10.19 百川大模型实现#
在10.18节内容中我们详细介绍了Baichuan2模型的推理使用方法以及如何根据我们自己的需要来对基座模型进行微调。在本节内容中我们将进一步详细介绍Baichuan2模型的内部实现细节。由于百川大模型是基于Transformers框架所实现,因此在正式介绍百川大模型的实现原理之前我们先来看一下Transformers中对于基于Transformer解码器的模型在解码时的Key-Value缓存机制。
10.19.1 解码缓存原理#
根据10.3节内容可知,解码器在解码预测每个时刻时都涉及计算Query与Key之间的注意力权重,并通过对Value的加权求和来生成输出。为了避免在生成序列时的重复计算,特别是在处理长序列时,缓存机制允许解码器存储并复用先前计算的Key和Value。这样一来,相同的查询Query在不同时间步中便能够直接使用之前计算得到的结果,在减少了计算复杂度同时也提高了序列生成过程的速度。
现在假定我们已经训练得到了一个基于Transformer解码器的生成式模型,且模型的原始输入为一个长度为3的序列,那么它在第4个时刻的解码输出过程便可以通过图10-64来进行表示。
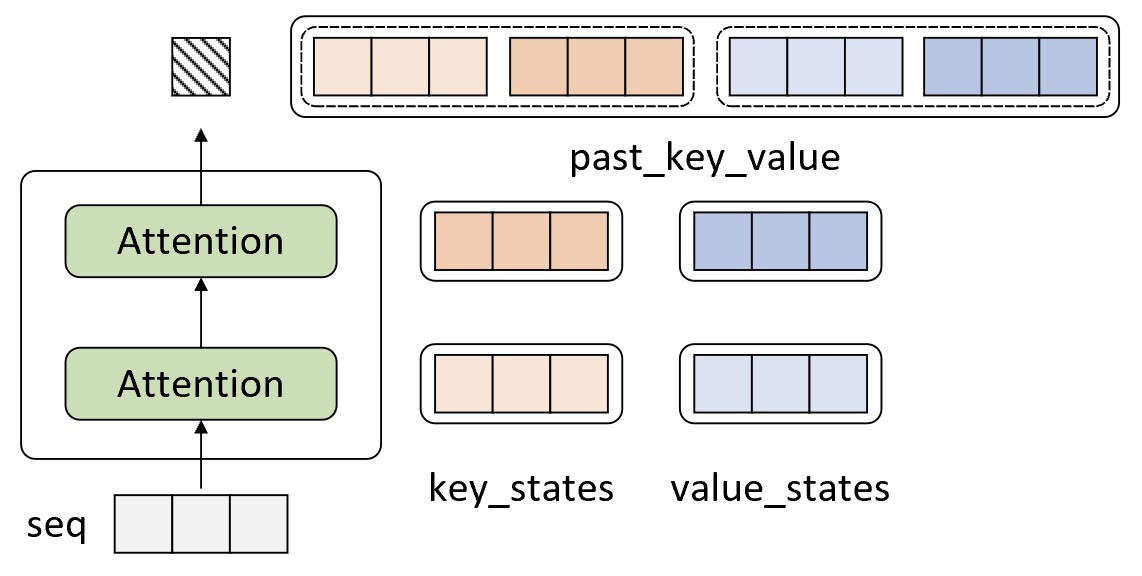
在图10-64中,输入序列在经过两个注意力层以后预测得到了第4个时刻的输出。如果是传统的解码方式,那么在解码第5个时刻时将会把原始的输入序列同第4个时刻的输出拼接在一起作为新的输入进行解码预测,后续过程以此类推。可以发现,在这种解码方式中对第$t$个时刻进行解码输出时,前面第$t-1$个时刻的输入都是重复的,而这就导致在自注意力的计算过程中前面第$t-1$个时刻的计算是重复的。
因此,在基于缓存机制的解码过程中,解码器在对第$t$个时刻进行解码时会直接使用前$t-1$个时刻缓存得到的key_states和value_states来计算第$t$时刻的输出。例如在图10-64所示的过程中,当解码器对第4个时刻进行解码时将会缓存此时计算得到的key_states和values_states并通过一个元组past_key_value进行表示。进一步,解码器在对第5个时刻进行解码时可以通过图10-65所示的过程表示。
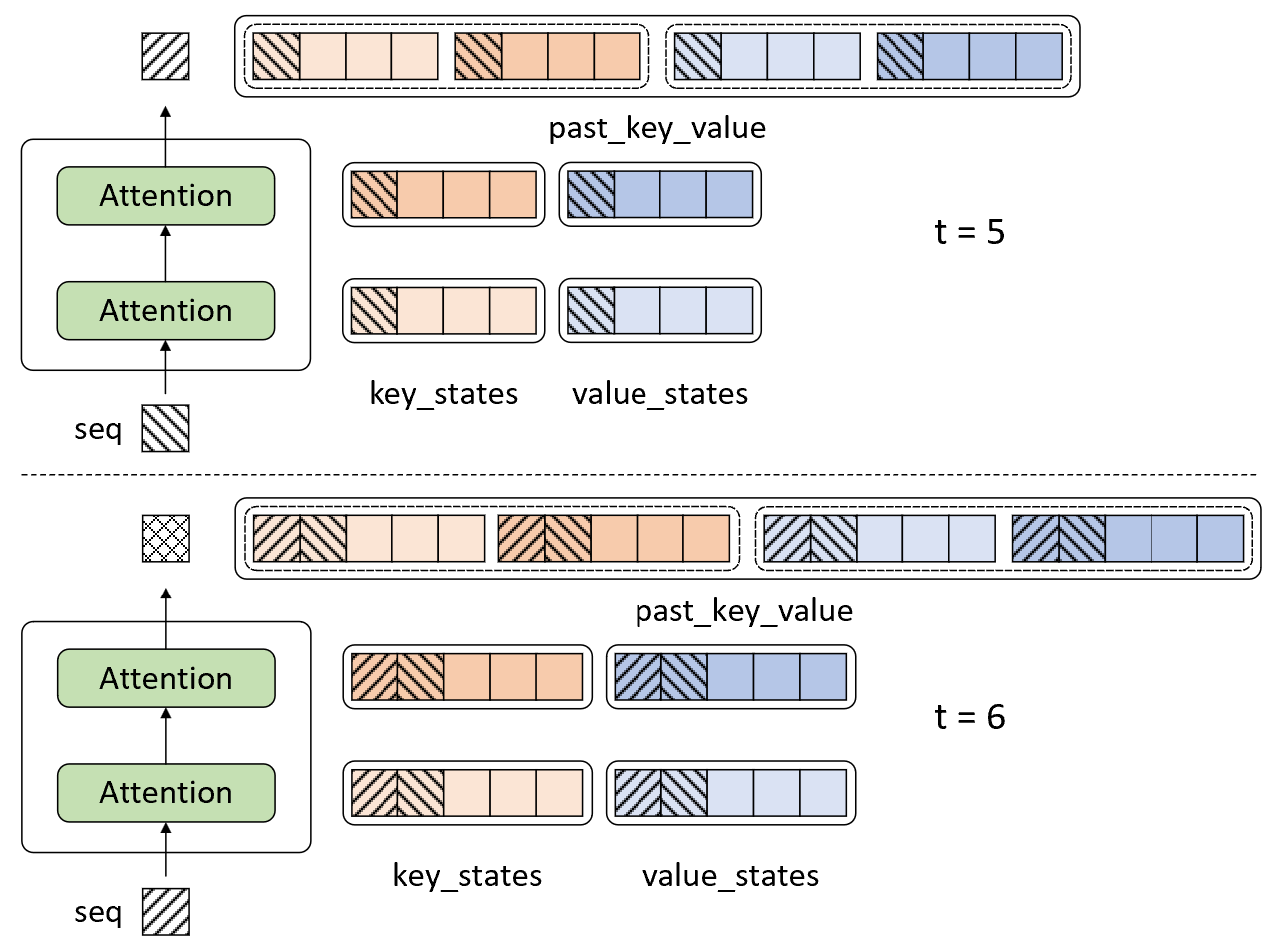
如图10-65所示,解码器在对第5个时刻解码时其输入只有第4个时刻的输出,并且会将当前时刻输入经过线性变换计算得到的key_states和values_states同之前缓存的状态拼接起来得到新的key_states和values_states,以此同query_states计算得到第5个时刻的注意力输出。最后,对于第6个时刻的解码输出过程各位读者可以根据图示自行理解,这里就不再赘述。
在这里,我们还可以通过如下示例代码来验证Baichuan2模型中解码器的输出结果:
1 def test_BaichuanModel():
2 config = BaichuanConfig.from_pretrained('./Baichuan2_7B_Chat')
3 model = BaichuanModel(config)
4 past_key_values = None
5 inp = torch.randint(0, 100, [1, 3])
6 for i in range(4,7):
7 print(f"第{i}个时刻输出: ")
8 result = model(inp, past_key_values=past_key_values)
9 print(f"last_hidden_state的形状: {result.last_hidden_state.shape}")
10 past_key_values = result.past_key_values
11 print(f"len(past_key_values): {len(past_key_values)}")
12 print(f"len(past_key_values[0]: {len(past_key_values[0])}")
13 print(f"past_key_values[0][0].shape: {past_key_values[0][0].shape}")
14 inp = torch.randint(0, 100, [1, 1])在上述代码中,第2~3行是根据本地配置文件实例化一个BaichuanModel类对象。第7~14行便是模拟解码器的解码输出过程。上述代码运行结束以后便会得到如下输出内容。
1 第4个时刻输出:
2 last_hidden_state的形状: torch.Size([1, 3, 4096])
3 len(past_key_values): 32
4 len(past_key_values[0]: 2
5 past_key_values[0][0].shape: torch.Size([1, 32, 3, 4096])
6 第5个时刻输出:
7 last_hidden_state的形状: torch.Size([1, 1, 4096])
8 len(past_key_values): 32
9 len(past_key_values[0]: 2
10 past_key_values[0][0].shape: torch.Size([1, 32, 4, 4096])
11 第6个时刻输出:
12 last_hidden_state的形状: torch.Size([1, 1, 4096])
13 len(past_key_values): 32
14 len(past_key_values[0]: 2
15 past_key_values[0][0].shape: torch.Size([1, 32, 5, 4096])在上述输出结果中,第2行表示对原始输入编码结果的输出,形状为[batch_size, seq_len, hidden_size],后面再通过一个分类层便可以得到第4个时刻的预测输出。第3~5行分别表示past_key_values缓存了32个注意力层中每一层的键值对,且形状为[batch_size, num_heads, seq_len, hidden_size]。第7~10行分别是第5个时刻的输出,以及past_key_values缓存结果,可以发现对于每一层中的键值序列其长度已经由3增加到了4,因为多了本层键值对的缓存。上述完整示例代码可参见Code/Chapter10/C07_BaiChuan2/main.py文件。这里需要提醒各位读者的是,当你们在学习运行上述示例代码时,可以把配置文件中的维度、层数、多头个数等设置小一点,这样就能快速验证结果。
10.19.2 解码层实现#
在介绍完Key-Value缓存机制以后我们再来看如何一步一步实现Baichuan2中的解码层。根据图10-62所示,整个解码层主要由自注意力模块和门控多层感知机所构成,下面分别进行介绍。这里需要提醒各位读者的是,以下各模块的类名对应的便是图10-62中的粗体字,阅读代码的时候结合图10-62的结构会更清晰。同时,为了内容排版的整洁性,我们去掉部分无关紧要的代码,但这并不影响我们对于Baichuan2模型整体实现的把握。更加详细的逐行注释内容可以参见本书所维护的Baichuan2模型代码[1],详见Code/Chapter10/C07_BaiChuan2/Baichuan2_7B_Chat目录。
1. 自注意力实现
Baichuan2模型中自注意力机制的实现过程同10.3.3节中Transformer里的注意力机制实现过程类似,区别在于此处考虑了Key-Value缓存和旋转位置编码。首先,我们需要定一个Attention类来完成相关成员变量的初始化工作,示例代码如下所示:
1 class Attention(nn.Module):
2 def __init__(self, config: BaichuanConfig):
3 super().__init__()
4 self.config = config
5 self.hidden_size = config.hidden_size
6 self.num_heads = config.num_attention_heads
7 self.head_dim = self.hidden_size // self.num_heads
8 self.max_position_embeddings = config.max_position_embeddings
9 if (self.head_dim * self.num_heads) != self.hidden_size:
10 raise ValueError(f"hidden_size must be divisible by num_heads")
11 self.W_pack = nn.Linear(self.hidden_size, 3 * self.hidden_size)
12 self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size)
13 self.rotary_emb = RotaryEmbedding(self.head_dim,
14 max_position_embeddings=self.max_position_embeddings)在上述代码中,第2行config是传入的实例化模型配置类对象。第4~10行是初始化多头注意力中的相关模型参数,并判断模型维度是否能被多头个数整除。第11行是同时初始化自注意力机制中Query、Key和Value对应的3个线性变换。第12行是将多头注意力输出进行线性变换,原理示意可参见图10-10部分的内容。第13~14行是实例化一个旋转编码实例化对象。
进一步,整个注意力机制的前向传播实现过程如下所示:
1 def forward(self, hidden_states, attention_mask = None, position_ids = None,
2 past_key_value = None,output_attentions = False, use_cache = False):
3 bsz, q_len, _ = hidden_states.size()
4 proj = self.W_pack(hidden_states)
5 proj = proj.unflatten(-1,(3,self.hidden_size)).unsqueeze(0).transpose(0,-2).squeeze(-2)
6 query_states = proj[0].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
7 key_states = proj[1].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
8 value_states = proj[2].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
9 kv_seq_len = key_states.shape[-2]
10 if past_key_value is not None:
11 kv_seq_len += past_key_value[0].shape[-2]
12 cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
13 query_states, key_states = apply_rotary_pos_emb(query_states,
14 key_states, cos, sin, position_ids)
15 if past_key_value is not None:
16 key_states = torch.cat([past_key_value[0], key_states], dim=2)
17 value_states = torch.cat([past_key_value[1], value_states], dim=2)
18 past_key_value = (key_states, value_states) if use_cache else None
19 attn_output = F.scaled_dot_product_attention(query_states, key_states, value_states,
20 attn_mask=attention_mask)
21 attn_output = attn_output.transpose(1, 2)
22 attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
23 attn_output = self.o_proj(attn_output)
24 if not output_attentions:
25 attn_weights = None
26 return attn_output, attn_weights, past_key_value在上述代码中,第1行hidden_states为解码层对应的输入,形状为[batch_size, seq_len, hidden_size];attention_mask是注意力矩阵,用于在训练时掩盖当前时刻之后的信息,形状为[batch_size, 1, query_len, key_len];position_ids是输入序列的位置编号,形状为[batch_size, seq_len]。第2行中past_key_value仅在推理时会用到,用来传入截止上一个时刻所有缓存的key_states和value_states状态,如图10-65所示;output_attentions为是否返回注意力权重默认为False,不过事实上这里也不支持返回注意力权重矩阵,因为模型中使用到的两种注意力计算函数返回结果都不包含注意力权重矩阵;use_cache表示是否使用Key-Value缓存机制,在整个Baichuan2模型中默认使用。第3~8行是根据解码层对应的输入整体计算得到3个线性变换后的结果,然后再分别得到query_states、key_states和value_states,且形状均为[batch_size, num_heads, seq_len, head_dim]。第10~11是计算得到使用Key-Value缓存机制时,拼接后key_states的序列长度。第12~14行是旋转编码的前向传播计算过程。第15~18行则是使用缓存机制时将历史状态和当前状态拼接的过程,并且同时将拼接后的结果继续缓存以在下一个时刻解码时进行使用。第19~23行则是计算得到多头注意力的输出结果,线性变换后attn_output的形状为 [batch_size, seq_len, hidden_size]。第24~6行是返回最后计算得到的结果。
2. 门控感知机实现
根据图10-62可知,基于门控单元的多层感知机类似于通过一个遗忘门来对输入信息进行筛选过滤,具体地其实现过程如下所示:
1 class MLP(nn.Module):
2 def __init__(self, hidden_size, intermediate_size, hidden_act):
3 super().__init__()
4 self.gate_proj = nn.Linear(hidden_size, intermediate_size)
5 self.down_proj = nn.Linear(intermediate_size, hidden_size)
6 self.up_proj = nn.Linear(hidden_size, intermediate_size)
7 self.act_fn = ACT2FN[hidden_act]
8
9 def forward(self, x):
10 f_gate = self.act_fn(self.gate_proj(x))
11 return self.down_proj(f_gate * self.up_proj(x))在上述代码中,第2行intermediate_size是多层感知机中间层对应的维度,Baichuan2-7B中为11008;hidden_act表示指定遗忘门中所使用的激活函数。第4~6行便是实例化3个线性变换类对象。第7行是实化遗忘门所使用的激活函数,Baichuan2中默认使用的是$\text{silu}$激活函数,如式(10-17)所示。
第10~11行是分别计算得到遗忘门和返回多层感知机的输出,形状同hidden_size一致,为[batch_size, seq_len, hidden_size]。