7.4 多项式朴素贝叶斯原理与实现#
在上一节内容中,我们详细介绍了一种常见的朴素贝叶斯算法,也被称之为Categorical Naive Bayes。但实际上,”朴素贝叶斯“算法远不止这一种,而它们之间的主要区别在于对条件概率的处理上[3],即式(7-10)中的$\prod{P}({{X}^{(i)}}={{x}^{(i)}}|Y={{c}_{k}})$部分。因此在接下来的这节内容中,我们将会介绍第2种基于朴素贝叶斯思想的分类模型,多项朴素贝叶斯(Multinomial Naive Bayes, MNB)。
7.4.1 算法思想#
在通过Categorical NB来进行文本分类的场景中,在计算条件概率时都是将词表中的每个词以是否出现为标准进行类别化(Categorization)处理,因此如果将词频作为特征维度的取值类别,那么将会出现在测试集中特征维度的取值情况数大于训练集中的情况。
例如在训练集中“客栈”这个词出现的最大次数为10,那么模型在拟合过程中就会认为“客栈”这个维度的特征取值有10种情况,并以此进行建模;但是当测试集中的某个样本里“客栈”这个词出现的频次为11时,那么模型便会认为该维度多了一种取值情况,进而无法取到对应的条件概率。
同时,在利用词袋模型对文本进行向量化表示时词频也是一个重要的考量因素,而多项朴素贝叶斯算法在处理这一问题时则是将每个维度的词频在总词频中的占比来作为条件概率进行建模[4]。
7.4.2 算法原理#
在MNB中,我们可以将类别$c_k$下条件概率的分布参数化为$\theta_{c_k}=(\theta_{c_k1},\theta_{c_k2}...,\theta_{c_kn})$这样的形式,其中$n$表示训练集中的特征维度(例如在文本分类中则是词表的长度),$\theta_{c_ki}$则是类别$c_k$下特征$i$的条件概率。进一步,参数$\theta_{c_k}$可以通过极大似然估计来计算得到[3]:
$$ \hat{\theta}_{c_ki}=\frac{N_{c_ki}+\alpha_i}{N_{c_k}+\alpha }\tag{7-26} $$其中$N_{c_ki}$表示在整个训练集$T$中样本属于$c_k$这个类别下特征$x^{(i)}$出现的频次,即$N_{c_ki}=\sum_{x\in T}x^{(i)}$;$N_{c_k}$表示类别$c_k$下所有维度特征的总频次,即$N_{c_k}=\sum_{i=1}^nN_{c_ki}$;$\alpha_i$表示每个特征维度对应的平滑系数,$\alpha$表示所有平滑系数的总和[4]。但是在实际处理时通常会将每个维度的平滑系数设为相等,因此式(7-26)可以改写为:
$$ \hat{\theta}_{c_ki}=\frac{N_{c_ki}+\alpha}{N_{c_k}+\alpha n }\tag{7-27} $$其中$\alpha$表示每个特征维度的平滑系数。
在根据式(7-27)估计得到每个类别下各个特征的条件概率(词频占比)后,便可以通过式(7-10)来最大化后验概率以此确定样本的分类类别。但是这里存在一个问题,那就是通过式(7-10)可以知道,在最大化后验概率时各个特征维度的条件概率是进行的累乘操作,而在动则上千维的文本向量中,这样累乘计算得到的结果将会出现下溢的情况。
因此,常见的一种做法是在式(7-10)的两边同时取自然对数$\log$,且由于$\log$函数是单调的因此这并不影响最终的预测结果[5]。所以式(7-10)可以改写为如下形式
$$ \hat{y} = \arg\max_{c_k} \log{\left(P(Y=c_k)\prod\limits_{i=1}^{n}{P}({{X}^{(i)}}|Y={{c}_{k}})\right)}\tag{7-28} $$其中${P}({{X}^{(i)}}|Y={{c}_{k}})$表示在类别$Y=c_k$下特征$X^{(i)}$对应的条件概率。
进一步,根据$\log(xy)=\log(x)+\log(y)$,式(7-28)可以改写为
$$ \hat{y} = \arg\max_{c_k} \left(\log P(Y=c_k) +\sum_{i=1}^n\log P({{X}^{(i)}}|Y={{c}_{k}})\right)\tag{7-29} $$同时对于MNB算法来说,从式(7-27)可以看出,此时条件概率计算的是训练集中特征维度的词频占比(相当于模型参数),因此在最终计算后验概率时需要同时考虑到每个维度的词频情况,即[4]
$$ \hat{y} = \arg\max_{c_k} \left(\log P(Y=c_k) +\sum_{i=1}^nf_i\log P({{X}^{(i)}}|Y={{c}_{k}})\right)\tag{7-30} $$其中$f_i$表示特征维度$i$对应的词频。
此时根据式(7-30)的形式来看,还可以将$\log P({{X}^{(i)}}|Y={{c}_{k}})$理解为特征$x^{(i)}$在对应类别下重要性大小的权重,而先验概率$\log P(Y=c_k)$则可以理解为数据集中各类别的相对频次(偏置),频次越大则当前样本越可能归属于该类别。因此,从这个角度看还可以将多项贝叶斯理解一个简单的线性模型。也正是因为这样的特性,MNB算法在处理TFIDF这类文本特征表示时依旧有着很好的效果[3]。
到此,对于多项贝叶斯算法的基本原理就介绍完了,下面我们再来通过一个实际的计算示例来帮助大家更加清晰地理解。
7.4.3 计算示例#
假设现在有一批基于词袋模型表示的文本数据,其一共包含有$X^{(1)},X^{(2)},X^{(3)}$这3个特征维度,每个维度表示词表中相应词的词频,$Y$表示样本对应的所属类别,如表7-2所示。现需要预测$x=[17,25,39]$这个样本的所属类别。
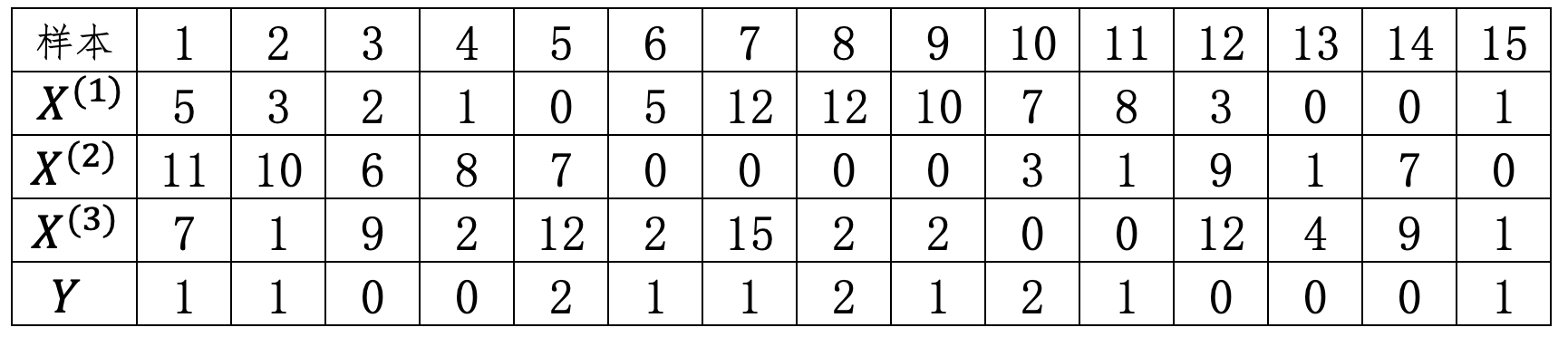
根据式(7-30),由表7-2易知,各个类别先验概率的$\log$取值为
$$ \begin{aligned} \log P(Y=0)&=\log(\frac{5}{15})\approx-1.098\\[1ex] \log P(Y=1)&=\log(\frac{7}{15})\approx-0.762\\[1ex] \log P(Y=2)&=\log(\frac{3}{15})\approx-1.609 \end{aligned}\tag{7-31} $$各类别下不同特征取值的条件概率的$\log$取值为(设$\alpha=1$,即拉普拉斯平滑)
$$ \log P(X^{(1)}|Y=0)=\log(\frac{2+1+3+0+0+1}{17+11+24+5+16+1\cdot3})\approx-2.384\tag{7-32} $$其中分子中的$2,1,3,0,0$表示在$Y=0$这个类别下,特征$X^{(1)}$出现的总频次;分母$17,11,24,5,16$分别表示在$Y=0$这个类别下所有特征维度的总频次,例如$17=2+6+9$。同时,从这里也可以再次看出MNB算法在计算特征维度时考虑的是类别$Y=c_k$中所有样本当前各个特征维度的频次总数在类别$Y=c_k$中所有样本的所有特征维度总频次中的占比,这样便能够计算得到对于类别$Y=c_k$来说哪个特征维度的重要性更高。