8.2 决策树建模与可视化#
在清楚决策树算法背后的思想以后,我们再来看如何利用sklearn进行建模并对构建完成的决策树可视化。下面依旧以前面介绍的iris数据集为例来进行建模,以下完整示例代码可参见 AllBooKCode/Chapter08/C02_decision_tree_gini.py 文件。
8.2.1 ID3 算法示例代码#
在sklearn中可以通过sklearn.tree下的DecisionTreeClassifier类模块来完成整个决策树算法的建模。下面,我们首先来对类DecisionTreeClassifier中的几个常用参数进行简单介绍,详细原理将在下一节内容中进行介绍,示例代码如下:
1 def __init__(self, criterion="gini", splitter="best", max_depth=None,
2 min_samples_split=2, min_samples_leaf=1, max_features=None,
3 min_impurity_split=None): 在上述代码中,第1行criterion用来选择划分时的度量标准,当criterion取值为"entropy"或"gini"时分别表示使用信息增益或基尼不纯度作为划分指标; splitter用来选择节点划分时的特征选择策略,当splitter="best"时,则每次节点进行划分时均在所有特征中通过度量标准来选择最优划分方式,而当splitter="random"时,则每次节点进行划分时只会随机地选择max_features个特征,并在这些特征上选择最优的划分方式; max_depth表示决策树的最大深度,默认为None表示直到所有叶子节点的样本均为同一类别或者样本数小于min_samples_split时停止划分。第2行min_samples_leaf用来指定构成一个叶子节点所需要的最少样本数,即如果划分后叶子节点中的样本数小于该阈值,则不会进行划分; min_impurity_split用来提前停止节点划分的阈值,默认为None,即无阈值。
1. 载入数据集
在介绍完类DecisionTreeClassifier的基本用法后,便可以通过其来完成决策树的生成。首先需要载入训练模型时所用到的数据集,同时为了后续更好地观察可视化后的决策树,这里也要返回各个特征的名称,代码如下:
1 def load_data():
2 data = load_iris()
3 X, y = data.data, data.target
4 feature_names = data.feature_names
5 X_train, X_test, y_train, y_test = \
6 train_test_split(X, y, test_size=0.3, random_state=42)
7 return X_train, X_test, y_train, y_test, feature_names在上述代码中,第4行代码便是得到特征维度的名称,其结果为
['sepal length(cm)','sepal width(cm)','petal length (cm)','petal width (cm)'] 2. 训练模型
在完成数据载入后,便可通过类DecisionTreeClassifier来完成决策树的生成。这里除了指定划分标准为'entropy'之外(使用ID3算法),其他参数保持默认即可,示例代码如下:
1 def train(X_train, X_test, y_train, y_test, feature_names):
2 model = tree.DecisionTreeClassifier(criterion='entropy')
3 model.fit(X_train, y_train)
4 print("在测试集上的准确率为:",model.score(X_test, y_test))训练完成后,可以得到模型在测试集上的准确率为
在测试集上的准确率为: 1.08.2.2 决策树可视化#
当拟合完成决策树后,还可以借助第三方工具graphviz[4]对生成的决策树进行可视化。具体地,需要下载页面中Windows环境下的ZIP压缩包graphviz2.46.1win32.zip。在下载完成并解压成功后,可以得到一个名为Graphviz的文件夹。接着将文件夹Graphviz中的bin目录添加到环境变量中。步骤为右击“此计算机”,单击“属性”,再单击“高级系统设置”,继续单击“环境变量”,最后双击系统变量里的Path变量,新建一个变量并输入Graphviz中bin的路径即可,例如我们添加时的路径为C:\graphviz2.46.1win32\Graphviz\bin。添加环境变量后,再安装graphviz包即可完成可视化的前期准备工作,安装命令为
pip install graphviz要实现决策树的可视化,只需要在8.2.1节中train()函数后添加如下代码:
1 dot_data = tree.export_graphviz(model, out_file=None,
2 feature_names=feature_names, filled=True,rounded=True,
3 special_characters=True)
4 graph = graphviz.Source(dot_data)
5 graph.render('iris')在整个代码运行结束后,便会在当前目录中生成一个名为iris.pdf的文件,这就是决策树可视化后的结果,如图8-4所示。
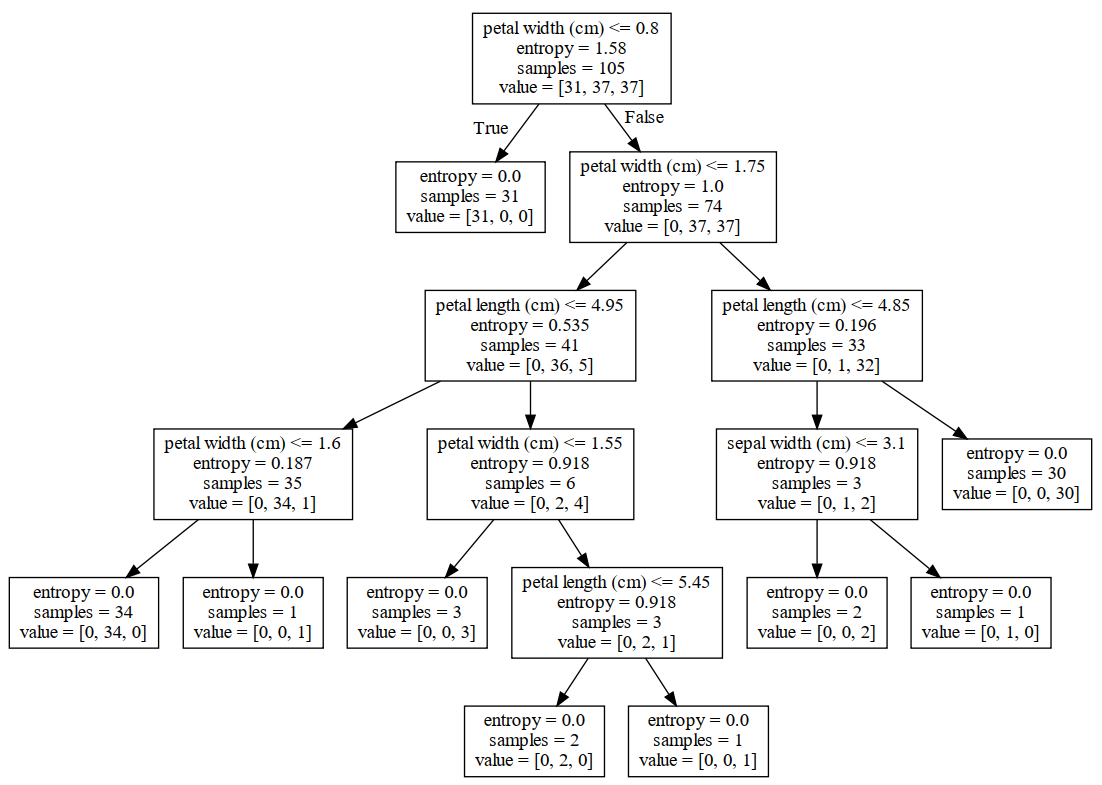
在图8-4中,samples表示当前节点的样本数,value为一个列表,表示每个类别对应的样本数。从图中可以看出,随着决策树不断向下分裂,每个节点对应的信息熵总体上也在逐步减小,直到最终变成0。
8.2.3 小结#
在本节中,我们首先介绍了类DecisionTreeClassifier的使用方法,包括其中一些常见的重要参数及其含义;接着介绍了如何根据现有的数据集来训练一个决策树模型;最后介绍了如何利用开源的graphviz工具实现决策树的可视化。