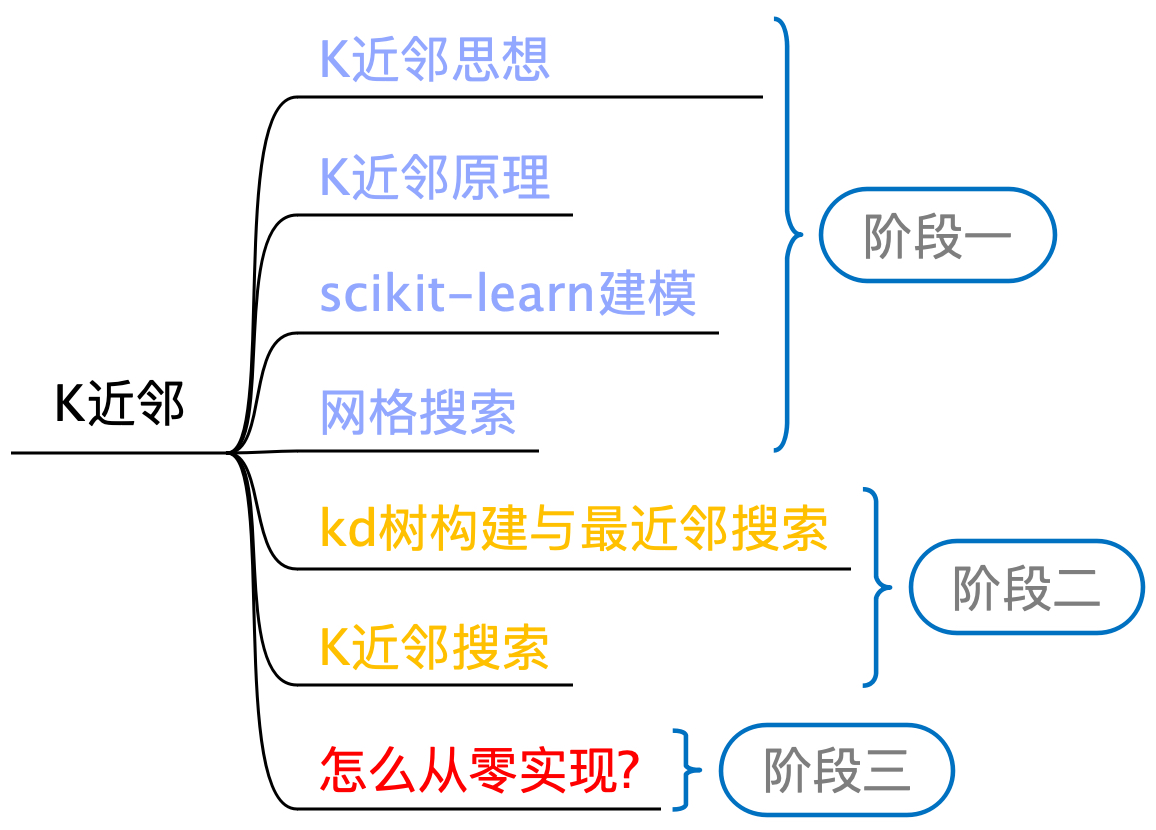
在前几章中,我们分别介绍了线性回归、逻辑回归及模型的改善与泛化。从这章开始,我们将继续学习下一个新的算法模型——K近邻(K-Nearest Neighbor, KNN)。整个K近邻算法的学习路线如图5-1所示,整体来看掌握阶段一的内容相对简单并且这里还加入了sklearn中的网格搜索模块的内容介绍,而后面两个阶段的内容则具有一定的难度,主要集中在kd树的构建和搜索的原理及实现过程,各位读者可以按需进行学习。
5.1 K近邻思想#
从K近邻的这一名字可以看出,这一算法的核心在于数量“K”和状态“近邻”。某一天,你和几位朋友准备去外面聚餐,但是就晚上吃什么菜一直各持己见。最后,无奈的你提出用少数人服从多数人的原则进行选择。于是你们每个人都将自己想要吃的东西写在了纸条上,最后的统计情况是: 3个人赞成吃火锅、2个人赞成吃炒菜、1个人赞成吃自助。当然,最后你们一致同意按照多数人的意见去吃了火锅。那这个吃火锅和K近邻有什么关系呢?吃火锅确实跟K近邻没关系,但是整个决策的过程却完全体现了K近邻算法的决策过程。