2.3 多项式回归#
2.3.1 理解多项式#
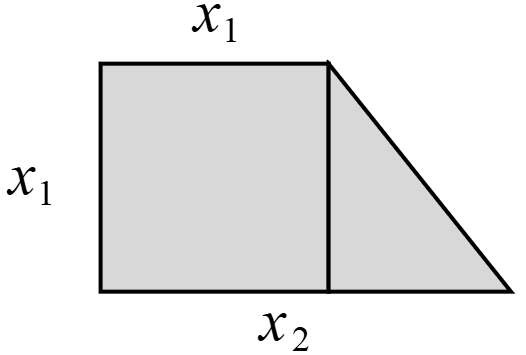
在前面两个小节的内容中,我们分别介绍了单变量线性回归和多变量线性回归,那什么是多项式回归呢?现在假定已知矩形的面积公式,而不知道求解梯形的面积公式,并且同时手上有若干个类似图2-7所示的梯形。已知梯形的上底和下底,并且上底均等于高。现在需要建立一个模型,当任意给定一个类似图2-7中的梯形时能近似地算出其面积。面对这样的问题该如何进行建模呢?
2.3.2 多项式回归建模#
首先需要明确的是,即使直接建模成类似于2.2节中的多变量线性回归模型$h(x)=w_1x_1+w_2x_2+b$也是可以的,只是效果可能不会太好。现在我们来分析一下,对于这个梯形,左边可以看成正方形,所以可以人为地构造第3个特征$(x_1)^2$,而整体也可以看成长方形的一部分,则又可以人为地构造出$x_1x_2$这个特征,最后,整体还可以看成大正方形的一部分,因此还可以构造出$(x_2)^2$这个特征。因此,我们便可以建立一个如式(2-5)所示的模型
$$ h(x)=x_1w_1+x_2w_2+(x_1)^2w_3+x_1x_2w_4+(x_2)^2w_5+b\tag{2-5} $$此时有读者可能会问,式(2-5)中有的部分重复累加了,计算出来的面积岂不大于实际面积吗?这当然不会,因为每一项前面都有一个权重参数$w_i$做系数,只要这些权重有正有负,就不会出现大于实际面积的情况。同时,可以发现$h(x)$中包含了$x_1x_2$、$(x_1)^2$、$(x_2)^2$这些项,因此也将其称为多项式回归(Polynomial Regression)。
但是,只要进行如下替换,便可回到普通的线性回归:
$$ h(x)={x}_{1}{w}_{1}+{x}_{2}{w}_{2}+{x}_{3}{w}_{3}+{x}_{4}{w}_{4}+{x}_{5}{w}_{5}+b\tag{2-6} $$其中,$x_3=(x_1)^2$、$x_4=x_1x_2$、$x_5=(x_2)^2$,只是在实际建模时先要将原始两个特征的数据转化为5个特征的数据,同时在正式进行预测时,向模型$h(x)$输入的也将是包含5个特征的数据。
2.3.3 多项式回归示例代码#
要完成整个多项式回归的建模,首先需要对原始的特征进行转换,构造模型所需要的新特征,然后构造相应的数据集,最后进行模型的训练与预测。完整代码见 AllBookCode/Chapter02/C04_trapezoid_polynomial_train.py 文件。
1. 特征转化
这里首先介绍一下sklearn中的多项式变换模块PolynomialFeatures,它的作用便是对每个特征进行指定的幂次变换,代码如下:
1 from sklearn.preprocessing import PolynomialFeatures
2 a = [[3, 4], [2, 3]]
3 model = PolynomialFeatures(degree=2,include_bias=False)
4 b = model.fit_transform(a)
5 print(b)
6 #输出结果:[[ 3. 4. 9. 12. 16.] [ 2. 3. 4. 6. 9.]]从输出结果可以看出,此时上述第3~4行代码的作用就是将原来的2个特征$x_1$和$x_2$变换为现在的5个特征$x_1$、$x_2$、$x^2_1$、$x_1x_2$和$x_2^2$。
2. 构造数据集
构造训练模型时所需要用到的数据集,代码如下:
1 def make_data():
2 np.random.seed(10)
3 x1 = np.random.randint(5, 10, 50).reshape(50, 1)
4 x2 = np.random.randint(10, 16, 50).reshape(50, 1)
5 x,y = np.hstack((x1, x2)), 0.5 * (x1 + x2) * x1
6 return x, y在上述代码中,np.hstack((x1,x2))的作用是将两个50行1列的矩阵进行水平堆叠,这样便得到了一个50行2列的样本数据,其中第1列为上底,第2列为下底。
3. 建模求解与结果
首先对原始特征进行多项式构造处理,然后进行模型的训练,代码如下:
1 def train(x, y):
2 poly = PolynomialFeatures(degree=2, include_bias=False)
3 x_mul = poly.fit_transform(x)
4 model = LinearRegression()
5 model.fit(x_mul, y)
6 print("权重为:", model.coef_)#[[0. 0. 0.5 0.5 0]]
7 print("偏置为:", model.intercept_) # [0.]
8 print("上底为{},下底为{}的梯形的真实面积为{}".format(5,8,0.5 * (5 + 8) * 5))
9 x_mul = poly.transform([[5, 8]])
10 y_pred = model.predict(x_mul)
11 print("上底为{},下底为{}的梯形的预测面积为{}".format(5, 8,y_pred ))根据上述代码建模求解后,就能够预测得到上底为 5,下底为8的梯形面积为32.5,其输出结果如下:
权重为 [[-6.178e-15-5.122e-165.0e-015.0e-01-9.714e-17]]
偏置为 [0.]
上底为5,下底为8的梯形的真实面积为32.5
上底为5,下底为8的梯形的预测面积为[[32.5]]并且,根据求解得的权重和偏置可得
$$ \begin{aligned} & h(x)={{x}_{1}}\cdot 0+{{x}_{2}}\cdot 0+{{x}_{3}}\cdot 0.5+{{x}_{4}}\cdot 0.5+{{x}_{5}}\cdot 0+b \\[2ex] & =0.5\cdot {{({{x}_{1}})}^{2}}+0.5\cdot {{x}_{1}}\cdot {{x}_{2}} \\[2ex] & =0.5\cdot {{x}_{1}}({{x}_{1}}+{{x}_{2}}) \end{aligned} \tag{2-7} $$可以发现,此时模型居然已经自己总结(学习)出了梯形的面积计算公式。
2.3.4小结#
在本节内容中,我们首先以两个示例来分别介绍了多变量线性回归和多项式回归,然后通过sklearn对模型进行了求解,最后,我们通过一个梯形面积的求解示例和读者一起领略了算法的魅力所在。在2.4节中,我们将开始对模型的评估进行介绍。