3.4 Qwen3 Embedding 模型介绍#
在完成 Milvus 向量数据库的安装以后,下一步我们将开始介绍如何使用千问 Qwen3 Embedding 系列词嵌入模型来对文本进行向量化。下面先直接介绍其使用方法,然后再对其中的原理做一个简单地介绍,以便更好地设置相关参数获得合适的词向量结果。
3.4.1 DashScopeEmbeddings 使用示例#
在第2.4节内容中,我们已经简单介绍了通过 dashscope 原生 SDK、OpenAI SDK 以及 langchain_community 的方式来使用 Qwen3 Embedding 模型的使用方法。总结起来就是,直接使用 dashscope 原生 SDK 这种方式能够获得 Embedding 完整的能力, langchain_community 其次,OpenAI SDK 则最差只能使用基本功能。
之所以会有不同的途径来使用 Qwen3 Embedding 模型,本质原因还是我们在上一章提到的先入为主,以及为了适配其它集成框架,如 LangChain 生态。
在后续介绍中,我们也将使用 langchain_community.embeddings 模块中的 DashScopeEmbeddings 模块来完成文本的向量化过程,这是千问专门为适配 LangChain 生态所开发的。同时,整个向量化过程已经被 LangChain 高度集成,不用我们手动去转换每一篇文档,这也是使用 LangChain 开发 RAG 的便携之处。
通过 LangChain 访问 dashscope 访问方式如下:
1 def test_LangChain_dashscope_embedding(input_text):
2 from langchain_community.embeddings import DashScopeEmbeddings
3 embeddings = DashScopeEmbeddings(model="text-embedding-v4")
4 print("test_LangChain_dashscope_embedding")
5 query_result = embeddings.embed_query(input_text[0])
6 print(query_result)
7 doc_results = embeddings.embed_documents(input_text)
8 print(doc_results)在上述代码中,第3行是实例化一个类对象,并且指定 Embedding 模型为 text-embedding-v4,它是属于Qwen3-Embedding 系列,也是目前千问最好的文本向量模型,支持维度有 2048、1536、1024(默认)、768、512、256、128、64这些。不过通过 DashScopeEmbeddings 只能使用默认的 1024 维度,这也就是我们之前所说的非官方 SDK 的限制。
第5、7行代码,则是分别用于对查询和文档进行向量化,不同的 Embedding 模型背后实现的方式并不一样,下文将进行介绍。
上述代运行结束以后的输出结果为:
[-0.0863448828458786, 0.0336710587143898, 0.030886666849255562, ...]
[[-0.0863448828458786, 0.0336710587143898, 0.030886666849255562, ...],
[-0.08091967552900314, -0.012189434841275215, -0.0039899577386677265, ...]]3.4.2 Qwen3 Embedding 原理#
Qwen3 Embedding 系列模型是专为文本表征、检索与排序任务而设计,它基于 Qwen3 基座模型所训练,充分继承了 Qwen3 在多语言文本理解能力方面的优势[1]。
Qwen3 Embedding 模型在编码时接收单段文本作为输入,取模型最后一层[EOS]标记对应的隐藏状态向量,作为输入文本的语义表示,整个过程如图3-5所示。
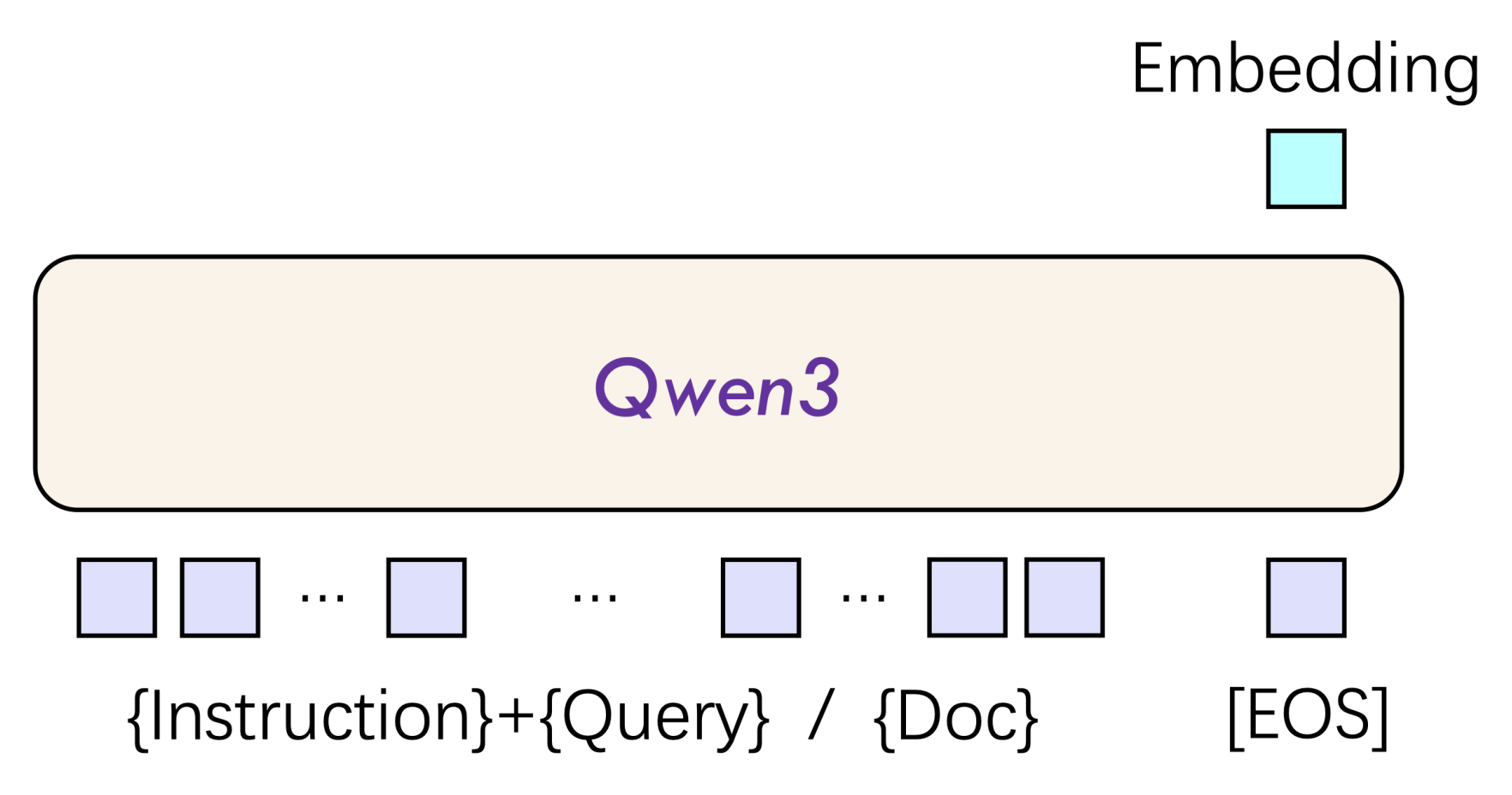
同时,为了在搜索类任务中取得最佳效果,Qwen3 Embedding 模型还支持对不同的内容进行有针对性的向量化处理,也就是图1中输入所示。
例如在 RAG 文档入库阶段,我们可以直接将对应的文本转化为向量;而在用户提问检索阶段,我们则可以将指令与用户提问 Query 拼接到一起作为输入,然后让 Embedding 模型返回对应的向量,最后去向量库中检索。
这样模型在编码 Query 时不再只是“语义理解”,而是“为检索目的做语义表达”。也就是说,Query 向量是可以根据不同指令而改变的,不同的指令也让 Query 向量投影到了不同的子空间中。例如:用于检索、用于分类、用于相似度计算等等,虽然底层模型一样,但最后 Query 的表示会不同。
3.4.3 Dashscope 使用示例#
在通过阿里云百炼的 Dashscope 调用 Embedding 的时候,我们可以通过参数 text_type 来控制生成不同类型的 Embedding 向量,示例如下:
1 resp = dashscope.TextEmbedding.call(
2 model="text-embedding-v4",
3 input="机器学习的相关论文",
4 text_type="query",
5 instruct="Given a research paper query, retrieve relevant research paper")同时,如果 instruct 参数为空,那么不管 text_type 是 "query" 还是 "document",最后返回的结果都是一样的。尽管这一点官方文档没有明确说明,但是我们可以通过计算两个向量的余弦相似度自行验证:
1 def test_dashscope_embedding():
2 input_text = ["机器学习是什么?深度学习又是什么?"]
3 from dashscope import TextEmbedding
4 resp1 = TextEmbedding.call(model="text-embedding-v4", text_type="query",
5 dimensions=1024, input=input_text[0])
6 v_query = np.array(resp1["output"]["embeddings"][0]["embedding"])
7
8 resp2 = TextEmbedding.call(model="text-embedding-v4", text_type="document",
9 dimensions=1024, input=input_text)
10 v_document = np.array(resp2["output"]["embeddings"][0]["embedding"])
11 cos_sim = np.dot(v_query, v_document) /
12 (np.linalg.norm(v_query) * np.linalg.norm(v_document))
13 print(cos_sim,np.linalg.norm(v_query),np.linalg.norm(v_document))
14
15 resp1 = TextEmbedding.call(model="text-embedding-v4", text_type="query",
16 dimensions=1024, input=input_text[0],
17 instruct="Given a research paper query, retrieve relevant research paper")
18 v_query = np.array(resp1["output"]["embeddings"][0]["embedding"])
19 cos_sim = np.dot(v_query, v_document) /
20 (np.linalg.norm(v_query) * np.linalg.norm(v_document))
21 print(cos_sim)
22 print(resp1["usage"]) # {'total_tokens': 26}在上述代码中,我们首先比较了同一个输入,分别使用 text_type="query" 和 text_type="document" 两种模式来向量化,并计算两者的余弦相似度,即第4~13行。然后,比较了加指令后生成的向量与text_type="document" 模式下的向量的相似度。
上述代码运行结束后的输出结果为:
1.0 1.0000000080061002 1.0000000080061002
0.8773372034726875
{'total_tokens': 26}从输出结果可以看出, text_type="query" 和 text_type="document" 两种模式下生成向量的模长均为1,余弦相似度也为1,这就意味着这两个向量是完全一样的。不过在使用中还是可以自行加上,没准哪天可能官方 API 就做了更新。
这里需要注意的是,按照官方文档说法提供的指令需要为英文,且使用此功能时,必须将 text_type 参数设置为 query [2]。
3.4.4 指令拼接#
这里,我们还可以根据千问在 github 上公布的示例代码 [3],来手动拼接指令和输入,示例代码如下:
1 def embedding_token_construct():
2 def get_detailed_instruct(task_description: str, query: str) -> str:
3 return f'Instruct: {task_description}\nQuery:{query}'
4
5 task = 'Given a research paper query, retrieve relevant research paper'
6 queries = [get_detailed_instruct(task, '机器学习是什么?深度学习又是什么?')]
7 print(f"拼接后的输入为: {queries}")
8 tokenizer = AutoTokenizer.from_pretrained(data_info.QWEN3_EMBEDDING_06B_DIR, padding_side='left')
9 batch_dict = tokenizer(queries, padding=True, truncation=True, max_length=8192, )
10 for i in range(len(batch_dict['input_ids'])):
11 for _, token_id in enumerate(batch_dict['input_ids'][i]):
12 token_str = tokenizer.decode([token_id], skip_special_tokens=False)
13 print(f"{token_id:6d} -> {repr(token_str)}")
14 print(f"Token 数量 = {len(batch_dict['input_ids'][i])}")在上述代码中,第2行是将输入和任务指令拼接到一起。第8~9行则是进行 tokenize 操作。第10~14行是我们将 Token ID 转换成 Token,也可以顺便查看 tokenize 后的结果。
上述代码运行结束后将会看到类似如下结果:
# 拼接后的输入为: ['Instruct: Given a research paper query, retrieve relevant research paper\nQuery:机器学习是什么?深度学习又是什么?']
# 641 -> 'In'
# 1235 -> 'struct'
# 25 -> ':'
# 16246 -> ' Given'
# 264 -> ' a'
# 3412 -> ' research'
# 5567 -> ' paper'
# 3239 -> ' query'
# 11 -> ','
# 17179 -> ' retrieve'
# 9760 -> ' relevant'
# 3412 -> ' research'
# 5567 -> ' paper'
# 198 -> '\n'
# 2859 -> 'Query'
# 25 -> ':'
# 102182 -> '机器'
# 100134 -> '学习'
# 102021 -> '是什么'
# 11319 -> '?'
# 102217 -> '深度'
# 100134 -> '学习'
# 99518 -> '又'
# 102021 -> '是什么'
# 11319 -> '?'
# 151643 -> '<|endoftext|>'
# Token 数量 = 26从输出结果我们可以清晰的看到每个 Token 到底是长什么样的。同时,值得一提的是在 Qwen3 Embedding 中,Embedding 时会在输入最后拼接上 '<|endoftext|>' 这个 Token,并且取它对应的向量作为整个句子的向量表达。
以上完整示例代码可参见 Code/Chapter03/C10_qwen_embedding.py 文件。
3.4.5 DashScopeEmbeddings 实现#
在经过上面内容介绍以后,相信大家应该已经对上面 DashScopeEmbeddings 模块中的 embeddings.embed_query() 和 embeddings.embed_documents() 之间的区别有了一定的理解。没错,这两个方法就是分别针对请求和原始文档进行向量化的。所有适配 LangChain 框架的 Embedding 模型,例如 OpenAIEmbeddings 和DashScopeEmbeddings,都有这两个方法,但是内部具体的实现却不同。
在 DashScopeEmbeddings 类中,embed_query() 和 embed_documents() 的实现如下:
1 def embed_documents(self, texts: List[str]) -> List[List[float]]:
2 embeddings = embed_with_retry(
3 self, input=texts, text_type="document", model=self.model)
4 embedding_list = [item["embedding"] for item in embeddings]
5 return embedding_list
6
7 def embed_query(self, text: str) -> List[float]:
8 embedding = embed_with_retry(
9 self, input=text, text_type="query", model=self.model)[0]["embedding"]
10 return embedding从这里可以看出,embed_query() 和 embed_documents()的差异在于 text_type 参数的值不一样。不过根据我们在第2.2节中的介绍可以发现,目前为止 text_type="query" 和 text_type="document" 对于同样的文本返回的向量都是一样。同时,由于 embed_query() 这个方法也无法直接传入 Instruct 这个参数,所以本质上两者是一样的。
当然,根据需要我们也可以修改这部分代码,使得在对 Query 向量化的时候可以使用指令模式。
这里顺便提一下在 OpenAIEmbeddings 类中,embed_query() 和 embed_documents() 的实现如下:
1 def embed_query(self, text: str) -> List[float]:
2 return self.embed_documents([text])[0]
3
4 def embed_documents( self, texts: List[str],
5 chunk_size: Optional[int] = 0) -> List[List[float]]:
6 engine = cast(str, self.deployment)
7 return self._get_len_safe_embeddings(
8 texts, engine=engine, chunk_size=chunk_size)从上述代码我们可以发现,OpenAI 的实现方式更加简单。
引用#
[1] https://qwen.ai/blog?id=qwen3-embedding
[2] https://bailian.console.aliyun.com/cn-beijing/?tab=doc#/doc/?type=model&url=2842587
[3] https://github.com/QwenLM/Qwen3-Embedding
[4] Zhang Y, Li M, Long D, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models[J]. arXiv preprint arXiv:2506.05176, 2025.