4.3过拟合#
在4.2节中,我们以线性回归和逻辑回归为例详细介绍了为什么需要对特征维度进行标准化,以及不进行标准化会带来什么样的后果。接下来,我们继续介绍机器学习中其它改善模型的方法和策略。
4.3.1模型拟合#
在2.5节内容中,我们首次引入了梯度下降算法并以此来最小化线性回归中的目标函数,在经过多次迭代后便可以求解得到模型中对应的参数。此时可以发现,模型的参数是一步一步根据梯度下降算法更新而来,直至目标函数收敛,也就是说这是一个循序渐进的过程,因此,这一过程也被称作是拟合(Fitting)模型参数的过程,当这个过程执行结束后就会产生3种状态,即过拟合(Overfitting)、恰拟合(Goodfitting)和欠拟合(Underfitting)。
进一步,在线性回归中我们介绍了几种评估回归模型常用的指标,但现在有一个问题: 当MAE或者RMSE越小时就代表模型越好吗?还是说在某种条件下其越小就越好呢?细心的读者可能一眼便明了,肯定是有条件下的越小所对应的模型才越好。那这其中到底是怎么回事呢?
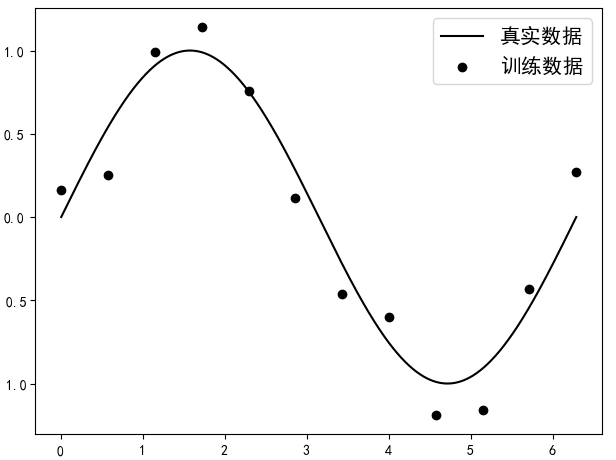
假设现在有一批样本点,它本是由函数$sin(x)$生成(现实中并不知道)的,但由于其他因素的缘故,使我们得到的样本点并没有准确地落在曲线$sin(x)$上,而是分布在其附近,如图4-14所示。
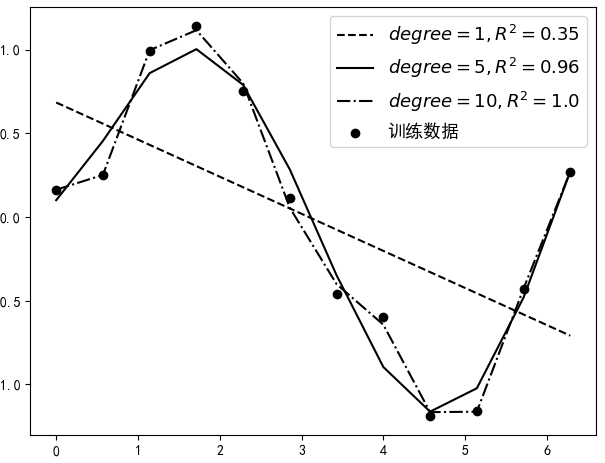
从图4-15中可以看出,随着多项式次数的增大,$R^2$指标的值也越来越大($R^2$的值越大预示着模型就越好),并且当次数设置为10的时候,$R^2$达到了1.0,但是最后就应该选degree=10对应的这个模型吗?
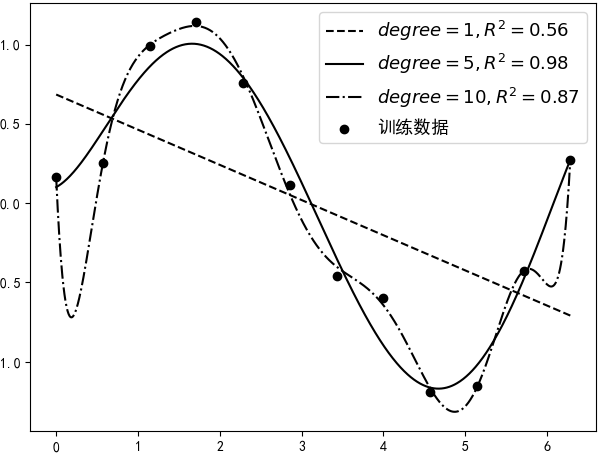
假如不知过了多久,突然一名客户要买你的这个模型进行商业使用,同时客户为了评估这个模型的效果自己又带来了一批新的含标签的数据(虽然这个模型已经用$R^2$测试过,但客户并不会完全相信,万一你对这个模型作弊呢)。于是你拿着客户的新数据(也是由$sin(x)$所生成的),然后分别用上面的3个模型进行预测,并得到了如图4-16所示的可视化结果。
4.3.2 过拟合与欠拟合#
在机器学习中,通常将建模时所使用的数据叫做训练集(Training Dataset),例如图4-14中的12个样本点。将测试时所使用的数据集叫做测试集(Testing Dataset)。同时把模型在训练集上产生的误差叫做训练误差(Training Error),把模型在测试集上产生的误差叫做测试误差(Testing Error)或泛化误差(Generalization Error),最后也将整个拟合模型的过程称作训练(Training)[7]。
进一步讲,将4.3.1节中degree=10时所产生的现象叫做过拟合(Overfitting),即模型在训练集上的误差很小,但在测试集上的误差却很大,也就是泛化能力弱; 相反,将其对立面degree=1时所产生的现象叫做欠拟合(Underfitting),即模型训练集和测试集上的误差都很大; 同时,将degree=5时的现象叫做恰拟合(Goodfitting),即模型在训练集和测试集上都有着不错的效果。
同时,需要说明的是,在4.3.1节中我们仅仅以多项式回归为例来向读者直观地介绍了什么是过拟合与欠拟合,但并不代表这种现象只出现在线性回归中,事实上所有的机器学习模型都会存在着这样的问题,因此一般来讲,所谓过拟合现象指的是模型在训练集上表现很好,而在测试集上表现却糟糕,欠拟合现象是指模型在两者上的表现都十分糟糕,而恰拟合现象是指模型在训练集上表现良好(尽管可能不如过拟合时好),但同时在测试集上也有着不错的表现。
4.3.3 解决欠拟合与过拟合问题#
1. 如何解决欠拟合问题
经过上面的描述我们已经对欠拟合有了一个直观的认识,所谓欠拟合就是训练出来的模型根本不能较好地拟合现有的训练数据。要解决欠拟合问题相对来讲较为简单,主要分为以下3种方法:
(1) 重新设计更为复杂的模型,例如在线性回归中可以增加特征映射多项式的次数。
(2) 设计新的特征,收集或设计更多的特征维度作为模型的输入,即根据已有特征数据组合设计得到更多新的特征,这有点类似于上一点。
(3) 减小正则化系数,当模型出现欠拟合现象时,可以通过减小正则化中的惩罚系数来减缓欠拟合现象,这一点将在4.4节中进行介绍。
2. 如何解决过拟合问题
对于如何有效地缓解模型的过拟合现象,常见的做法主要分为以下4种方法:
(1) 收集更多数据,这是一个最为有效但实际操作起来又是最为困难的一种方法。训练数据越多,在训练过程中也就越能够纠正噪声数据对模型所造成的影响,使模型不易过拟合,但是对于新数据的收集往往有较大的困难。
(2) 降低模型复杂度,当训练数据过少时,使用较为复杂的模型极易产生过拟合现象,例如4.3.1节中的示例,因此可以通过适当减少模型的复杂度来达到缓解模型过拟合的现象。
(3) 正则化方法,在出现过拟合现象的模型中加入正则化约束项,以此来降低模型过拟合的程度,这部分内容将在4.4节中进行介绍。
(4) 集成方法,将多个模型集成在一起,以此来达到缓解模型过拟合的目的,这部分内容将在第9章中进行介绍。
3. 如何避免过拟合
为了避免训练出来的模型产生过拟合现象,在模型训练之前一般会将获得的数据集划分成两部分,即训练集与测试集,且两者一般为7∶3的比例。其中训练集用来训练模型(降低模型在训练集上的误差),然后用测试集来测试模型在未知数据上的泛化误差,观察是否产生了过拟合现象 [8]。
但是由于一个完整的模型训练过程通常会先用训练集训练模型,再用测试集测试模型,而绝大多数情况下不可能第1次就选择了合适的模型,所以又会重新设计模型(如调整多项式次数等)进行训练,然后用测试集进行测试,因此在不知不觉中,测试集也被当成了训练集在使用,所以这里还有另外一种数据的划分方式,即训练集、验证集(Validation Data)和测试集,且一般为7∶2∶1的比例,此时的测试集一般通过训练集和验证集选定模型后做最后测试所用。
实际训练中应该选择哪种划分方式呢?这一般取决于训练者对模型的要求程度。如果要求严苛就划分为3份,如果不那么严格,则可以划分为2份,也就是说这两者并没硬性的标准。
4.3.4 小结#
在这节中,我们首先介绍了什么是拟合,进而介绍了拟合后带来的3种状态,即欠拟合、恰拟合与过拟合,其中恰拟合的模型是我们最终所需要的结果。接着,我们介绍了解决欠拟合与过拟合的几种方法,其中解决过拟合的两种具体方法将在后续的内容中分别进行介绍。最后,我们还介绍了两种方法来划分数据集,以尽可能避免产生模型过拟合的现象。