4.10 基于 LangGraph 构建自定义 RAG Agent#
在第4.9节内容中,我们介绍了 LangGraph 中的3个核心图结构——State、Node 和 Edge。在本节中,我们将把这些概念真正用起来,基于 LangGraph 从零构建一个具备自我评估和问题重写能力的 Agentic RAG 系统。
4.10.1 流程构建思路#
与之前我们用 create_agent 快速搭建的版本相比,本节的实现方式更加透明:每一个判断节点、每一条条件边,都由我们显式定义,整个执行路径完全可控。整个系统的核心流程如图4-14所示。
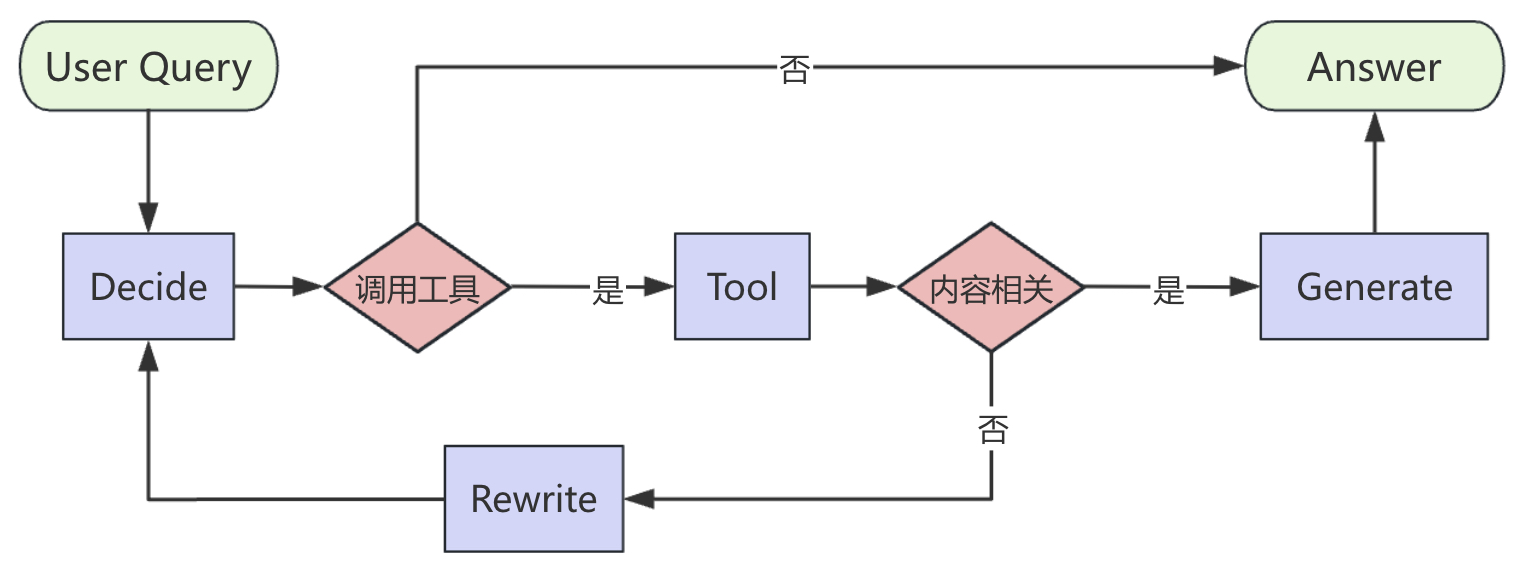
从图4-14可以看出,整个系统包含4个核心节点和2个条件判断分支。首先判断用户提问是否需要调用工具,不需要则直接回答,例如“你好”这样的招呼用户;其次判断检索到的内容是否与问题相关,相关则进一步结合问题生成回答;不相关则重写问题并进入一开始的循环。
下面,将按照图4-12中从左到右的顺序逐一进行介绍。
4.10.2 检索工具改造#
尽管在第4.8节内容中已经介绍过 retrieve_context 检索工具,但是这里为了满足需要还要稍微略作调整。在内容相关性判断中,将取 retrieve_context 工具检索并重排序后相关性最高的内容进行质量评估,如果与原问题不相关则对应所有 Top-n 的返回内容都不相关,明显可能是由于原问题描述不当导致,则需重写问题,因此检索工具的返回结果还要加上结构化的形式。
1 @tool(response_format="content_and_artifact")
2 def retrieve_context(query: str, config: RunnableConfig):
3 """
4 信息检索工具,通过检索得到的信息回答用户提问。
5 Args:
6 query: 待检索向量,例如用户提问或子问题。
7 """
8 vector_store = config['configurable'].get("vector_store")
9 k = config['configurable'].get("k")
10 top_n = config['configurable'].get("top_n")
11 artifact = vector_store.similarity_search(query, k=k)
12 filtered_doc, filter_info = text_rerank(query, artifact, top_n=top_n)
13 content = "\n\n".join((f"{doc.page_content}") for doc in filtered_doc)
14 return content, filtered_doc在上述代码中,第1行 content_and_artifact 表示同时返回分别供大模型读取和程序读取的内容,前者为非结构化的文本块,后者为结构化的文本内容。
进一步,可以通过如下用例来测试:
1 if __name__ == '__main__':
2 vector_store = get_vector_store()
3 config = RunnableConfig(configurable={"vector_store": vector_store, "k": 10, "top_n": 3})
4 r = retrieve_context.invoke({
5 "args": {"query": "郭靖是谁?"}, "id": "call_123",
6 "name": "retrieve_context", "type": "tool_call"}, config=config)
7 print(r.content,r.artifact)这里需要注意的是,content_and_artifact 模式下,invoke()函数需要接收一个带 tool_call_id参数 的输入才会返回 ToolMessage 类型的返回值,直接传字符串时 LangChain 判断这不是一次"工具调用",则退化为只返回 content 字符串。
上述代码运行结束以后就会看到类似如下结果:
华筝幼时由父亲许配给王罕的孙子都史...
郭靖望着母亲,就欲出口答应,但想起...
长须人微笑问道:“你猜我是谁?...
[Document(metadata={'level_1': '第五回 弯弓射雕', 'pk': 464859367376683299, 'source': '~RAGWithMe/data/jinyong/金庸-射雕英雄传精校版.txt', 'start_index': 6652}, page_content='华筝幼时由父亲许配给王罕的孙子都史...'), Document(metadata={'level_1': '第三十八回 锦囊密令', 'pk': 465290802323521715, 'source': '~RAGWithMe/data/jinyong/金庸-射雕英雄传精校版.txt', 'start_index': 15090}, page_content='郭靖望着母亲,就欲出口答应,但想起母...'), Document(metadata={'level_1': '第十六回 《九阴真经》', 'pk': 465290719720374297, 'source': '~RAGWithMe/data/jinyong/金庸-射雕英雄传精校版.txt', 'start_index': 14725}, page_content='长须人微笑问道:“你猜我是谁?...')]从上述输出结果可以看出,前面3行仅为字符串,余下部分则为3个 Document 类对象可供后续程序使用。
以上示例代码可参见 Code/Chapter04/C13_custom_rag_case.py 文件。
4.10.3 决策节点实现#
Decide 节点是整个 Agent 的"大脑",它的职责是判断用户的问题是否需要检索,如果需要则生成检索 Query,即工具对应的参数,并进行内容检索,否则直接回答,代码如下:
1 def generate_query_or_respond(state: MessagesState,
2 config: RunnableConfig) -> MessagesState:
3 response_model = get_llm_model()
4 llm = response_model.bind_tools([retrieve_context])
5 response = llm.invoke(state["messages"], config=config) # AIMessage
6 return {"messages": [response]} 在上述代码中,第1行 state 表示根据输入拼接好全局状态。第4行中 .bind_tools() 是将提供的工具与模型绑定,告诉模型"你有这些工具可以用",模型在生成回答时会自行决定是否触发工具调用,有需要可以通过 print(llm.kwargs) 打印工具的信息。第5行 response 是大模型根据输入返回的结果,类型是 AIMessage ,将对全局状态进行更新。
进一步,可以用下面两个测试用例来验证它的行为:
1 if __name__ == '__main__':
2 vector_store = get_vector_store()
3 SYSTEM_PROMPT = ("你是一个问答助手,当用户提出问题时,必须调用 retrieve_context 工具进行检索。\n"
4 "如果用户只是普通打招呼或闲聊,直接回答即可,不需要调用工具。\n"
5 "请保持简洁友好的语气。")
6 config = RunnableConfig(configurable={"vector_store": vector_store, "k": 10, "top_n": 3},)
7 # 测试一:普通打招呼,不需要检索
8 input = MessagesState(messages=[
9 {"role": "system", "content": SYSTEM_PROMPT},
10 {"role": "user", "content": "你好?"}])
11 generate_query_or_respond(input, config)["messages"][-1].pretty_print()
12 # 测试二:专业问题,触发检索工具调用
13 input = MessagesState(messages=[
14 {"role": "system", "content": SYSTEM_PROMPT},
15 {"role": "user", "content": "郭靖是谁?"}])
16 generate_query_or_respond(input, config)["messages"][-1].pretty_print()在上述代码中,第3~5行是注入给模型的一个系统提示词,是模型能力而定。一般来说因为我们在定义工具 retrieve_context() 时已经写过了描述所以不用加这个 SYSTEM_PROMPT 大模型也能识别到需要调用工具,但是如果模型能力弱不一定能识别到,那么此时就可以通过上面的方式来强制约束
上述代码运行结束以后就会看到类似如下结果:
================================== Ai Message ==================================
你好!很高兴见到你,有什么我可以帮忙的吗?😊
================================== Ai Message ==================================
Tool Calls:
retrieve_context (call_949591dbf87a42218244d0)
Call ID: call_949591dbf87a42218244d0
Args:
query: 郭靖从测试结果可以看出,对于普通问候模型直接回答,对于需要查资料的问题模型会自动触发工具调用,这也正是我们希望的行为。
同时,如果需要对整个过程进行调试,可以在第6行 RunnableConfig 中添加参数 callbacks=[ConsoleCallbackHandler()] 即可输出详细信息,包括 LangGraph 内部的交互和大模型调用的相关信息。
例如对于上面第2个测试案例,可以打印出输入到大模型的实际内容,如下所示:
[llm/start] [llm:ChatOpenAI] Entering LLM run with input:
{"prompts": [
"System: 你是一个问答助手,当用户提出问题时,必须调用 retrieve_context 工具进行检索。\n如果用户只是普通打招呼或闲聊,直接回答即可,不需要调用工具。\n请保持简洁友好的语气。\nHuman: 郭靖是谁?"]
}以上示例代码可参见 Code/Chapter04/C13_custom_rag_case.py 文件。
注意:工具对应的 Schema 信息是作为另外一个 tools 参数传入大模型的,可参见第4.2.5节内容,但也被算作是输入大模型的 Token,只是人为分成了两部分。
4.10.4 检索文档质量评估#
由于检索工具返回的内容不一定都和问题相关,因此还需要一个节点负责评估检索结果的相关性,并根据评估结果决定下一步走哪条分支,即相关则直接生成回答,不相关则重写问题重新检索。
具体地,对于文档质量评估部分实现代码如下:
1 GRADE_PROMPT = ("你是一个文档相关性评估助手。\n"
2 "检索到的文档内容:\n\n{context}\n\n"
3 "用户问题:{question}\n"
4 "如果文档内容与问题语义相关,评分为 'yes',否则为 'no'。")
5
6 class GradeDocuments(BaseModel):
7 binary_score: str = Field(
8 description="相关性评分:'yes' 表示相关,'no' 表示不相关")
9
10 def grade_documents(
11 state: MessagesState) -> Literal["generate_answer", "rewrite_question"]:
12 question = state["messages"][0].content
13 context = state["messages"][-1].content # 最后一条消息是工具返回的检索结果
14 prompt = GRADE_PROMPT.format(question=question, context=context)
15 response = (get_llm_model()
16 .with_structured_output(GradeDocuments) # 强制模型输出结构化结果
17 .invoke([{"role": "user", "content": prompt}]))
18 return "generate_answer" if response.binary_score == "yes" else "rewrite_question"在上述代码中,第1~4行是定义一个评估的 prompt 模板。第6~8行定义大模型输出的 Schema 结构信息。第10~18行定义了大模型根据用户提问和检索解锁评估得到的相关性结果,其中第11行表示强制指定返回值只能是 "generate_answer" 或者 "rewrite_question",第16行 .with_structured_output(GradeDocuments) 表示让模型强制按照 GradeDocuments 的 Schema 输出结果,而不是自由发挥,这保证了评估结果永远只有 "yes" 或 "no" 两种,不会出现模型说"我觉得这个文档有点相关但不太确定……“这种模糊答案。
值得注意的是,这里grade_documents 函数的返回值不是状态更新,而是下一个节点的名称字符串,它直接决定图的执行路径。
进一步,可以通过如下方式来测试:
1 if __name__ == '__main__':
2 # 测试一: 回答内容与问题不相关
3 input = {
4 "messages": convert_to_messages(
5 [ {"role": "user", "content": "郭靖是谁?"},
6 {"role": "assistant", "content": "", "tool_calls":
7 [{"id": "1", "name": "retrieve_context", "args": {"query": "郭靖"}, }], },
8 {"role": "tool",
9 "content": "李萍瞧着儿子憨憨的模样,说着什么“羊儿、马儿”,全带着自己柔软的临安乡下土音,时时不禁心酸:“你爹是山东好汉,你也该当说山东话才是。",
10 "tool_call_id": "1"}])}
11 print(grade_documents(input))
12
13 # 测试二: 回答内容与问题相关
14 input = {
15 "messages": convert_to_messages(
16 [ {"role": "user", "content": "郭靖是谁?"},
17 {"role": "assistant", "content": "", "tool_calls":
18 [{"id": "1", "name": "retrieve_context", "args": {"query": "郭靖"}, }], },
19 {"role": "tool",
20 "content": "郭靖是《射雕英雄传》中的主人公。他的母亲李萍是浙江临安人,父亲是山东好汉。郭靖出生于临安府牛家村,幼年时因战乱随母亲流落蒙古大漠。",
21 "tool_call_id": "1"}])}
22 print(grade_documents(input))上述代码运行结束以后就会看到类似如下结果:
rewrite_question
generate_answer以上完整示例代码可参见 Code/Chapter04/C14_custom_rag_grade.py 文件。
4.10.5 问题重写#
当检索结果不相关时,说明用户的原始问题可能表述不够清晰,需要让模型对原问题进行改写,以便下一轮检索能找到更相关的内容。
1 REWRITE_PROMPT = ("请理解下面这个问题,并将其改写成一个更清晰、更有利于语义检索的问题。\n"
2 "原始问题:\n---\n{question}\n---\n"
3 "改写后的问题:")
4
5 def rewrite_question(state: MessagesState) -> MessagesState:
6 question = state["messages"][0].content
7 prompt = REWRITE_PROMPT.format(question=question)
8 response = get_llm_model().invoke([{"role": "user", "content": prompt}])
9 return {"messages": [HumanMessage(content=response.content)]}在上述代码中,第6行是取用户的原始问题。第7行是填充 prompt 模板。第8行是得到大模型改写后的结果,返回类型为 AIMessage。第9行是将改写后的问题追加到全局消息列表中,后续会回到 generate_query_or_respond 节点重新发起检索。
这里值得注意的是,在第9行中强制将 AIMessage 构造成了 HumanMessage 进行返回是因为在 LangChain 中每种消息类型尤其特定的语义。例如 ToolMessage 在 LangChain 代表"某个工具调用的返回结果”,必须配合一个 tool_call_id 使用,用来告诉模型"这是你之前调用某个工具得到的结果"。
LangChain 中几种 Message 类型的语义分工如下所示:
| 类型 | 对应角色 | 使用场景 |
|---|---|---|
HumanMessage |
user |
用户的输入或提问 |
AIMessage |
assistant |
模型的回答或工具调用决策 |
ToolMessage |
tool |
工具调用的返回结果,必须有 tool_call_id |
SystemMessage |
system |
系统提示词,控制模型行为 |
这里 rewrite_question 的目的是把改写后的问题当作新的用户输入重新发起检索,所以用 HumanMessage 是唯一正确的选择。
进一步,可以通过如下用例来测试:
1 if __name__ == '__main__':
2 input = {"messages": convert_to_messages([{"role": "user", "content": "郭靖是谁?"},
3 {"role": "assistant", "content": "", "tool_calls":
4 [{"id": "1", "name": "retrieve_context", "args": {"query": "郭靖"}, }], },
5 {"role": "tool",
6 "content": "李萍瞧着儿子憨憨的模样,说着什么“羊儿、马儿”,全带着自...","tool_call_id": "1"}])}
7 response = rewrite_question(input)
8 print(response["messages"][-1].content)
9 # 郭靖是金庸武侠小说《射雕英雄传》中的核心男主角,其身份背景、主要经历和人物形象是怎样的?在上述代码中,第2行 convert_to_messages 是将整个消息列表转换成 LangChain 中的消息格式,即 input 的内容如下:
{'messages': [HumanMessage(content='郭靖是谁?', additional_kwargs={}, response_metadata={}), AIMessage(content='', additional_kwargs={}, response_metadata={}, tool_calls=[{'name': 'retrieve_context', 'args': {'query': '郭靖'}, 'id': '1', 'type': 'tool_call'}], invalid_tool_calls=[]), ToolMessage(content='李萍瞧着儿子憨憨的模样,说着什么“羊儿、马儿”,全带着自...', tool_call_id='1')]}最终,问题重写以后 LangGraph 中的全局 MessagesState 类似如下:
{'messages': [HumanMessage(content='郭靖是谁?', additional_kwargs={}, response_metadata={}), AIMessage(content='', additional_kwargs={}, response_metadata={}, tool_calls=[{'name': 'retrieve_context', 'args': {'query': '郭靖'}, 'id': '1', 'type': 'tool_call'}], invalid_tool_calls=[]), ToolMessage(content='李萍瞧着儿子憨憨的模样,说着什么“羊儿、马儿”,全带着自...', tool_call_id='1'),HumanMessage(content='郭靖是金庸武侠小说《射雕英雄传》中的核心男主角,其身份背景、主要经历和人物形象是怎样的?', additional_kwargs={}, response_metadata={})]}4.10.6 生成最终回答#
在通过质量评估后,最后一步便是基于检索到的内容和用户提问生成简洁的回答,实现代码如下
1 GENERATE_PROMPT = (
2 "你是一个RAG问答助手,严格遵守以下规则:\n"
3 "1. 你的回答必须且只能基于提供的参考内容,禁止回答与问题无关的内容。"
4 "2. 禁止调用任何第三方工具、MCP 服务或外部 API。\n"
5 "3. 如果某条信息在参考内容中没有明确原文支撑,直接略去,不得在回答中提及'该信息未出现'、'无法作答'、'检索结果未包含'等任何说明。\n"
6 "4. 如果参考内容完全与问题无关,才回答'根据现有文档无法回答该问题'。\n"
7 "5. 最后的输出结果请格式化、严肃、正式输出,不要随意分段。\n"
8 "问题:{question}\n\n"
9 "参考内容:{context}")
10
11 def generate_answer(state: MessagesState) -> MessagesState:
12 question = state["messages"][-3].content
13 context = state["messages"][-1].content
14 prompt = GENERATE_PROMPT.format(question=question, context=context)
15 response = get_llm_model().invoke([{"role": "user", "content": prompt}])
16 return {"messages": [response]}在上述代码中,第12、13行分别是从全局状态中取用户问题和检索内容,其对应的索引序号请根据实际情况获取。同时,这里 state["messages"][-3].content 表示最后一次的用户问题,因为用户问题可能会被改写;而如果是state["messages"][0].content 则表示原始问题。
进一步,可以通过如下用例来测试:
1 if __name__ == '__main__':
2 input = {"messages": convert_to_messages(
3 [{"role": "user", "content": "郭靖是谁?它的出生背景是什么?"},
4 {"role": "assistant","content": "","tool_calls": [
5 {"id": "1","name": "retrieve_context","args": {"query": "郭靖 出生背景"}}]},
6 {"role": "tool","content": "郭靖之母是浙江临安人,江南六怪都是嘉兴左近人氏,他从小听惯了江南口音,...",
7 "tool_call_id": "1"}])}
8
9 response = generate_answer(input)
10 response["messages"][-1].pretty_print()
11 # 郭靖之母是浙江临安人,江南六怪都是嘉兴左近人氏,郭靖从小听惯了江南口音。4.10.7 搭建完整流程#
在完成上述所有过程以后,我们再将其按照图4-12中的流程构造成一个完整的图,实现代码如下:
1 def get_workflow():
2 workflow = StateGraph(MessagesState)
3 workflow.add_node("decide", generate_query_or_respond)
4 workflow.add_node("my_retrieve", ToolNode([retrieve_context]))
5 workflow.add_node("rewrite_question", rewrite_question)
6 workflow.add_node("generate_answer", generate_answer)
7 workflow.add_edge(START, "decide")
8 workflow.add_conditional_edges( "decide", tools_condition,
9 {"tools": "my_retrieve", END: END})
10 workflow.add_conditional_edges("my_retrieve", grade_documents)
11 workflow.add_edge("generate_answer", END)
12 workflow.add_edge("rewrite_question", "decide")
13 graph = workflow.compile()
14 return graph在上述代码中,第3~6行是注册所有的节点。第8~9行是添加 “decide” 节点到到工具调用的条件边,其中 tools_condition 是LangGraph 内置的一个条件判断函数,它的返回值只有"tools"(表示继续走 ToolNode)和"__end__"(表示结束),作用是检测上一个节点的输出中是否包含 tool_calls 字段,有则路由到工具节点,没有则直接结束,这样就省去了我们自己写这个判断逻辑。
在完成 get_workflow() 函数实现以后,我们依旧可以得到其对应的可视化图结构,如图4-13所示。
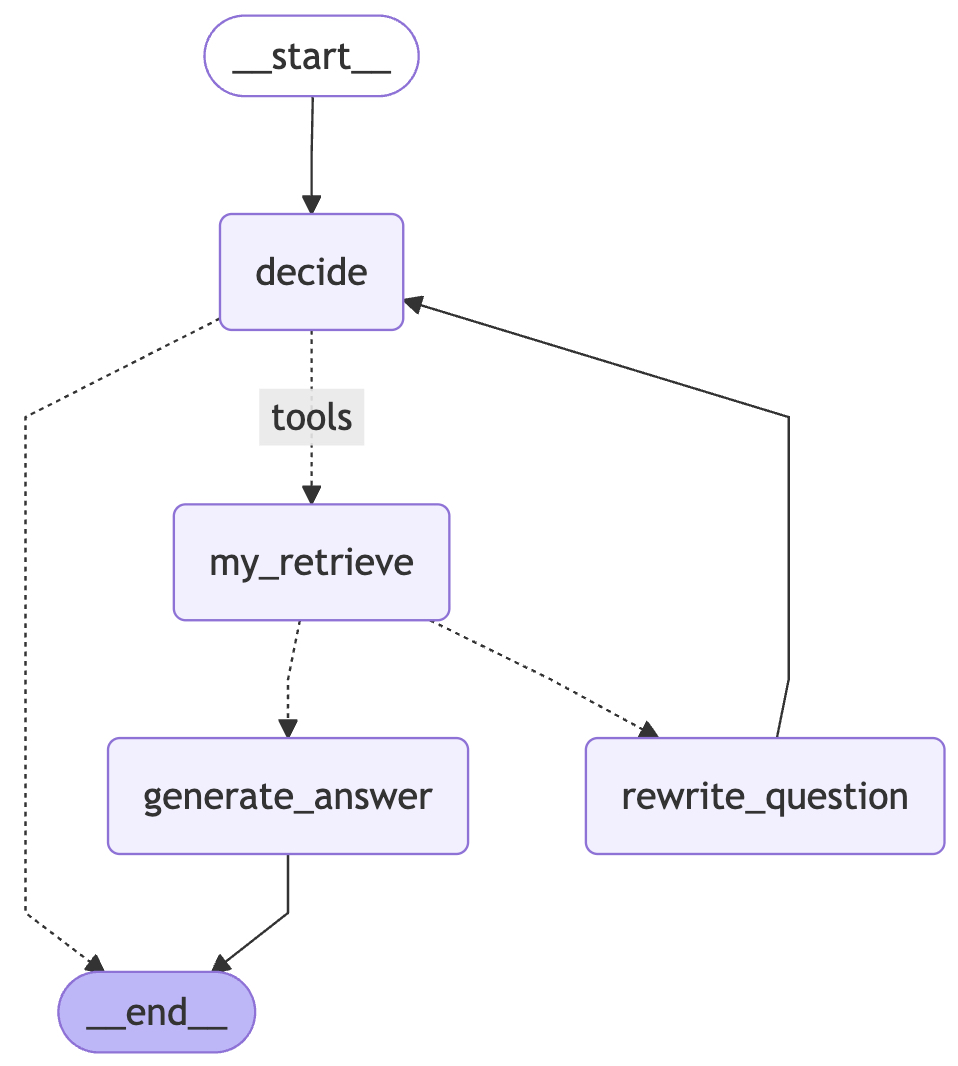
从图4-13可以清晰地看到整个推理链路,模型先判断是否需要检索,然后发起检索 、检索结果通过质量评估、直接生成最终回答,每一步都有明确的节点标识,排查问题时也比黑盒的 create_agent 直观很多。
进一步,可以通过如下方式来运行整个工程,代码如下:
1 if __name__ == '__main__':
2 agent = get_workflow()
3 vector_store = get_vector_store()
4 config = RunnableConfig(configurable={"vector_store": vector_store, "k": 20, "top_n": 3})
5 input = {"messages": convert_to_messages([{"role": "user","
6 content": "郭靖和杨康是什么关系?",}])}
7
8 for event in agent.stream(input, config=config):
9 for node, update in event.items():
10 print(f"#### 节点 {node} 处理完毕")
11 update["messages"][-1].pretty_print()
12 print("\n\n")上述代码运行结束以后,将会看到类似如下结果:
#### 节点 decide 处理完毕
================================== Ai Message ==================================
Tool Calls:
retrieve_context (call_d695fdcdbf324d13bf2336)
Call ID: call_d695fdcdbf324d13bf2336
Args:
query: 郭靖和杨康的关系
#### 节点 my_retrieve 处理完毕
================================= Tool Message =================================
Name: retrieve_context
杨康边哭边说,涕泪滂沱,断断续续地道:“我是郭靖的结义兄弟...
#### 节点 generate_answer 处理完毕
================================== Ai Message ==================================
郭靖和杨康是结义兄弟。两人在郭啸天的灵前对拜八拜,正式结为兄弟,郭靖先出世一个月,为兄,杨康为弟。同时,还可以通过如下方式来输出每经过一个节点时的全局状态 MessagesState,代码如下:
1 if __name__ == '__main__':
2 ...
3 for chunk in agent.stream(
4 input,
5 stream_mode=["updates", "values"], config=config): # 同时获取节点名称和完整状态
6 mode, data = chunk
7 if mode == "updates":
8 node_name = list(data.keys())[0] # 当前执行的节点名称
9 print("=" * 50)
10 print(f"当前节点:{node_name}")
11 elif mode == "values":
12 print(f"当前消息数量:{len(data['messages'])}")
13 print("当前全局消息:")
14 print(data)上述代码运行结束以后,将会看到类似如下结果:
当前消息数量:1
当前全局消息:
{'messages': [HumanMessage(content='郭靖和杨康是什么关系?'...)]}
==================================================
当前节点:decide
当前消息数量:2
当前全局消息:
{'messages': [HumanMessage(content='郭靖和杨康是什么关系?', ...),
AIMessage(content='', ... tool_calls=[{'args': {'query': '郭靖和杨康的关系'},...)
==================================================
当前节点:my_retrieve
当前消息数量:3
当前全局消息:
{'messages': [HumanMessage(content='郭靖和杨康是什么关系?'...),
AIMessage(content='',... tool_calls=[{'args': {'query': '郭靖和杨康的关系'},...),
ToolMessage(content='杨康边哭边说,涕泪滂沱,断断..., artifact=...)]}
==================================================
当前节点:generate_answer
当前消息数量:4
当前全局消息:
{
'messages': [HumanMessage(content='郭靖和杨康是什么关系?'...),
AIMessage(content='',... tool_calls=[{'args': {'query': '郭靖和杨康的关系'},...),
ToolMessage(content='杨康边哭边说,涕泪滂沱,断断..., artifact=...),
AIMessage(content='郭靖和杨康是结义兄弟。两人在郭啸天的灵前对拜八拜,正式结为..}根据以上输出结果便能够清晰地看到每经过一个节点处理以后,全局状态 MessagesState 到底是如何改变的。
同时,这里还有一个值得思考的问题:如果用户问的是"孙悟空是谁",而知识库里完全没有相关内容,这个系统会陷入"检索、评估不相关、改写、再检索、评估不相关……“的无限循环吗?大家可以想一想该如何给这个循环加一个退出条件,欢迎在评论区聊聊。
在下一章内容中,我们将介绍如何给 RAG 加上记忆机制,让它能够跨对话保留上下文。
参考#
[1] https://docs.langchain.com/oss/python/langgraph/agentic-rag.md