8.2 TextRNN网络#
在7.2节内容中,我们详细介绍了如何通过RNN模型来完成文本分类任务,且当时使用的是one-hot编码形式来表示原始文本。在接下来的这节内容中,我们将会再次介绍基于RNN结构的文本分类模型TextRNN。准确来说TextRNN并不是一个某一个特定模型的名称,而是一系列以RNN模型为基础所构造的一类模型的总称。
8.2.1 TextRNN结构#
TextRNN模型的主要思想是通过循环神经网络结构将文本数据的每个词或字符作为输入,并在每个时间步骤中更新隐藏状态,以对整个序列进行特征提取。具体而言,TextRNN会先将文本序列通过一个嵌入层将one-hot编码形式的稀疏向量转换为稠密向量(Dense Vector)来表示每个词或字符;然后再将其输入到RNN中进行特征提取;最后再将提取得到的特征进行组合并完成后续的分类任务[1]。对于TextRNN模型,其整体结构如图8-2所示。
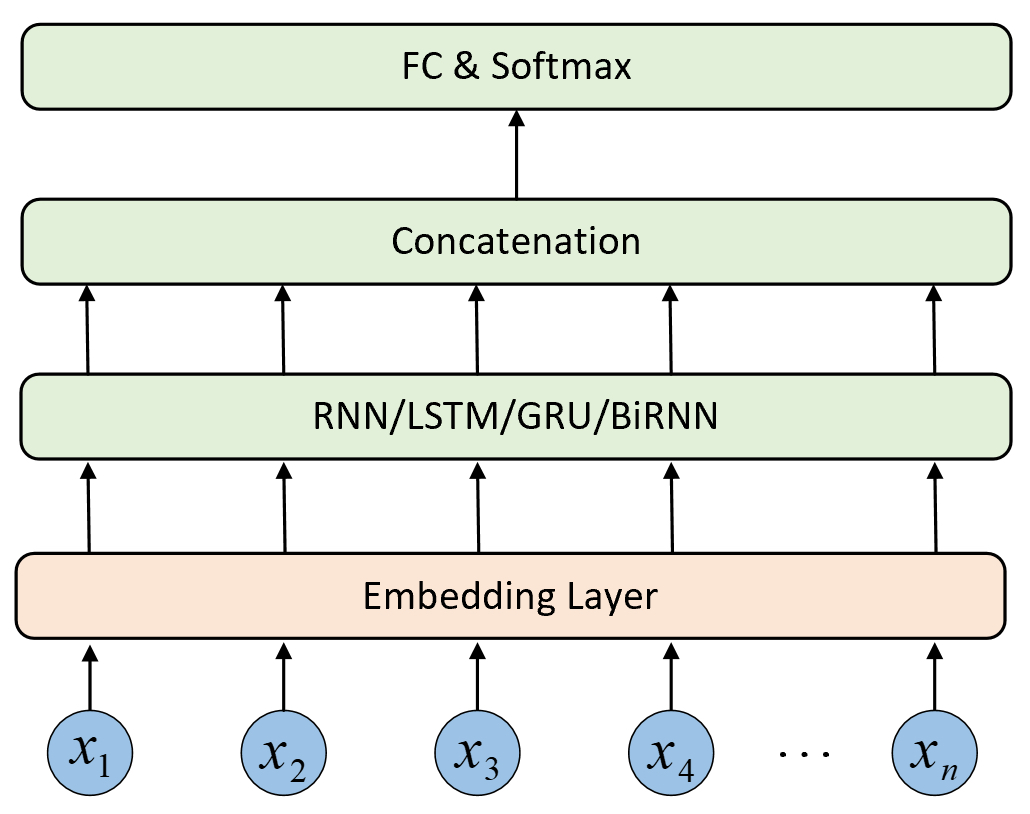
如图8-2所示,从下往上第1层是嵌入层;第2层的RNN层,既可以是原始RNN也可以是后续的各种变体LSTM、GRU和BiRNN等;第3层则是选取RNN的输出特征,既可以是只取最后一个时刻,也可以是取所有时刻的均值或者求和等;第4层则是最后的一个分类层。
8.2.2 TextRNN实现#
在清楚TextRNN模型的相关原理后,我们再来看如何借助PyTorch快速实现该模型。 以下完整示例代码可以参见Code/Chapter08/C02_TextRNN/TextRNN.py文件。
1. 前向传播
首先需要实现模型的整个前向传播过程。从图8-2可知,整个模型整体分为3个大的部分,词嵌入层、循环神经网络层和全连接,实现代码如下所示:
1 class TextRNN(nn.Module):
2 def __init__(self, config):
3 super(TextRNN, self).__init__()
4 if config.cell_type == 'RNN':
5 rnn_cell = nn.RNN
6 elif config.cell_type == 'LSTM':
7 rnn_cell = nn.LSTM
8 elif config.cell_type == 'GRU':
9 rnn_cell = nn.GRU
10 else:
11 raise ValueError("Unrecognized RNN cell type: " + config.cell_type)
12 out_hidden_size = config.hidden_size * (int(config.bidirectional) + 1)
13 self.config = config
14 self.token_embedding = nn.Embedding(config.top_k, config.embedding_size)
15 self.rnn = rnn_cell(config.embedding_size, config.hidden_size, num_layers=config.num_layers,
16 batch_first=True, bidirectional=config.bidirectional)
17 self.classifier = nn.Sequential(nn.LayerNorm(out_hidden_size),
18 nn.Linear(out_hidden_size, out_hidden_size),nn.ReLU(inplace=True),
19 nn.Dropout(0.5),nn.Linear(out_hidden_size, config.num_classes))在上述代码中,第2行中config表示一个实例化的配置类对象,通过这样的方式可以更便捷的管理模型参数,具体可参见5.1节内容。第4~11行是根据对应的参数返回相应的循环记忆单元。第12行是计算循环神经网络输出结的维度,即在双向结构中该维度为单向结构的2倍,具体可参见7.5.3节内容。第14行是实例化得到一个词嵌入层。第15~16行是根据对应参数实例化得到循环记忆单元。第17~19行则是由两个全连接构成的分类层。
进一步,整个前向传播计算过程的示例代码如下所示:
1 def forward(self, x, labels=None):
2 x = self.token_embedding(x)
3 x, _ = self.rnn(x)
4 if self.config.cat_type == 'last':
5 x = x[:, -1]
6 elif self.config.cat_type == 'mean':
7 x = torch.mean(x, dim=1)
8 elif self.config.cat_type == 'sum':
9 x = torch.sum(x, dim=1)
10 else:
11 raise ValueError("Unrecognized cat_type: " + self.cat_type)
12 logits = self.classifier(x)
13 if labels is not None:
14 loss_fct = nn.CrossEntropyLoss(reduction='mean')
15 loss = loss_fct(logits, labels)
16 return loss, logits
17 else:
18 return logits在上述代码中,第2行是词嵌入层的输出结果,形状为[batch_size, src_len, embedding_size]。第3行是RNN计算后的输出结果,形状为[batch_size, src_len, out_hidden_size]。第4~11行是根据不同的组合方式对循环神经网络的输出结果进行组合,形状为[batch_size, out_hidden_size]。第12行则是最后的分类层,输出结果形状为[batch_size, num_classes]。第13~18行则是根据条件返回对应的处理结果。
最后,可以通过如下方式来进行使用
1 class ModelConfig(object):
2 def __init__(self):
3 self.num_classes = 15
4 self.top_k = 8
5 self.embedding_size = 16
6 self.hidden_size = 512
7 self.num_layers = 2
8 self.cell_type = 'LSTM'
9 self.bidirectional = False
10 self.cat_type = 'last'
11
12 if __name__ == '__main__':
13 config = ModelConfig()
14 model = TextRNN(config)
15 x = torch.randint(0, config.top_k, [2, 3], dtype=torch.long)
16 label = torch.randint(0, config.num_classes, [2], dtype=torch.long)
17 loss, logits = model(x, label)
18 print(logits.shape) # torch.Size([2, 15])在上述代码中,第1~10行是参数配置定义类。第13~14行是分别实例化参数配置类和模型。第15~16行是构造输入和标签。第17~18行便是模型的输出结果。
2. 模型训练
由于这部分代码在之前也已经多次介绍过,因此这里也不再赘述,各位读者直接参考源码即可。最后,在对网络模型进行训练时将会得到类似如下的输出结果:
1 Epochs[1/50]--batch[0/1047]--Acc: 0.0664--loss: 2.7806
2 Epochs[1/50]--batch[50/2093]--Acc: 0.1953--loss: 2.5564
3 Epochs[1/50]--batch[100/2093]--Acc: 0.2188--loss: 2.4205
4 Epochs[1/50]--batch[150/2093]--Acc: 0.3711--loss: 2.1032
5 Epochs[1/50]--batch[200/2093]--Acc: 0.5508--loss: 1.5459
6 Epochs[1/50]--batch[250/2093]--Acc: 0.5625--loss: 1.4029
7 Epochs[1/50]--batch[300/2093]--Acc: 0.625--loss: 1.2464
8 Epochs[1/50]--batch[350/2093]--Acc: 0.6523--loss: 1.2429
9 Epochs[1/50]--Acc on val 0.7475
10 Epochs[8/50]--Acc on val 0.7922在实际实验过程中我们发现,尽管此处使用了更为复杂的词嵌入层和双向循环神经网络,但是最终在验证集上的表现结果却与7.2.4节中采用one-hot编码和单一RNN结构的结果类似;而此处如果将词粒度改为字粒度并使用嵌入层后准确率将会明显提升至$85\%$,这一结果读者可自行验证。因此在实际情况中,也可以多尝试不同情况下的组合来构建模型。
8.2.3 小结#
在本节内容中,我们首先介绍了TextRNN的基本思想,即一系列以RNN模型为基础所构造的一类模型的总称;然后详细介绍了模型具体的构造原理;最后一步一步介绍了如何从零实现TextRNN模型,并同时进行了实验示例。
引用#
[1] https://www.tensorflow.org/text/tutorials/text_classification_rnn