9-1)可知,通过最大似然估计很容易就能够计算得出第1个词$x^{(1)}$出现的条件概率$P(x^{(1)})$,而第2个词出现的条件概率$P(x^{(2)}|x^{(1)})$也还能够方便地计算得出,但是随着序列长度的增加这样的做法便无法再有效地进行下去。直到俄国数学家马尔科夫(Andrey Markov)的出现这个问题才迎刃而解,即我们在计算第$t$个词出现的条件概率时只考虑离它最近的$N-1$个词,这也叫做$N$-gram模型,在数学上被称为马尔科夫假设[7] [8] [9](Markov Assumption),既此时条件概率$P(x^{(t)}|x^{(t-1)},...,x^{(1)})$将等价于$P(x^{(t)}|x^{(t-1)},...,x^{(t-N+1)})$对应的条件概率。
例如当$N=2$时则表示计算任意第$t$个词出现的条件概率时仅考虑离它最近的1个词,即此时条件概率$P(x^{(t)}|x^{(t-1)},...,x^{(1)})$将等价于$P(x^{(t)}|x^{(t-1)})$对应的条件概率。同时,在$N$-gram模型中,当$N=2$时称之为二元模型(Bigrams),当$N=3$时称为三元模型(Trigrams),当$N=4$时则称为四元模型(Four-grams),并且通常情况下在$N$的取值不会超过5,因为$N$越大模型的稀疏性问题越严重[5]。
在确定好$N$-gram模型之后便可以在语料上根据最大似然估计来计算得到每个词出现的条件概率,即
$$ P(x^{(t)}|x^{(t-1)},...,x^{(t-N+1)})\approx\frac{\#(x^{(t)},x^{(t-1)},...,x^{(t-N+1)})}{\#(x^{(t-1)},...,x^{(t-N+1)})}\tag{9-3} $$其中$\#$表示对应序列出现的频次。
假如现在需要训练一个4-grams语言模型,且此时需要计算如下情况中的条件概率
As the proctor started the clock, the students opened their ___.
即计算
$$ P(\omega|\text{ students opened their})=\frac{\#(\text{students opened their ?})}{\#(\text{students opened their})}\tag{9-4} $$同时,假设在整个语料中文本序列“students opened their”一共出现过1000次,文本序列“students opened their books”出现过400次,“students opened their exams”出现过100次,以及其它情况;那么此时便有
$$ \begin{aligned} &P(\text{books}|\text{ students opened their})=\frac{400}{1000}=0.4\\[2ex] &P(\text{exams}|\text{ students opened their})=\frac{100}{1000}=0.1 \end{aligned}\tag{9-5} $$按照类似的计算方式,以4-grams来依次计算整个语料中每个词在前3个词出现下的条件概率便训练得到了整个语言模型。
9.1.4 基于神经网络的语言模型#
随着深度学习技术的快速发展对自然语言处理也带来了革命性的影响,基于神经网络技术的语言模型(Neural Network Language Model)也已经成为了当下建模语言模型的主流方法。相比传统基于统计方法的语言模型神经网络语言模型可以更好地捕捉到文本内部的复杂结构和语义信息。神经网络语言模型通常使用深度学习技术,如第7章中介绍到的RNN模型和第10章中将要介绍到的Transformer模型,来学习文本数据中的概率分布,即同样通过输入前$n$个词来预测第$n+1$个词的概率分布进行建模[4]。更多关于使用深度学习技术来建模语言模型的内容将在本章及第10章中进行详细介绍。
同时,在神经网络语言模型中文本通常被表示为词嵌入(Word Embedding)的形式,即将每个词从高维的离散空间映射到一个低维的连续空间,然再通过最大化正确预测下一个词的概率来训练得到整个语言模型。关于词嵌入的相关内容将在9.2节内容中进行介绍。最后,一旦语言模型训练完成便可以用于生成新的文本,在自然语言生成、机器翻译、文本摘要和对话系统等任务中都有着广泛的应用。
9.1.5 小结#
在本节内容中,我们首先介绍了自然语言处理出现的背景和目的;然后简单介绍了什么是语言模型以及语言模型的应用场景;最后以自然语言处理的技术发展为脉络分别介绍了基于规则的语言模型、基于统计的语言模型和基于神经网络的语言模型三者的基本概念和原理。
引用#
[1] https://zh.wikipedia.org/zh-cn/图灵测试
[2] 吴军, 《数学之美》, 北京: 人民邮电出版社, 2014.
[3] https://en.wikipedia.org/wiki/Natural_language_processing
[4] https://en.wikipedia.org/wiki/Language_model
[5] Natural Language Processing with Deep Learning, Stanford CS224n, Winter 2022.
[6] 阿斯顿·张、李沐、扎卡里 C. 立顿等,动手学深度学习[M],2版. 北京:人民邮电出版社, 2019.
[7] Dan J, James M H. N-gram Language Models. Speech and Language Processing, 2013.
[8] https://en.wikipedia.org/wiki/N-gram_language_model
[9] Brants T, et al. Large Language Models in Machine Translation[J]. EMNLP-CoNLL 2007, 2017, 858–867.