9.5 MultiAdaBoost原理与实现#
在9.4节内容中,我们详细介绍了AdaBoost算法的思想原理和实现过程,算是对于AdaBoost算法框架有了一个基本的认识。根据AdaBoost算法的原理可知,其最初主要是被用于二分类任务中[6],因此它并不能很好地处理多分类问题。
9.5.1 MultiAdaBoost算法思想#
根据AdaBoost算法中分类器权重的计算公式(9-8)可以得到模型误差与模型权重之间的函数关系,如图9-11所示。
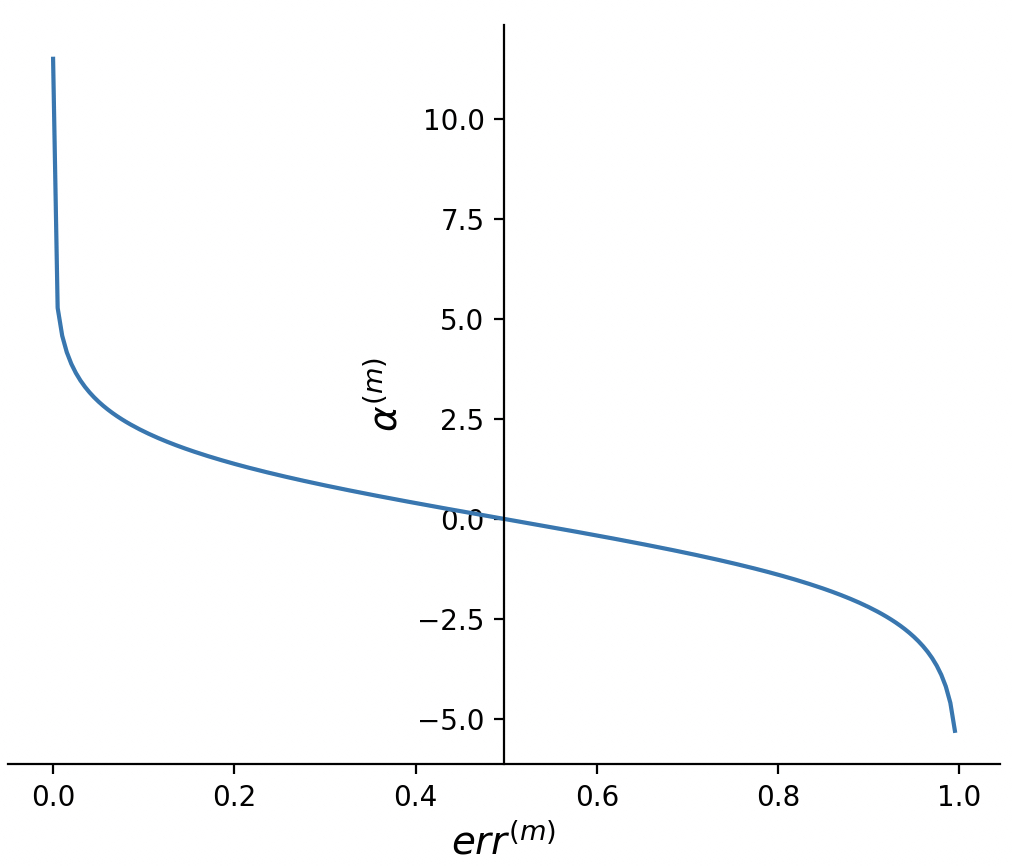
从图9-11可以看出,当模型误差$err^{(m)}$大于0.5时,模型权重$\alpha^{(m)}$将会小于0,而根据式(9-9)可知此时$w_i$将会乘以一个小于1的数,从而使得$w_i$朝着错误的方向(变小)进行更新,这显然与Adaboost的思想相违背(越容易分错的样本点对应的样本权重越大)。
由于在二分类场景下,我们总能相对容易地找到误差小于0.5(可以近似的看成准确率)的模型,但是随着分类数量的增加初始时模型的误差很难再小于0.5,而这将导致被上一个模型分类错误的样本在下一个模型中同样得不到修正。
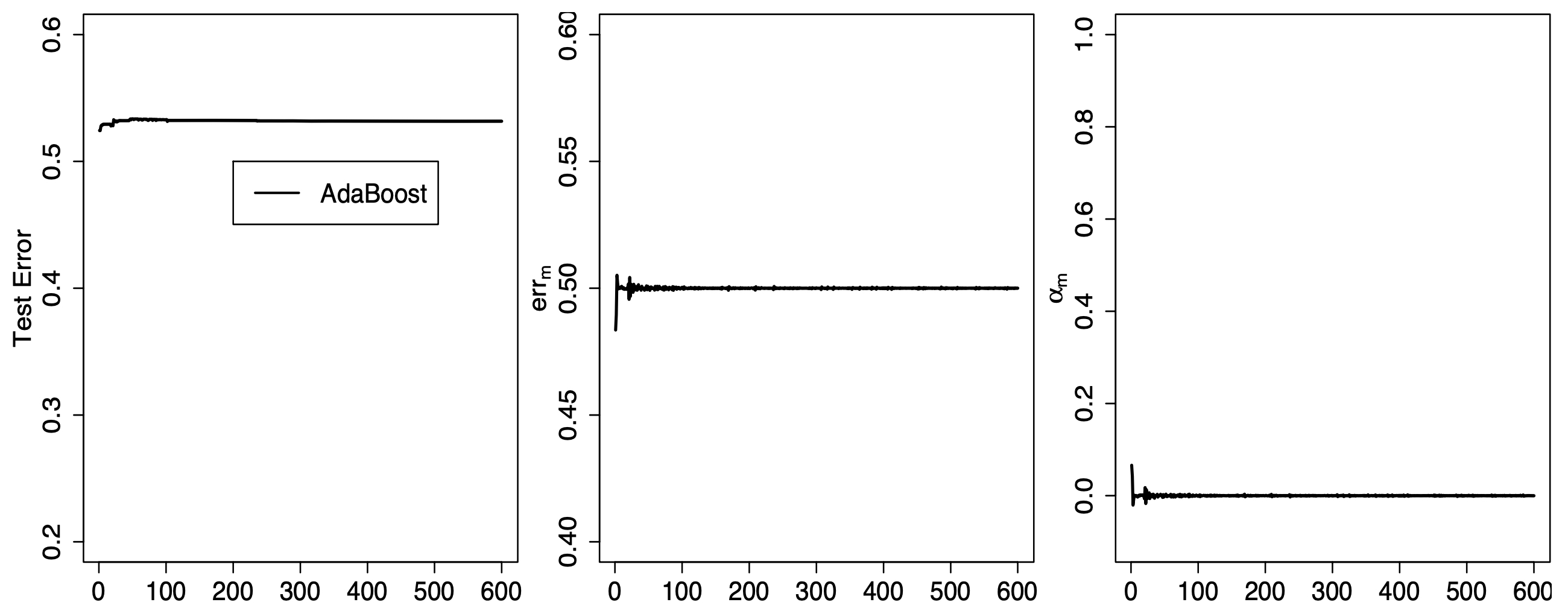
如图9-12所示为AdaBoost模型在某个三分类数据集上(训练集和测试集随机划分10次)训练后在测试集上的平均结果。从图9-12左侧的结果可知,AdaBoost在迭代伊始测试误差便大于0.5,且随着迭代次数的增加最终稳定在0.53左右,也就是说随着迭代过程的增加模型的拟合能力并没有提升。根据图9-12中间的结果可知,模型误差$err^{(m)}$先是小于0.5,然后在若干次迭代之后便稳定在了0.5附近,而这也导致模型权重$\alpha^{(m)}$从一开始的大于0到在若干次迭代后便一直处于0附近,如图9-12右所示。根据式(9-9)可知,当$\alpha^{(m)}=0$时,$w_i$将会保持不变,进而使得被错分类的样本点得不到修正。
基于原始AdaBoost算法所存在的问题,Hastie等人[6]在2009年提出了一种基于AdaBoost改进的多分类AdaBoost算法——基于指数损失函数的多分类分步加法模型( Stagewise Additive Modeling using a Multi-class Exponential loss function, SAMME)。同时,在sklearn中只需要在实例化AdaBoostClassifier类时将 algorithm参数指定为'SAMME'即可使用SAMME算法,这里就不再重复进行示例,参考9.4.2节内容即可。
9.5.2 SAMME算法原理#
SAMME算法的思想和整体框架同AdaBoost一样,仅仅只是用了一种特殊的形式来表示每个模型的预测输出,并最终得到了在多分类场景下AdaBoost的更新迭代公式,具体的详细求解过程将在后续进行介绍。
假设 $g^{(m)}(x),m=1,2,...,M$ 为 $M$ 个基模型,数据集$(x_1,\boldsymbol{y}_1),(x_2,\boldsymbol{y}_2),...,(x_n,\boldsymbol{y}_n)$一共有$n$个样本,且 $\boldsymbol{y}_i$ 是一个类似于one-hot编码的 $K$ 维向量,则SAMME算法可以通过如下过程来进行表示:
(1) 初始化每个样本的权重为$w_i=1/n$;
(2) 使用训练集训练得到基模型 $\boldsymbol{g}^{(m)}(x)$,其输出形式为一个 $K$ 维向量;
(3) 根据式(9-29)~式(9-31)分别迭代计算每个基模型 $\boldsymbol{g}^{(m)}(x)$对应下的分类误差$err^{(m)}$,模型权重$\alpha^{(m)}$和样本权重$w_i$
$$ err^{(m)}=\frac{\sum_{i=1}^nw_i\cdot\mathbb{I}\left(c_i\neq T^{(m)}(x_i)\right)}{\sum_{i=1}^nw_i}\tag{9-29} $$$$ \alpha^{(m)}=\log\frac{1-err^{(m)}}{err^{(m)}}+\log(K-1)\tag{9-30} $$$$ \begin{aligned} &w_i\leftarrow w_i\cdot\exp \left(\alpha^{(m)}\cdot\mathbb{I}\left(c_i\neq T^{(m)}(x_i)\right)\right),i=1,2,...,n \\[2ex] &w_i\leftarrow \frac{w_i}{\sum_{j=1}^nw_j} \end{aligned}\tag{9-31} $$其中 $c_i$ 表示标签 $\boldsymbol{y}_i$ 对应的类别编号; $T^{(m)}(x_i)$ 为根据 $\boldsymbol{g}(x)$ 得到的预测类别编号;$K$ 表示分类的类别数。
(3) 将训练得到的$M$个基模型根据式(9-32)中的方式进行集成,然后输出得到样本的预测结果
$$ C(x)=\arg \max_{k}=\sum_{m=1}^M\alpha^{(m)}\cdot \mathbb{I}(T^{(m)}(x)=k)\tag{9-32} $$其中$\mathbb{I}(\cdot)$为指示函数,条件成立时取1,不成立时取0。
从上述过程可以看出,SAMME算法与之前的二分类AdaBoost算法的唯一差别就是体现在公式(9-30)上,前者多了 $\log(K-1)$ 这一项。进一步,根据式(9-30)可知,为了使得$\alpha^{(m)}>0$,则必须有
$$ 1-err^{(m)}>\frac{1}{K}\tag{9-33} $$同时,可以发现当$K=2$时,上述求解过程便完全等价于AdaBoost算法了。
9.5.3 从零实现SAMME算法#
由于SAMME算法的求解推导过程稍显复杂,且目前已经知道了整个算法的求解过程,所以下面先来介绍如何从零实现SAMME算法,然后再介绍整个求解推导过程。根据9.5.2节内容中的求解过程可知,SAMME算法同样并不是某种特定算法的称谓,而是一种模型训练和预测的策略。因此下面将以前面介绍的多项式朴素贝叶斯(MultinomialBN)算法作为基模型进行实现。
1. 带权重的朴素贝叶斯
根据9.4节介绍的内容可知,AdaBoost算法会为每个样本赋予一个权重值,在上一个模型中被错分的样本在下一个模型中将具有更高的权重,以此来尽可能保证每个样本都能够被划分正确。因此,对于每个基模型来说还需要在原有算法基础之上实现样本权重对分类结果的影响,而这也是为什么sklearn框架中基本上每个算法都有sample_weight这个参数的缘故(默认情况下其取值为None,即不考虑样本权重,也可以理解为等权重)。
同时,对于每个算法模型来说都有不同的策略来考虑如何将样本权重融入到模型中,即每个算法在加入样本权重后的实现方式不同。下面,以最简单的多项式朴素贝叶斯算法为例来进行介绍整体的思想原理。
根据第7章对朴素贝叶斯算法原理的介绍可知,贝叶斯算法在求解过程中的一个关键因素就是计算得到每个样本可能属于某个类别的先验概率,即$P(Y=c_k)$。在贝叶斯算法中,可以通过最大似然估计,即训练集中每个类别$c_k$下对应样本的数量在总样本数中的占比来求得相应的先验概率$P(Y=c_k)$。因此,基于类似的想法我们还可以人工经验来调整相应的先验概率,即根据重要性人为地赋予每个样本一个权重值,并最终作用于先验概率。
例如现有某三分类数据集的标签为y=[0,1,1,2,2],其对应每个样本的权重为sample_weight=[0.1,0.1,0.3,0.4,0.1],则此时有:
① 不考虑样本权重时每个类别的先验概率为:
$$ \begin{aligned} P(y=0)&=\frac{1}{5}=0.2\\[1ex] P(y=1)&=\frac{2}{5}=0.4\\[1ex] P(y=2)&=\frac{2}{5}=0.4\\[1ex] \end{aligned}\tag{9-34} $$② 考虑样本权重时每个类别的先验概率为:
首先需要将原始标签转换为One-hot编码形式,即Y=[[1,0,0],[0,1,0],[0,1,0],[0,0,1],[0,0,1]],然后再以按位乘的方式计算其与sample_weight的乘积,结果为[[0.1,0,0],[0,0.1,0],[0,0.3,0],[0,0,0.4],[0,0,0.1]],进一步对该结果在列上进行求和可得[0.1,0.4,0.5],最后每个类别的先验概率为
最后,上述过程可以通过如下方式来计算,示例代码如下:
1 def compute_class_prior(y, sample_weight=None):
2 labelbin = LabelBinarizer()
3 Y = labelbin.fit_transform(y)
4 if sample_weight is not None:
5 Y = Y.astype(np.float64, copy=False)
6 sample_weight = np.reshape(sample_weight, [1, -1]) # [1,n_samples]
7 Y *= sample_weight.T # [n_samples,n_classes_] * [n_samples,1] 按位乘
8 class_count = Y.sum(axis=0) # Y: shape(n,n_classes) Y.sum(): shape(n_classes,)
9 class_prior = class_count / class_count.sum()
10 return class_prior在上述代码中,第2~3行将标签转化为one-hot形式。第4~7行则是根据sample_weight重新调整标签矩阵Y。第8~9行则是计算每个类别的先验概率。完整示例代码可参见 AllBooKCode/Chapter09/C12_bayes_class_prior.py 文件。
2. 定义初始化方法
在完成多项式朴素贝叶斯算法中样本权重的计算实现后,接下来便可以一步一步实现整个SAMME算法。首先,根据需要定义一个名为MyAdaBoostClassifier的类,并定义其对应的初始化方法,示例代码如下:
1 class MyAdaBoostClassifier():
2 def __init__(self, base_estimator=None,
3 n_estimators=50, algorithm='SAMME'):
4 self.algorithm = algorithm
5 self.n_estimators = n_estimators
6 self.base_estimator = base_estimator
7 self.estimators_ = [] # 保存所有的分类器
8 self.estimator_weights_ = np.zeros(self.n_estimators, dtype=np.float64)
9 self.estimator_errors_ = np.zeros(self.n_estimators, dtype=np.float64)在上述代码中,第4~6行中base_estimator表示指定相应的基模型,n_estimators表示基模型的数量,algorithm表示指定相应的Boost算法。第7行定义一个列表用于后续保存所有的基模型。第8行定义一个向量用于后续保存每个模型对应的权重。第9行用于后续保存每个模型拟合后对应的误差。
3. SAMME计算过程实现
接着,根据式(9-29)~式(9-31)来实现SAMME算法的整体计算过程,示例代码如下:
1 def _single_boost_samme(self, iboost, X, y, sample_weight):
2 estimator = deepcopy(self.base_estimator) # 克隆一个分类器
3 self.estimators_.append(estimator) # 保存每个分类器
4 estimator.fit(X, y, sample_weight=sample_weight)
5 y_predict = estimator.predict(X)
6 if iboost == 0:
7 self.classes_ = getattr(estimator, 'classes_', None)
8 self.n_classes_ = len(self.classes_)
9 incorrect = y_predict != y
10 estimator_error = np.average(incorrect, weights=sample_weight, axis=0)
11 if estimator_error >= 1. - (1. / self.n_classes_):
12 self.estimators_.pop(-1)
13 if len(self.estimators_) == 0:
14 raise ValueError('BaseClassifier ......')
15 return None, None, None
16 estimator_weight = np.log((1. - estimator_error) /
17 estimator_error) + np.log(self.n_classes_ - 1.)
18 sample_weight *= np.exp(estimator_weight * incorrect)
19 return sample_weight, estimator_weight, estimator_error
20
21 def _boost(self, iboost, X, y, sample_weight):
22 if self.algorithm == 'SAMME':
23 return self._single_boost_samme(iboost, X, y, sample_weight)在上述代码中,第1行里iboost表示对第iboost个基模型进行拟合,X,y表示训练集,sample_weight表示当前状态下的样本权重。第2~5行分别是先克隆一个新的基模型,然后进行保存,进一步根据训练集对其进行拟合,最后让该基模型对训练集中的样本进行预测。第6~8行是用来获取训练集中样本的类别和类别数。第9~10行则是实现式(9-29)对应的计算过程。第11~15行则是判断当前分类器的误差不满足式(9-33)中的条件时的处理流程。第16~18行则是分别实现式(9-30)和式(9-31)中样本权重的计算过程。第21~23行则是对不同的Boost算法进行整合,例如还SAMME.R等算法。
4. SAMME算法拟合过程实现
在完成SAMME算法的单步拟合过程后便可以进一步完成整个模型的训练过程,示例代码如下:
1 def fit(self, X, y, sample_weight=None):
2 if sample_weight is None:
3 sample_weight = np.ones(len(X), dtype=np.float64)
4 sample_weight /= sample_weight.sum()
5 for iboost in range(self.n_estimators):
6 sample_weight, estimator_weight, estimator_error = self._boost(
7 iboost, X, y, sample_weight)
8 if sample_weight is None:
9 break
10 self.estimator_weights_[iboost] = estimator_weight
11 self.estimator_errors_[iboost] = estimator_error
12 if estimator_error == 0:
13 break
14 sample_weight_sum = np.sum(sample_weight)
15 if sample_weight_sum <= 0:
16 break
17 sample_weight /= sample_weight_sum
18 return self在上述代码中,第2~4行用于判断sample_weight是否为None,如果是则进行等权重初始化,然后进行权重标准化。第5~17行则是完成所有基模型的训练迭代过程,其中第8~9行处理当不满足式(9-33)中的条件时则提前结束训练。第10~11行分别用于保存分类器权重和误差。第12~16行同样用于判断是否提前结束训练。第17行则是本次更新后的样本权重进行标准化。
5. 模型预测实现
在完成整个模型训练过程的实现后,最后只需要再根据式(9-32)完成预测过程即可,示例代码如下:
1 def predict(self, X):
2 classes = self.classes_[:, np.newaxis]
3 pred = np.zeros([len(X), len(self.classes_)])
4 for estimator, alpha in zip(self.estimators_, self.estimator_weights_):
5 correct = estimator.predict(X) == classes
6 result = alpha * correct.T
7 pred += result
8 pred /= self.estimator_weights_.sum()
9 y_pred = np.argmax(pred, axis=1)
10 return y_pred在上述代码中,第2行是得到训练集的分类类别,形状为[n_classes,1]。第3行是初始化一个全0矩阵用于累加每个模型的预测结果。第4~7行开始遍历每个模型以及其对应的模型权重,其中第5行用于得到当前基模型的预测情况,形状为[n_classes,n_samples];第6~7行则是将分类器权重分别作用于相应的预测结果并进行累加,形状为[n_samples,n_classes]。第8~9行则先是对预测置信度结进行标准化然后得到最终的预测结果。
6. 使用示例
在完成上述所有的过程的编码实现后,可通过如下方式进行使用,示例代码如下:
1 from Chapter07.C02_naive_bayes_multinomial import MyMultinomialNB
2 from sklearn.naive_bayes import MultinomialNB
3 if __name__ == '__main__':
4 x, y = load_iris(return_X_y=True)
5 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
6 clf = MyAdaBoostClassifier(base_estimator=MyMultinomialNB(), n_estimators=10)
7 clf.fit(x_train, y_train)
8 print(accuracy_score(y_test, clf.predict(x_test)))
9
10 clf = AdaBoostClassifier(base_estimator=MultinomialNB(), n_estimators=10, algorithm='SAMME')
11 clf.fit(x_train, y_train)
12 print(accuracy_score(y_test, clf.predict(x_test)))在上述代码中,第1~2行分别用于导入7.4节实现的MyMultinomialNB模块和sklearn中的MultinomialNB模块以进行对比。第6~7和10~11行则是分别利用MyMultinomialNB和MultinomialNB作为基模型初始化两个AdaBoost实例化模型并进行拟合。第8~12行则分别是两者在测试集上的预测准确率。
上述代码运行结束后可以看到类似如下所示的结果:
1 0.9777
2 0.9777到此,对于整个SAMME算法的实现过程就介绍完了,以上完整代码可参见代码仓库 AllBooKCode/Chapter09/C13_adaboost_imp.py 文件。
9.5.4 SAMME算法损失函数#
在介绍完SAMME算法的实现过程之后,接下来我们再来详细介绍其具体的求解推导过程。在9.5.2节中的内容我们介绍到,SAMME算法采用了一种特殊的形式来表示每个模型的预测输出。具体地,在 $K$ 分类任务场景下设标签 $ \boldsymbol{y}=(y_1,y_2,...,y_K)^T$ 为一个$K$维向量,即
$$ y_k= \begin{cases} 1, & \text {if } c = k \\[2ex] -\frac{1}{K-1}, & \text{if } c\neq k\end{cases}\tag{9-36} $$从式(9-36)可以看出,当且仅当样本的标签类别 $c$ 等于 $k$ 时,向量 $ \boldsymbol{y} $ 的第 $k$ 个维度才为1,这也相当于是把 one-hot 编码中所有的0全部替换为了$-\frac{1}{K-1}$。
进一步,在基于式 (9-36) 这样的标签形式下,多分类场景下基于指数损失的损失函数表示为
$$ L(\boldsymbol{y},\boldsymbol{f})=\exp\left(-\frac{1}{K}(y_1f_1+y_2f_2+\cdots+y_Kf_K)\right)=\exp\left(-\frac{1}{K}\boldsymbol{y}^T\boldsymbol{f}\right)\tag{9-37} $$其中$\boldsymbol{f}=(f_1,f_2,...,f_K)^T$,$f_k$ 表示模型第 $k$ 个维度对应的输出结果是一个标量与式(9-36)中的 $y_k$ 相对应,同时由于每个样本的预测结果有 $K$ 维度,因此在计算损失的时候一般需要除以 $K$。