10.4 SVM中的软间隔#
在前面几节内容中,我们分别介绍了什么是支持向量机及如何通过sklearn来完成整个SVM的建模过程,然后还介绍了什么是线性不可分与核函数的用法。在接下来的这节内容中,我们将继续介绍SVM中的软间隔及其在sklearn中的示例用法。
10.4.1 软间隔定义#
在10.2节和10.3节中,我们分别介绍了以下两种情况的分类任务: ①原始样本线性可分; ②原始样本线性不可分,但通过核函数映射到高维空间之后“线性可分”。为什么后面这个“线性可分”要加上引号呢?这是因为在10.3节中其实有一件事没有和各位读者交代,即虽然通过将原始样本映射到高维空间的方法能够很大程度上使原本线性不可分的样本点线性可分,但是这并不能完全保证每个样本点都是线性可分[1]的。或者保守点说,即使完全线性可分了,但也极大可能会出现过拟合现象。这可能是因为超平面对于异常点过于敏感,或者数据本身的属性所造成的,如图10-9所示。
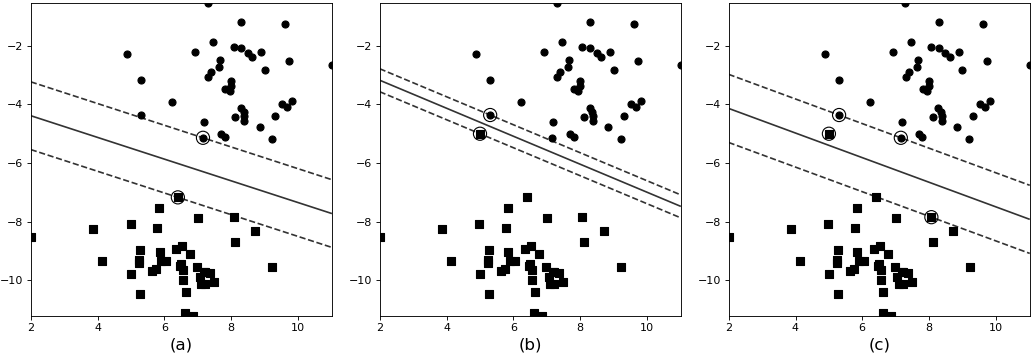
在图10-9中,实线为相应的决策面,黑色方块和黑色圆点分别为两个类别的样本。在图10-9(a)中,通过SVM建模得到的决策面已经完美地将两种类别的样本点进行了区分,但是,如果此时训练样本中加入一个异常点,并且继续用SVM建模求解,则将会得到图10-9(b)中所示的分类决策面。可以发现,虽然此时决策面也成功地区分开了每个样本点,但是相较于图10-9(a)中的决策面却发生了剧烈的摆动,决策面到支持向量的距离也变得十分狭窄。
在SVM中,将图10-9(a)和图10-9(b)中决策面到支持向量的间隔称为硬间隔(Hard Margin),即不允许任何样本出现错分的情况,即使可能导致过拟合。当然,理想情况下期望的应该是图10-9(c)中的这种情况,容许少量样本被错分从而得到一个次优解,而这个容忍的程度则通过目标函数来调节。或者再极端一点就是根本找不到一个超平面能够将样本无误地分开,必须错分一些样本点。此时图10-9(c)中决策面到支持向量的间隔便被称为软间隔(Soft Margin)。
10.4.2 最大化软间隔#
从上面的介绍可知,如数据集中出现了异常点,则必将导致该异常点的函数间隔小于1,所以可以为每个样本引入一个松弛变量(${{\xi }_{i}}\ge 0$)来使函数间隔加上松弛变量大于或等于1。
$$ {{y}^{(i)}}({{w}^{T}}{{x}^{(i)}}+b)\ge 1-{{\xi }_{i}}\tag{10-21} $$此时的目标函数可以重新改写为如下形式
$$ \begin{aligned} & \underset{w,b,\xi }{\mathop{\min }}\,\frac{1}{2}||w|{{|}^{2}}+C\sum\limits_{i=1}^{m}{{{\xi }_{i}}} \\[2ex] \text{s}.\text{t}. \ & {{y}^{(i)}}({{w}^{T}}{{x}^{(i)}}+b)\ge 1-{{\xi }_{i}},\ \ {{\xi }_{i}}\ge 0,\ i=1,2,...m \end{aligned}\tag{10-22} $$其中,$C>0$称为惩罚系数,$C$越大对误分类样本的惩罚就越大,类似于正则化中的参数$\lambda$。可以发现,只要错分一个样本点,目标函数都将付出$C\xi_i$的代价,并且为了使得目标函数尽可能小,就需要整个惩罚项相对小,因此,如果使用较大的惩罚系数,则将会得到较窄的分类间隔,即惩罚力度大允许错分的样本数就会减少。如果使用较小的惩罚系数,则会得到相应较宽的分类间隔,即惩罚力度小允许错分的样本数量就会增多。
10.4.3 SVM软间隔示例代码#
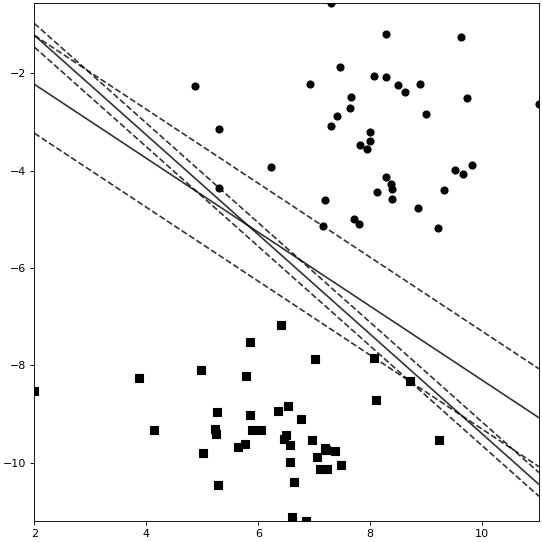
在10.2.3节内容中,我们大致列出了SVM分类器中常见的几个重要参数,其中$C$表示式(10-22)中的惩罚系数,它的作用是用来控制容忍决策面错分样本的程度,其值越大则模型越偏向于过拟合。如图10-10所示,此决策平面为$C$在不同取值下的决策面(分类间隔较大时$C=1$,分类间隔较小时$C=1000$)。参数gamma为核函数系数,使用默认值即可;coef0为多项式核和sigmoid核中的常数$r$,详细内容可参见10.8节内容。
下面我们将采用网格搜索的方式来选择一个最佳的SVM分类器对数据集iris进行分类。从上面对sklearn中SVM的API的介绍可知,SVC中需要用到的超参数有5个,这里其取值分别设为'C':np.arange(1, 10, 5)、'Kernel':['rbf','linear','poly']、'degree':np.arange(1, 10, 2)、'gamma':['scale','auto']、'coef0':np.arange(-10, 10, 5)。由此便有2×3×5×2×4=240个备选模型。同时,这里以3折交叉验证进行训练,则一共需要拟合720次模型。完整示例代码可参见 AllBooKCode/Chapter10/C10_soft_margin_svm.py 文件。
1. 模型选择
首先,需要根据列举出的超参数在数据集上根据交叉验证搜索得到最优超参数组合,示例代码如下:
1 def model_selection(x_train, y_train):
2 model = SVC()
3 paras = {'C': np.arange(1, 10, 5),
4 'kernel': ['rbf', 'linear', 'poly'],
5 'degree': np.arange(1, 10, 2),
6 'gamma': ['scale', 'auto'],
7 'coef0': np.arange(-10, 10, 5)}
8 gs = GridSearchCV(model, paras, cv=3, verbose=2, n_jobs=3)
9 gs.fit(x_train, y_train)
10 print('best score:', gs.best_score_,'best parameters:', gs.best_params_)在完成超参数搜索后,便能够得到一组最优的参数组合,输出结果如下:
1 Fitting 3 folds for each of 240 candidates, totalling 720 fits
2 [CV] END ..C=1, coef0=-10,degree=1,gamma=scale,kernel=rbf;total time= 0.0s
3 [CV] END ..C=1, coef0=-10,degree=1,gamma=scale,kernel=rbf;total time= 0.0s
4 …
5 [CV] END ...C=6, coef0=5, degree=9,gamma=auto,kernel=rbf; total time= 0.5s
6 best score: 0.986
7 best parameters: {'C': 6, 'coef0': -10, 'degree': 1, 'gamma': 'scale', 'kernel': 'rbf'}从上面的结果可以看出,当惩罚系数C=6及选取高斯核函数时对应的模型效果最好,准确率为0.986,并且由于最后选取的是高斯核,所以此时coef0和degree这两个参数无效。
2. 训练与预测
在通过网格搜索找到对应的最优模型后,可以再次以完整的训练集对该模型进行训练,示例代码如下:
1 def train(x_train, x_test, y_train, y_test):
2 model = SVC(C=6, kernel='rbf',gamma='scale')
3 model.fit(x_train, y_train)
4 score = model.score(x_test, y_test)
5 y_pred = model.predict(x_test)
6 print("测试集上的准确率: ", score)# 0.985可以看出,此时模型在测试集上的准确率约为0.985。当然,如果有需要,则可以将训练好的模型进行保存以便于后期复用,具体方法可参见6.2节内容。
10.4.4 小结#
在本节内容中,我们首先介绍了什么是软间隔及其原理,然后以iris分类数据集为例,再次介绍了在sklearn中如何用网格搜索来寻找最佳的模型参数。在接下来的几节内容中,将首先和读者一起回顾一下好久不见的拉格朗日乘数法,然后介绍求解模型参数需要用到的对偶问题,最后便是SVM的整个优化求解过程。