10.2 SVM线性不可分#
在上一节内容中我们介绍了SVM算法的基本思想,即找到一个决策面使得它到两边最近样本点之间的距离最大,因此SVM也被称之为最大间隔分类器。在本节内容中将开始介绍SVM中的特征映射与核函数,以及如何通过sklearn来完成整个建模过程。
10.2.1 SVM线性不可分与特征映射#
根据10.1节内容中SVM的思想来看,到目前为止谈到的情况都是线性可分的,也就是说总能找到一个超平面将样本点给分开。可事实上却是,在大多数场景中各个类别之间是线性不可分的,即类似于如图10-5所示的情况。
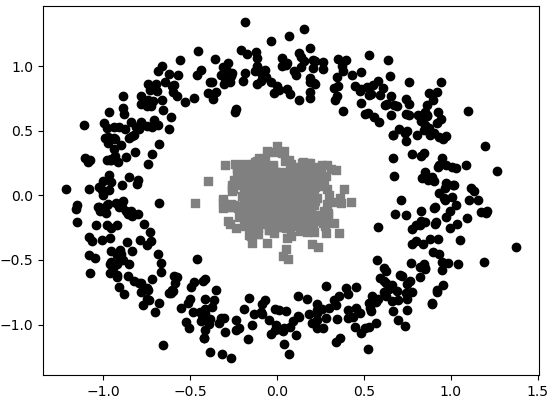
对于图10-5中这种情况应该怎么才能将其分开呢?在4.2.4节内容中我们介绍过,这类问题可以使用特征映射的方法将原来的输入特征映射到更高维度的空间,然后寻找一个超平面,以此将数据集中不同类别的样本进行分类,如图10-6所示。
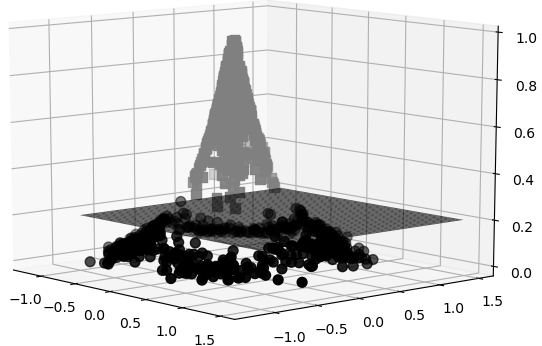
为了能够实现将特征从原始低维空间映射到高维空间,在SVM建模过程中可以使用核函数来达成这一目的。关于核函数的详细原理可以参见10.8节内容,对于第一阶段内容的学习,只需要知道这些核函数的作用和用法即可。
10.2.2 SVM示例代码#
在sklearn中可以通过from sklearn.svm import SVC这行代码导入SVM分类模型。有读者可能会觉得奇怪,为什么导入的是一个叫SVC的东西?这是因为其实SVM不仅可以用来分类,它同样也能用于回归问题,因此SVC其实就是支持向量分类的意思。下面,首先来对类SVC中的几个常用参数进行简单介绍,示例代码如下:
1 def __init__(self, C=1.0, kernel='rbf', degree=3):在上述代码中,第1行C表示SVM中的惩罚项系数,越大对误分类样本的惩罚就越大,其作用等同于正则化中的参数𝜆,详细原理将在10.4节内容中进行介绍;kernel是指定对应的核函数,默认情况下可直接使用高斯核函数kernel='rbf',即将特征维度映射到无穷维空间中;degree表示指定多项式核函数的次数,仅在kernel='poly'时有效。
在完成SVC的导入以后便可以将其用于分类任务中,完整示例代码可参见 AllBooKCode/Chapter10/C05_linear_svm.py 文件,示例代码如下:
1 def train(x_train, x_test, y_train, y_test):
2 model = SVC(C=1.0,kernel='linear')
3 model.fit(x_train, y_train)
4 y_pre = model.predict(x_test)
5 print(f"准确率为:{model.score(x_test, y_test)}")
6 # 准确率为:0.9759上述代码便是通过sklearn实现SVM建模的全部代码。可以看出,在sklearn中使用一个模型的步骤依旧是在5.3.1节中总结的3步: 建模、训练和预测。同时,这里我们依旧可以通过网格搜索来进行模型超参数的选择。从最后在测试集上的结果来看,线性SVM分类器的表现在准确率上也有着不错的结果。
10.2.3 小结#
在本节中,我们首先介绍了SVM中的线性不可分情况,并且介绍了可以通过将原始特征映射到高维空间中的方法来解决这一问题;然后介绍了如何利用sklearn来完成SVM的建模过程以及核函数的使用方法。不过这里仅仅只是介绍了核函数的使用,在后续文章中还将更加详细地来介绍核函数的相关原理,以及为什么使用核函数能够将低维特征映射到无穷维等。