10.11 BERT命名体识别模型#
在前面几节内容中我们陆续介绍了3种基于BERT预训练模型的下游任务,包括文本分类、问题选择和问题回答模型。在本节内容中,我们将会介绍最后一个基于BERT预训练模型的下游任务,命名体识别(Named Entity Recognition, NER)。所谓命名体指的是输入模型一句文本,最后需要模型将其中的实体,例如人名、地名、组织等标记出来。
例如:
1 句子:涂伊说,如果有机会他想去黄州赤壁看一看!
2 标签:['B-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'I-LOC',
'B-LOC', 'I-LOC', 'O', 'O', 'O', 'O']
3 实体:涂伊(人名)、黄州(地名)、赤壁(地名)在10.9节内容中我们提到,通常来讲几乎对于所有NLP任务来说最后所要完成的本质上都是一个分类任务,因此在NER任务中也不例外。根据上面给出的标签来看,对于原始句子中的每个字符来说其都有一个对应的类别标签,因此对于NER 任务来说只需对原始句子里每个字符进行分类,然后再将预测后的结果进行后处理便能够得到句子中存在的相应实体。这种对BERT最后一层每个字符进行分类的做法也类似于在上一节中介绍到的问题回答任务。
10.11.1 任务构造原理#
正如上面所说,对于命名体识别这个任务场景来说其本质上依旧可以归结为分类任务,只是关键在于如何构建这个任务以及整个数据集。对于这个任务场景来说,模型的整体原理如图10-37所示。
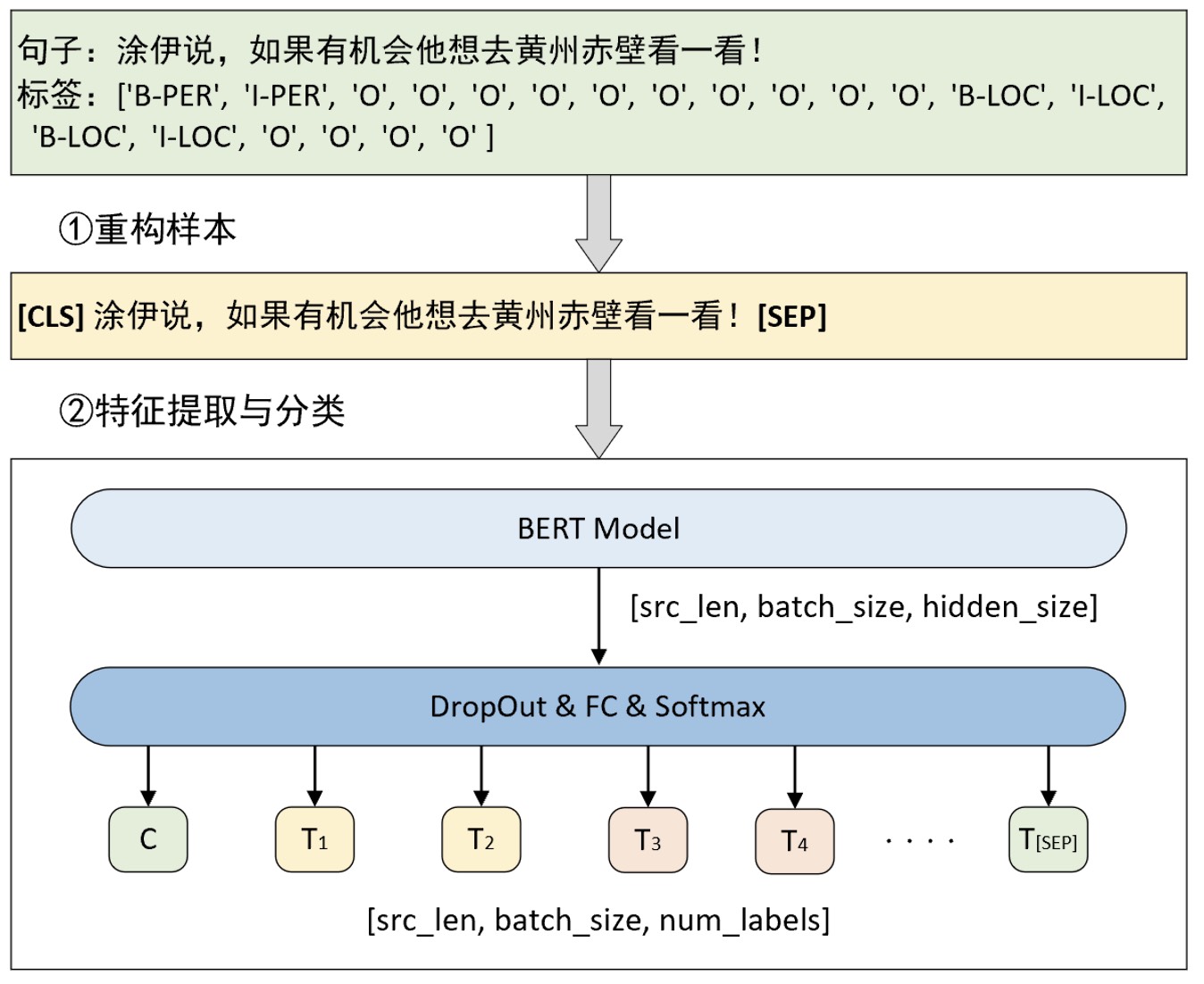
如图10-37所示便是一个基于BERT预训练模型的NER任务原理图。从图中可以看出原始输入为一个单句,我们只需要在句子的首尾分别加上[CLS]和[SEP],然后将其输入到模型当中进行特征提取并最终通过一个分类层对输出的每个向量进行分类即可。在推理过程中,只需要对每个位置的预测结果进行后处理便能够实现整个NER任务。
到此,对于问答选择整个模型的原理就介绍完了,下面首先来看如何构造数据集。
10.11.2 数据预处理#
1. 语料介绍
在这里,我们使用到的是一个中文命名体识别数据集[1],如下所示便是原始数据的存储形式:
1 涂 B-PER
2 伊 I-PER
3 说 O
4 ...
5 黄 B-LOC
6 州 I-LOC
7 赤 B-LOC
8 壁 I-LOC 其中每一行包含一个字符和其所属类别,B-表示该类实体的开始标 志,I-表示该类实体的延续标志。例如对于第5~8行来说分别对应了“黄州”和 “赤壁”这两个实体。同时,对于该数据集来说,其一共包含有3类实体(人名、地名和组织),因此其对应的分类总数便为7,如下所示:
1 {'O': 0, 'B-ORG': 1,'B-LOC': 2,'B-PER': 3,'I-ORG': 4, 'I-LOC': 5, 'I-PER': 6}进一步,我们便可以根据需要来构造模型训练时的数据集。
2. 数据集构造
在数据集构造部分同样包含载入原始数据、重构样本、样本填充构造迭代器等过程。由于这些内容我们在前面几节内容中已经多次提及,所以这里我们只对其中的关键部分进行介绍。同样,整体上我们依旧可以继承文本分类处理中的LoadSingleSentenceClassificationDataset类,然后再稍微修改其中的部分方法。
首先是在data_process()函数中定义如何完成原始样本的构建过程, 示例代码如下所示:
1 def data_process(self, file_path):
2 raw_iter = open(file_path, encoding="utf8").readlines()
3 data, max_len, tmp_token_ids = [], 0, []
4 tmp_sentence,tmp_label, tmp_entity = "", [], []
5 for raw in tqdm(raw_iter, ncols=80):
6 line = raw.rstrip("\n").split(self.split_sep)
7 if len(line) == 1:
8 if len(tmp_token_ids) > self.max_position_embeddings - 2:
9 tmp_token_ids = tmp_token_ids[:self.max_position_embeddings - 2]
10 tmp_label = tmp_label[:self.max_position_embeddings - 2]
11 max_len = max(max_len, len(tmp_label) + 2)
12 token_ids = torch.tensor([self.CLS_IDX] + tmp_token_ids +
13 [self.SEP_IDX], dtype=torch.long)
14 labels = torch.tensor([self.IGNORE_IDX] + tmp_label +
15 [self.IGNORE_IDX], dtype=torch.long)
16 data.append([tmp_sentence, token_ids, labels])
17 assert len(tmp_token_ids) == len(tmp_label)
18 tmp_token_ids,tmp_sentence = [], ""
19 tmp_label,tmp_entity = [], []
20 continue
21 tmp_sentence += line[0]
22 tmp_token_ids.append(self.vocab[line[0]])
23 tmp_label.append(self.entities[line[-1]])
24 tmp_entity.append(line[-1])
25 return data, max_len在上述代码中,第2行是一次性读取原始数据中的所有行。第3行分别用于保存预处理结束后的数据、所有样本中的最大长度和每个样本索引。第4行分别用于保存每个原始样本、对应的标签类别和原始标签值,主要用于观察预处理时的中间结果。第5行开始遍历原始数据中的每一行。第7行表示已经将上一个样本处理完毕。第7~10行是判断长度是否超过最大长度。第11行用来记录所有句子的最大长度。第12~15行是用来构造模型输入和正确标签。第21~24行分别是对当前样本中的每个字符进行相应的处理。
最后,经过data_process()方法处理后便会得到类似如下所示结果:
1 句子: 涂伊说,如果有机会他想去黄州赤壁看一看!
2 实体: ['B-PER', 'I-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O',
3 'B-LOC', 'I-LOC', 'B-LOC', 'I-LOC', 'O', 'O', 'O', 'O']
4 input_ids: [101, 3864, 823, 6432, 8024, 1963, 3362, 3300, 3322, 833, 800,
5 2682, 1343, 7942, 2336, 6619, 1880, 4692, 671, 4692, 8013, 102]
6 label: [-100, 3, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 5, 2, 5, 0, 0, 0, 0, -100]进一步,我们只需要再完成填充处理便能够完成数据集的构建过程,这部分实现各位读者直接阅读源码即可。
10.11.3 命名体识别#
1. 前向传播
正如本节内容一开始所介绍的,我们只需要在原始BERT模型的基础上再加一个对所有位置向量进行分类的分类层即可,因此这部分代码相对来说也比较容易理解。首先在DownstreamTasks目录下新建一个BertForTokenClassification.py模块,并完成整个模型的初始化和前向传播过程,示例代码如下所示:
1 class BertForTokenClassification(nn.Module):
2 def __init__(self, config, bert_model_dir=None):
3 super(BertForTokenClassification, self).__init__()
4 self.num_labels = config.num_labels
5 if bert_model_dir is not None:
6 self.bert = BertModel.from_pretrained(config, bert_model_dir)
7 else:
8 self.bert = BertModel(config)
9 self.dropout = nn.Dropout(config.hidden_dropout_prob)
10 self.classifier = nn.Linear(config.hidden_size, self.num_labels)
11 self.config = config在上述代码中,第5~8行用于根据不同条件来实例化一个BERT模型。第9~11行则是完成命名体识别的分类任务。
进一步,模型的前向传播过程示例代码如下所示:
1 def forward(self, input_ids=None, attention_mask=None,
2 token_type_ids=None,position_ids=None, labels=None):
3 _, all_encoder_outputs = self.bert(input_ids,
4 attention_mask, token_type_ids, position_ids)
5 sequence_output = all_encoder_outputs[-1]
6 sequence_output = self.dropout(sequence_output)
7 logits = self.classifier(sequence_output)
8 if labels is not None:
9 loss_fct = nn.CrossEntropyLoss(ignore_index=self.config.ignore_idx)
10 loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
11 return loss, logits
12 else:
13 return logits在上述代码中,第1~2行是模型的输入部分,其中input_ids和labels的形状均为[src_len,batch_size]。第3~4行是返回BERT模型的输出结果,并取最后一层的输出形状为[src_len, batch_size, hidden_size]。第7行则是进行分类处理,输出结果形状为[src_len, batch_size, num_labels]。第8~13行是根据条件返回相应的结果,这里值得注意的是需要指定ignore_index。
2. 模型训练
在完成上述所有准备之后便可以来实现模型的训练部分,核心示例代码如下所示:
1 def train(config):
2 model = BertForTokenClassification(config, config.pretrained_model_dir)
3 data_loader = LoadChineseNERDataset(...)
4 train_iter, test_iter, val_iter = \
5 data_loader.load_train_val_test_data(config.train_file_path,
6 config.val_file_path, config.test_file_path, only_test=False)
7 optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
8 for epoch in range(config.epochs):
9 for idx, (sen, token_ids, labels) in enumerate(train_iter):
10 padding_mask = (token_ids == data_loader.PAD_IDX).transpose(0, 1)
11 loss, logits = model(token_ids, padding_mask, None, None, labels)
12 optimizer.step()
13 acc, _, _ = accuracy(logits, labels, config.ignore_idx)
14 if idx % 20 == 0:
15 logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "
16 f"Train loss :{loss.item():.3f}, Train acc: {round(acc, 5)}")
17 show_result(sen[:10], logits[:, :10], token_ids[:, :10], config.entities)在上述代码中,第2行用来实例化一个命名体识别模型对象。第3~6行是返回得到对应的训练集、验证 集和测试集。第7行是实例化一个优化器。第8~12行是整个模型的迭代训练过程。第13行是计算模型在训练集上的准确率。第14~17行是打印训练时的相关信息,其中第17行是在训练时展示模型预测的结果。
上述代码在训练过程中将会输出类似如下所示结果:
1 Epoch: [1/10], Batch[620/1739], Train Loss: 0.115, Train acc: 0.963
2 Epoch: [1/10], Batch[240/1739], Train Loss: 0.098, Train acc: 0.964
3 Epoch: [1/10], Batch[660/1739], Train Loss: 0.087, Train acc: 0.964
4 ......
5 句子: 在澳大利亚等西方国家改变反倾销政策中对中国的划分后,不少欧盟人士也认识到,
6 此种划分已背离中国经济迅速发展的现实。
7 澳大利亚: LOC
8 中国: LOC
9 欧盟: LOC
10 中国: LOC到此,对于基于BERT预训练模型的命名体识别任务就介绍完了,关于模型推理部分的实现各位读者可以直接参考源码。
10.11.4 小结#
在本节内容中,我们首先介绍了命名体识别模型的背景以及整个任务的构建原理;然后详细介绍了命名体识别任务数据预处理的构建流程;最后一步一步介绍了如何基于BERT预训练模型来实现命名体识别模型的构建。在下一节内容中,我们将会开始介绍如何从零实现基于NSP和MLM任务的BERT预训练过程。