4.9 ResNet网络#
在前面节内容中我们陆续介绍了几种不同的卷积网络模型,并且整体上来看随着模型的发展其对应的网络深度也在逐渐加深。不过随着模型网络层数的加深,模型的训练难度却变得越来越大,而其根本原因就在于神经网络的退化问题(Degradation Problem)。在接下来的这节内容中,我们将介绍一种新的网络结构”残差“块来解决这一问题[1]。
4.9.1 ResNet动机#
随着神经网络的发展,通过加大网络深度来提高模型精度已经成为了一种常见的做法,但这是否意味着学习更好的网络仅仅只需要通过堆叠网络层数就足以实现呢?虽然梯度裁剪、批归一化[2](相关介绍可参见第6章内容)等方法已经在一定程度上解决了深度模型的梯度爆炸(Gradient Exploding)和梯度消失(Gradient Vanishing)的问题,但实验表明随着网络层数的加深模型效果在达到一个饱和状态后便开始急剧下降了,而这便被称为神经网络的退化问题。
同时,作者认为只需要将新增加的网络层做恒等映射(Identity Mapping)那么从理论上讲,相较于原模型新模型最终效果至少也应该不会变差,但最终结果证明新增加的网络层不仅没有给模型带来好的效果反而变得更差了。基于这样的想法,何凯明等人于2015年提出了一种“残差学习”(Residual Learning)的思想来解决网络的退化问题,并凭借基于残差模块构建的残差网络ResNet一举赢得了2015年ImageNet大规模视觉识别挑战赛。
4.9.2 ResNet结构#
在正式ResNet模型的网络结构之前,我们先来介绍其中的核心部分残差结构和维度对齐。
1.理解残差结构
残差学习的核心思想在于,与其直接学习整个模型潜在的函数映射关系不如逐步分层来进行学习,因为后者相比于前者容易很多。如图4-45所示,左侧为原始逐层简单叠加的网络局部结构图,右侧为残差模块结构示意图,其中$X$均表示未画出的浅层网络,$\mathcal{F}(X)$表示局部的两层网络。
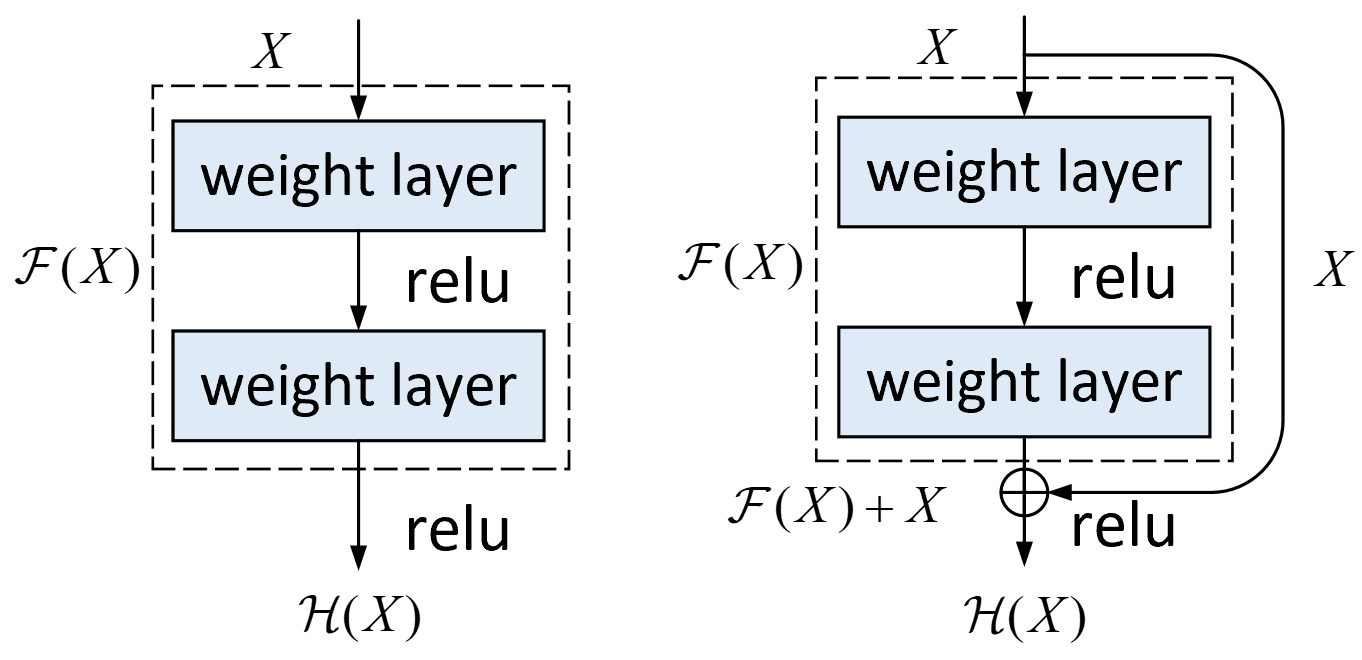
假设现在图4-45中的两个网络结构均需完成同样一个分类任务,即两者均需要学习同样一个潜在的函数映射关系$\mathcal{H}(X)$。此时对于左侧的普通结构来说,如果需要学习得到到$\mathcal{H}(X)=\mathcal{F}(X)$这一潜在映射那就必须从上到下逐层学习;而对于右侧的残差结构来说,由于其多增加了一个快捷连接(Shortcut Connection)使得$\mathcal{H}(X)=\mathcal{F}(X)+X$,则此时有$\mathcal{F}(X)=\mathcal{H}(X)-X$。由此可以发现,在残差结构中模型只需要学习到$\mathcal{F}(X)=\mathcal{H}(X)-X$便可以得到最终的潜在函数映射$\mathcal{H}(X)$,而在普通结构中模型则需要学习完整的$\mathcal{F}(X)=\mathcal{H}(X)$映射,因此残差模块在训练过程总相比于普通模块更容易拟合。
同时,从直观的角度来看,使用快捷连接后浅层网络的输出便能够跳跃部分网络层而直接作用于更深的部分,这使得残差模块能够在不断提高模型性能同时还能够保持模型的精度至少不会降低,因为此时只需要$\mathcal{F}(X)$做恒等映射$\mathcal{F}(X)=0$便能实现。
2. 残差结构中的反向传播
从图4-45(右)中的结构可以看出,残差模块的核心也是唯一部分就是这个快捷连接,让它除了具备解决网络退化的问题同时还使得深层网络在训练过程中不容易出现梯度消失或爆炸的情况进而可以加快网络的收敛速度。
根据图4-45可知,对于左边的普通结构来说输出层$\mathcal{H}(X)$关于输入层$X$的梯度为
$$ \frac{\partial \mathcal{H}}{\partial X}=\frac{\partial \mathcal{H}}{\partial F}\frac{\partial \mathcal{F}}{\partial X} \tag{4-7} $$而对于右边的残差结构来说,其对应的梯度为
$$ \frac{\partial \mathcal{H}}{\partial X}=\frac{\partial \mathcal{H}}{\partial F}\frac{\partial \mathcal{F}}{\partial X}+\frac{\partial \mathcal{H}}{\partial X} \tag{4-8} $$从式(4-7)和式(4-8)可以看出,在残差结构中由于快捷连接的存在所以多了一项直接由$\mathcal{H}(X)$到$X$的梯度,所以相比于普通的连接方式更不出现梯度消失或爆炸的问题。
3. 残差结构中的维度对齐
根据上述内容的介绍我们已经了解了残差结构的核心思想和原理,但现在有一个问题便是不同通道数和不同大小的特征图之间如何进行快捷连接。通常来说,随着网络层数的加深卷积核的个数也会成倍地进行增加同时特征图的大小会成倍的缩小,而这就导致在残差结构中如果两个网络层输出特征图大小或通道数不一致便不能使用快捷连接。因此,在这种情况下会通过一个窗口大小为$1\times1$的卷积层来调整特征图大小和通道数。
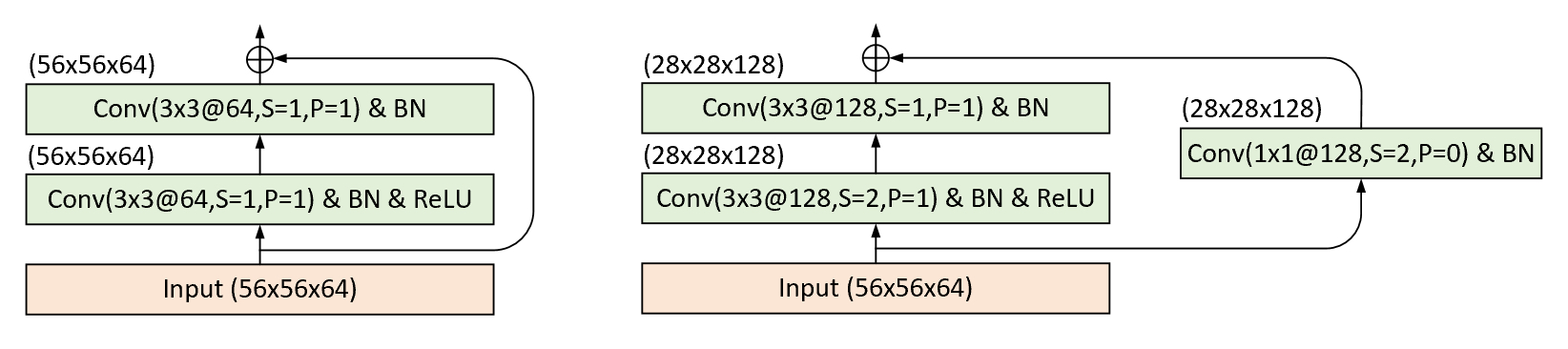
如图4-46所示,对于相同维度的输入来说,左侧的残差结构经过两个卷积层之后输出特征图的维度依旧没有发生变化,因此可以直接相加实现快捷连接;而右侧的残差结构在经过两个卷积层之后输出特征的大小和通道数分别变成了原来的一半和两倍,所以在进行快捷连接之前需要将原始输入经过一个$1\times1$的卷积层来实现维度对齐。
4. 整体网络结构
在介绍完整个残差结构的相关原理后,我们再来看如何通过残差结构来构建整个ResNet网络模型。整体来说ResNet一共有5种网络结构,分别是ResNet18、ResNet34、ResNet50、ResNet101和ResNet152,但它们均是由残差结构搭建而来。下面以ResNset18为例进行介绍,其网络结构信息如表4-3所示。
| 网络层 | 输出形状 | 18-layer |
|---|---|---|
| Layer0 | $112\times112$ | $\begin{bmatrix}7\times7,&64\end{bmatrix}\times1$ |
| Layer0 | $56\times56$ | Max Pooling |
| Layer1 | $56\times56$ | $\begin{bmatrix}3\times3,&64\\ 3\times3,&64\end{bmatrix}\times2$ |
| Layer2 | $28\times28$ | $\begin{bmatrix}3\times3,&128\\ 3\times3,&128\end{bmatrix}\times2$ |
| Layer3 | $14\times14$ | $\begin{bmatrix}3\times3,&256\\ 3\times3,&256\end{bmatrix}\times2$ |
| Layer4 | $7\times7$ | $\begin{bmatrix}3\times3,&512\\ 3\times3,&512\end{bmatrix}\times2$ |
| Classifier | $1\times1$ | Global Average Pooling, softmax |
如表4-3所示,从上到下ResNet18一共有6个部分,其中第2列表示每个部分特征图输出的形状;第3列表示各层对应的参数信息,以Layer1这一行为例,其表示一共使用了2个残差结构且每个残差结构由两个卷积层构成。由此,根据表4-3中的结构信息便可以得到如图4-47所示的网络结构图。
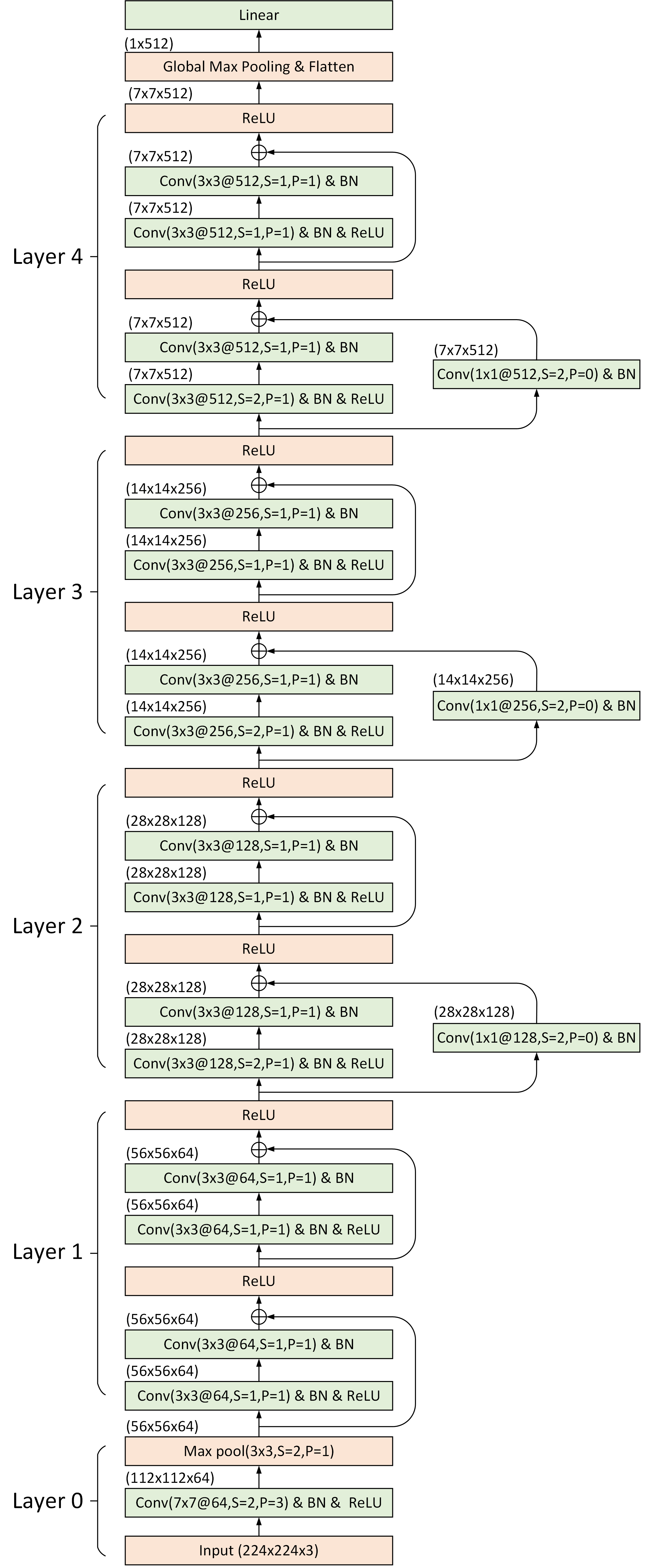
如图4-47所示,输入形状为3通道大小是$224\times224$的图片,在经过第1个卷积层和池化层处理后形状变成了形状为$56\times56\times64$的特征图;紧接着便是2个残差结构(即Layer1)的处理,输出形状同样为$56\times56\times64$;然后再进入到下一个残差模块中,且由于此时形状不同需要利用一个$1\times1$的卷积来进行对齐;进一步便是重复残差结构并成倍的增加卷积核的个数;在Layer4之后再经过一个全局平均池化层得到一个一维向量,最后通过一个Softmax层完成分类任务。具体每个残差结构计算后特征图的形状可以参见图4-47中的对应标注。
4.9.3 ResNet实现#
根据图4-47中的结构信息,我们首先需要实现一个辅助类来完成残差结构的构建,并以此为基础实现整个残差网络。以下完整示例代码可以参见Code/Chapter04/C08_ResNet/文件。
1. 辅助模块
根据图4-47可知,ResNet18中残差结构由两个卷积层所构建,因此可以通过如下所示代码来实现该结构:
1 class BasicBlock(nn.Module):
2 def __init__(self, in_channels, out_channels, downsample=None, stride=1):
3 super().__init__()
4 self.downsample = downsample
5 self.block = nn.Sequential(
6 nn.Conv2d(in_channels, out_channels, 3, stride=stride, padding=1, bias=False),
7 nn.BatchNorm2d(out_channels),
8 nn.ReLU(inplace=True),
9 nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False),
10 nn.BatchNorm2d(out_channels))
11 self.relu = nn.ReLU(inplace=True)在上述代码中,第4行表示用于特征图对齐的方法。第5~10行是正常堆叠的卷积网络结构。
进一步,残差结构的前向传播计算实现过程为:
1 def forward(self, x):
2 identity = x
3 out = self.block(x)
4 if self.downsample is not None:
5 identity = self.downsample(x)
6 out += identity
7 out = self.relu(out)
8 return out在上述代码中,第3行是根据输出进行正常两个卷积层的计算过程。第4~5行则是判断是否要进行维度对齐。第6行便是快捷连接的计算部分。第7~8行便是返回该残差结构的计算结果。
2. 前向传播
在实现完残差结构的前向传播过程后便可以定义一个类ResNet来实现整个网络模型,示例代码如下所示:
1 class ResNet(nn.Module):
2 def __init__(self, in_channels=3, block=None, layers=None, num_classes=1000):
3 super().__init__()
4 self.last_res_layer_channels = 64
5 self.layer0 = nn.Sequential(nn.Conv2d(in_channels, self.last_res_layer_channels,
6 kernel_size=7, stride=2, padding=3, bias=False),
7 nn.BatchNorm2d(self.last_res_layer_channels),
8 nn.ReLU(inplace=True),
9 nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
10 self.layer1 = self._make_layer(block, 64, layers[0])
11 self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
12 self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
13 self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
14 self.classifier = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
15 nn.Flatten(), nn.Linear(512, num_classes)) 在上述代码中,第1行in_channels表示原始输入模型图片的通道数,block在这里便是表示上面实现的BasicBlock类,layers则表示每个层结构对应残差结构的数量,例如对于图4-47中的ResNet18来说layers=[2,2,2,2]。第4行last_res_layer_channels表示上一个残差结构输出的通道数。第5~9行是图4-47对应Layer0部分的实现。第10~14行分别对应于图4-47中Layer1~Layer4部分的实现。第14~15行则是对应于最后的分类层。
同时,类成员方法_make_layer的实现代码如下所示:
1 def _make_layer(self, block, channels, blocks, stride=1):
2 layers = []
3 downsample = None
4 if stride != 1: # stride = 2
5 downsample = nn.Sequential(
6 nn.Conv2d(self.last_res_layer_channels, channels, 1, stride),
7 nn.BatchNorm2d(channels))
8 layers.append(block(self.last_res_layer_channels, channels, downsample, stride))
9 self.last_res_layer_channels = channels
10 for _ in range(1, blocks):
11 layers.append(block(self.last_res_layer_channels, channels))
12 return nn.Sequential(*layers)在上述代码中,第4~7行便是根据参数stride来判断后续是否需要在残差结构中进行对齐处理,如果需要则定义一个$1\times1$的卷积层。第8~11行便是分别完成需要进行对齐和不需要对齐的残差结构部分的计算过程。第12行则是返回整个层结构的网络结构。
进一步,残差网络的前向传播过程实现代码为:
1 def forward(self, x, labels=None):
2 x = self.layer0(x)
3 x = self.layer1(x)
4 x = self.layer2(x)
5 x = self.layer3(x)
6 x = self.layer4(x)
7 logits = self.classifier(x)
8
9 if labels is not None:
10 loss_fct = nn.CrossEntropyLoss(reduction='mean')
11 loss = loss_fct(logits, labels)
12 return loss, logits
13 else:
14 return logits在上述代码中,第2~7行便是完成整个残差网络的前向传播计算过程。第9~14行则是根据对应的判断条件返回模型的输出结果。
接着,通过如下代码便可以返回得到ResNet18模型的前向传播过程:
1 def resnet18(num_classes=1000, in_channels=3):
2 model = ResNet(in_channels, BasicBlock, [2, 2, 2, 2],num_classes=num_classes)
3 return model在上述代码中,第2行[2,2,2,2]便是用来指定返回ResNet18这个残差网络,如果将其改为[3,4,6,3]则是返回ResNet34这个残差网络。