6.5 组归一化#
在前面两节内容中我们分别介绍了批归一化和层归一化这两种归一化算法所提出的动机和原理,其中层归一化提出的原因之一便是为了解决批归一化不能直接用于循环神经网络的弊端。然而,由于批归一化在计算过程中会受到小批量样本数量的影响,因此在大规模数据集中当小批量样本数量急剧减少时将会使得模型的效果显著下降。在样的背景下,组归一化(Group Normalization)[1]便应运而生了。
6.5.1 组归一化动机#
在卷积神经网络中,由于批归一化的提出使得模型的效果和收敛速度有了大幅地提升。根据式(6-15)和式(6-16)可知,批归一化在估计均值和方差时均会受到样本数量即批大小的影响,总体上样本数量越多则估计得到的均值和方差越接近于其真实值。然而,在一些大型数据集的图像处理任务中,如基于微软上下文通用对象(Microsoft Common Objects in Context, MS COCO)数据集[2]的目标检测、语义分割任务等,受限于计算机硬件存储的限制模型并不能够使用较大数量的小批量样本。
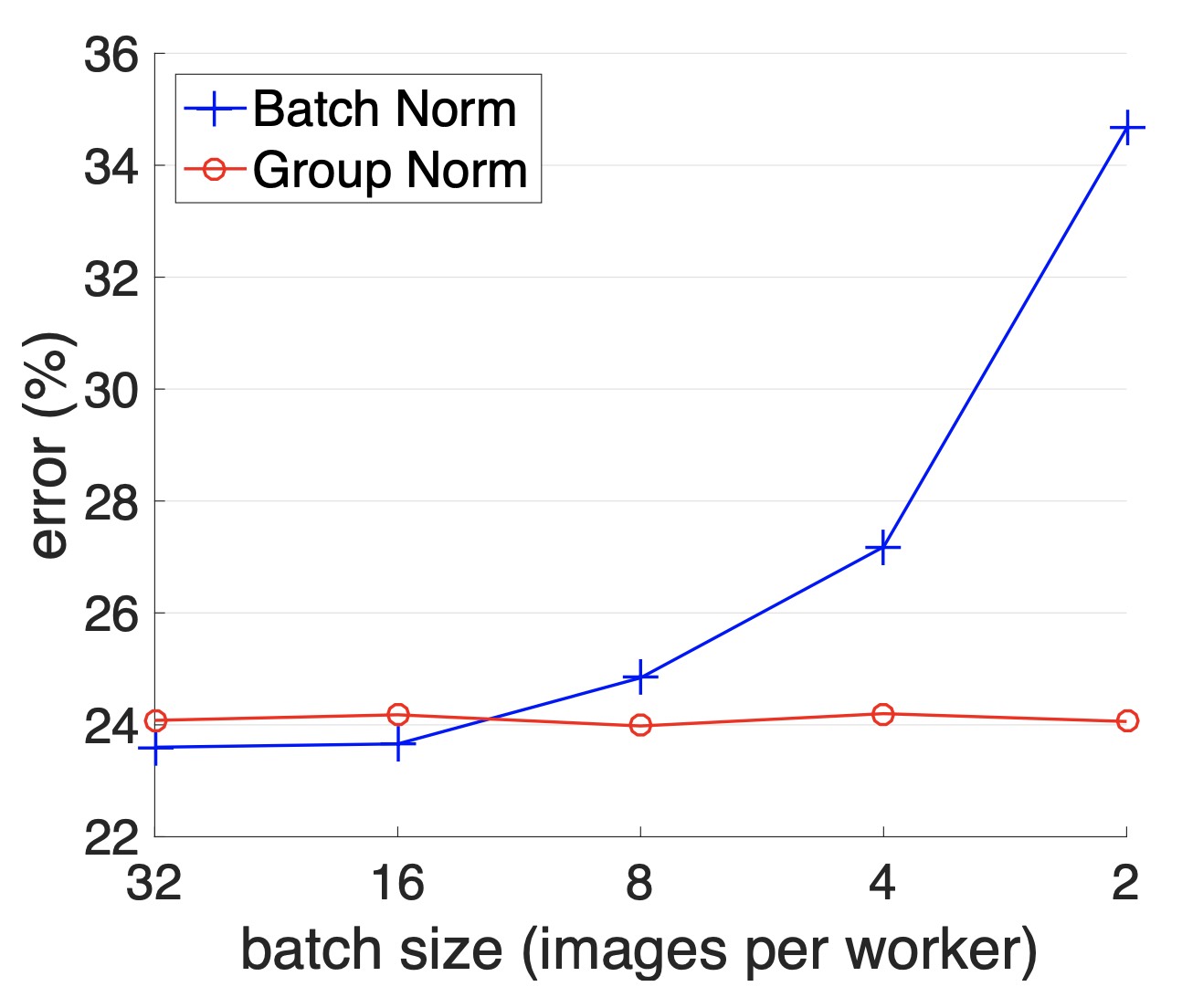
如图6-19所示,两条这先分别是基于批归一化和组归一化的ResNet50模型在ImageNet数据集上小批量大小随分类误差率的变化曲线。从图中可以明显看出,随着小批量中样本数量减少,基于批归一化的ResNet50在分类错误率上有了显著地增加,而基于组归一化的ResNet50错误率则相对稳定。当小批量样本减少至2时,两者的误差率扩大到了10个百分点。
6.5.2 组归一化原理#
从归一化的计算过程来看,组归一化与6.4节内容中层归一化的计算过程类似,即根据式(6-15)~式(6-18)所示先计算均值和方差,然后进行标准化,最后再进行缩放和平移,两者唯一的区别在于层归一化是同时对一个样本中的所有通道进行标准,而组归一化则是先将通道分成多个组在进行归一化,如图6-20所示便是两者在对卷积特征进行归一化时的差异之处。
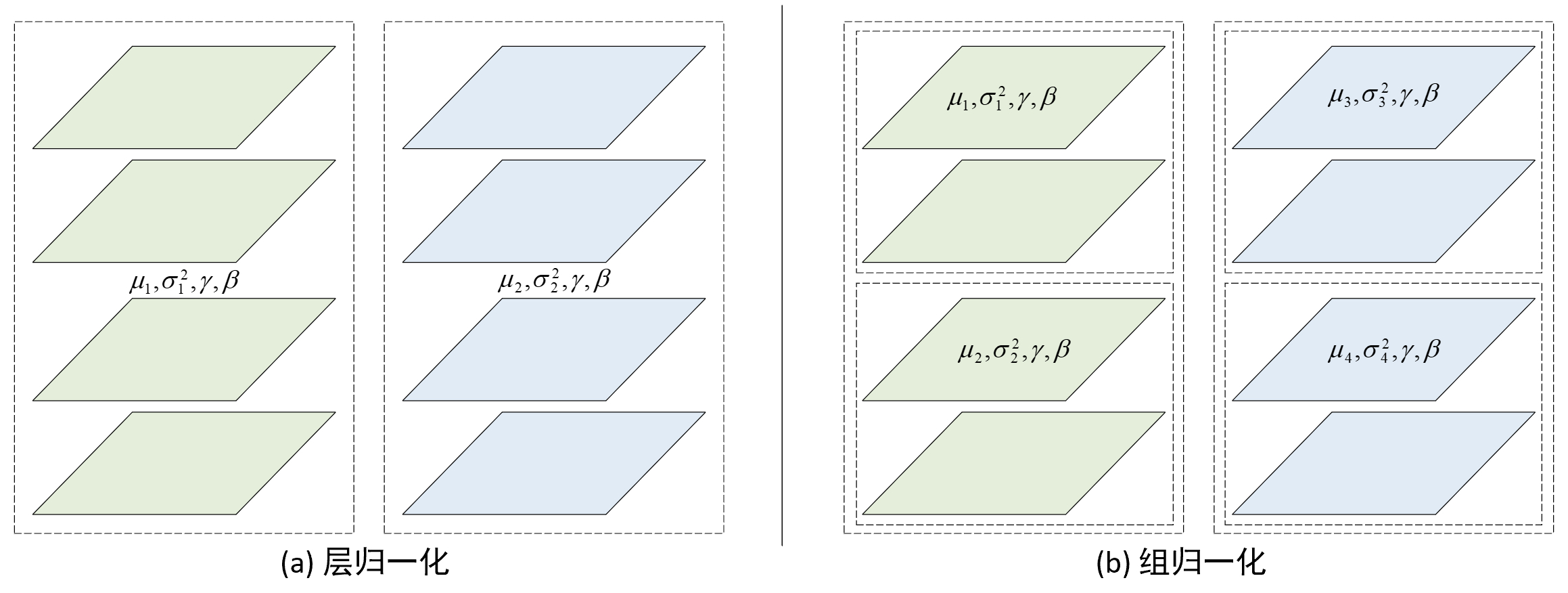
如图6-20所示,左右两边为分别是层归一化和组归一化的计算示意图,其一共包含有2个样本和4个特征通道。从图6-20(a)可以看出,层归一化在进行标准化时是将每个样本看做一个整体,并同时对所有通道进行标准化;对于图6-20(b)中的组归一化来说,它同样是将每个样本看做一个整体,但是需要将特征通道划分成若干组(此处为2组),然后在每一组特征中以层归一化的方式进行。因此,在组归一化中如果分组数量为1时那么便等价于层归一化操作。此时需要注意的是,在组归一化中每个样本特征通道分组内均有各自独立的均值$\mu_i$和方差$\sigma^2_i$(2个值均为标量),但共享权重参数$\gamma,\beta$(2个值均为向量,维度为$c$,即通道数)。
同时,由于组归一化是以每个样本为整体估算均值和方差对各维度进行标准化,因此组归一化并不需要区分当前是测试状态还是训练状态,其计算过程同训练时保持一致不再赘述。
6.5.3 组归一化实现#
在介绍完整个组归一化操作的原理后,我们再来看如何通过PyTorch进行实现。以下完整示例代码可以参见Code/Chapter06/C05_GN/group_normalization.py文件。
根据第6.5.2节内容的介绍可知,首先需要定义整个组归一化中的相关参数及维度信息,示例代码如下所示:
1 class GroupNormalization(nn.Module):
2 def __init__(self,num_groups,num_channels,eps=1e-5):
3 super(GroupNormalization, self).__init__()
4 if num_channels % num_groups != 0:
5 raise ValueError('num_channels must be divisible by num_groups')
6 self.num_groups = num_groups
7 self.num_channels = num_channels
8 self.eps = eps
9 self.gamma = nn.Parameter(torch.ones([1, num_channels, 1, 1]))
10 self.beta = nn.Parameter(torch.zeros([1, num_channels, 1, 1]))在上述代码中,第2行num_groups表示分组的数量,num_channels表示特征通道数。第4~5行用于判断分组数能否被特征通道数整除。第9~10行是初始化两个权重参数,分别全为1和0的两个向量。
在完成上述初始化工作后便可以进一步实现组归一化的整个前向传播过程,示例代码如下所示:
1 def forward(self, X):
2 w, h = X.shape[-2:]
3 X = X.reshape([-1, self.num_groups,
4 self.num_channels // self.num_groups, w, h])
5 mean = torch.mean(X, dim=[2, 3, 4], keepdim=True)
6 var = torch.mean((X - mean) ** 2, dim=[2, 3, 4], keepdim=True)
7 X_hat = (X - mean) / torch.sqrt(var + self.eps)
8 X_hat = X_hat.reshape(-1, self.num_channels, w, h)
9 Y = self.gamma * X_hat + self.beta
10 return Y在上述代码中,第2行是取输入特征的长和宽。第3~4行是对特征图在通道上进行分组处理,此时X的形状为[batch_size, num_groups, num_channels//num_groups, w, h]。第5~6行是分别计算每个样本各组中的特征图的均值和方差。第7行是计算组归一化标准化的结果。第8行是将标准化后的结果在形状上进行还原。第9行则是对标准化后的结果进行平移与缩放。
在实现完上述代码后还可以通过如下方式来进行检验,示例代码如下所示:
1 if __name__ == '__main__':
2 x = torch.randn([2, 6, 5, 5])
3 num_groups,num_channels = 2, 6
4 gn = GroupNormalization(num_groups, num_channels)
5 print(gn(x)[0][0][0])
6 print(y[0][0][0])
7 gn = nn.GroupNorm(num_groups, num_channels)
8 print(gn(x)[0][0][0])上述代码运行结束后便可以得到类似如下结果:
1 tensor([ 0.3784, -1.6031, -1.0346, -0.6114, -0.0211])
2 tensor([ 0.3784, -1.6031, -1.0346, -0.6114, -0.0211])最后,我们只需要像使用批归一化一样在对应的卷积层后面插入组归一化层即可。
6.5.4 小结#
在本节内容中,我们首先介绍了组归一化所提出来的动机,即为了解决批归一化算法依赖于小批量样本数量的问题;然后详细介绍了组归一化算法的计算原理,并将其同层归一化方法进行了比较;最后一步一步介绍了如何借助PyTorch框架来从零实现组归一化算法,并进行了示例和验证。
引用#
[1] Wu Y, He K. Group normalization[C]//Proceedings of the European conference on computer vision (ECCV). 3-19, 2018.
[2] https://cocodataset.org/#home
[3] Paszke A, Gross S, Massa F, et al. Pytorch: An imperative style, high-performance deep learning library[J]. Advances in neural information processing systems, 2019, 32.