11.10 基于密度的聚类算法#
在前面几节内容中,我们陆续介绍了3种常见聚类算法的原理与实现过程,包括原始的Kmeans聚类算法、Kmeans++聚类算法以及基于特征权重的加权Kmeans聚类算法 ,并且这3种都算是基于Kmeans框架下的聚类算法,也就是说它们本质上解决的都是一类数据的聚类问题。在本节内容中,我们将开始介绍一种新的聚类算法,即基于密度的聚类算法,其学习路线如图11-23所示。
11.10.1 DBSCAN算法思想#
由于在实际场景中我们遇到的不仅仅只有图11-2所示簇结构的数据集,还可能存在一些其它簇结构形式的数据,例如图11-24所示的结构类型。
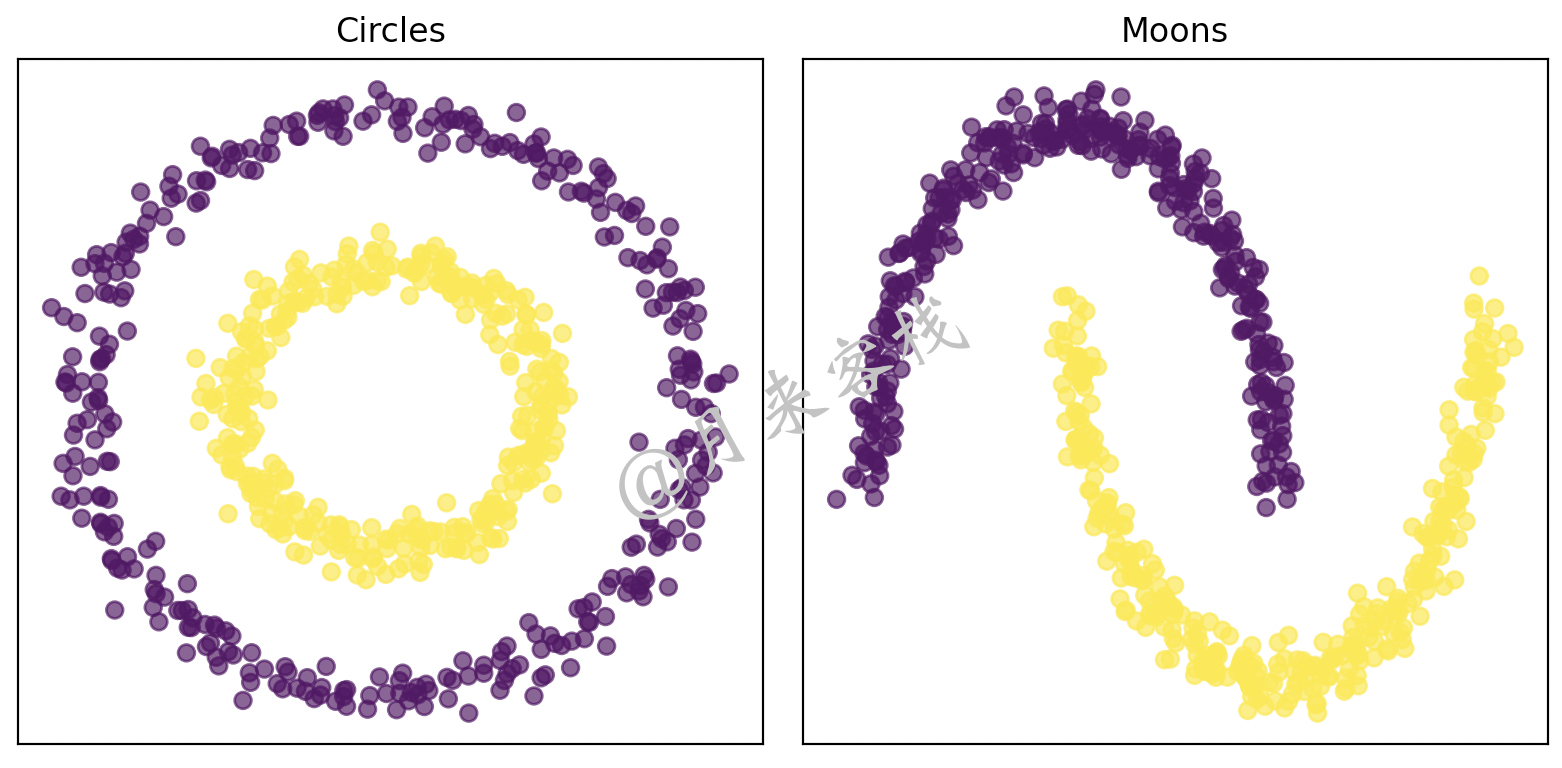
如图11-24所示,对于这两种异形的数据集来说,不管是采用前面介绍的3种聚类算法中的哪一种,最后得到的结果都会很差,因为类Kmeans聚类算法都不适合对这种数据进行聚类处理,并且如果一定要用类Kmeans聚类算法来进行聚类,那么将会得到如图11-25所示的结果。
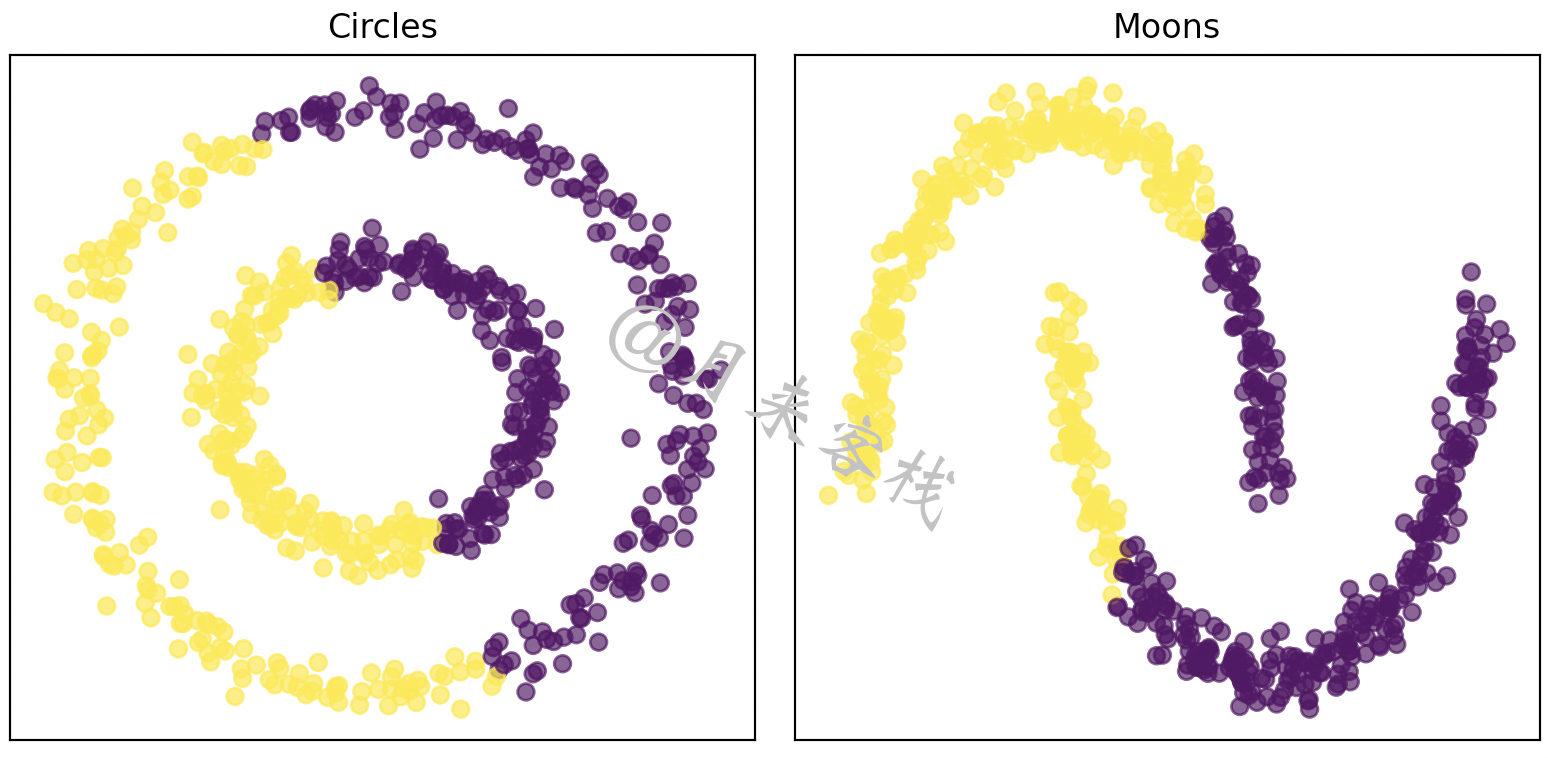
如图11-25所示,左右两边均是采用Kmeans++算法聚类后的结果,其中不同颜色表示聚类算法给出的聚类结果,可以看到由于类Kmeans聚类算法的特性,其在这类数据集上的表现并不好。对于图11-25所示这样结构的数据,一种更好的办法是基于密度来进行聚类。
基于密度的聚类算法(Density Based Spatial Clustering of Applications with Noise, DBSCAN),1996年由Martin Ester等人提出[1] [2],它的核心思想是根据样本之间的密度(紧凑程度)来对样本进行聚类处理。例如对于图11-25中所示的两种异形数据来说,两种类别之间有着明显空白之处(密度小),而对于各类别内部的样本来说样本之间分布却非常紧凑(密度大),因此只需要将所有各自相互紧邻的样本点划分为不同的簇结构即可完成整个聚类过程。可以发现,基于这样的聚类思想不管待聚类的数据集是什么样的分布形式,都可以很好的对其进行聚类处理。同时,从算法的全称可以看出,DBSCAN算法的原理除了是基于密度这一特性外,它还能有效地发掘数据中的异常样本,即那些密度低且相对孤立的样本点。
11.10.2 DBSCAN示例代码#
在介绍完DBSCAN算法的思想以后,我们再来看如何借助sklearn来完成整个建模过程,完整示例代码可参见 AllBooKCode/Chapter11/C17_dbscan_train.py 文件。具体地,先构造类似图11-25所示的数据集,然后使用sklearn中的DBSCAN模块来完成整个聚类过程,示例代码如下:
1 from sklearn.cluster import DBSCAN
2 from sklearn.datasets import make_moons
3
4 if __name__ == '__main__':
5 X, y = make_moons(n_samples=700, noise=0.05, random_state=2020)
6 X = StandardScaler().fit_transform(X)
7 db = DBSCAN(eps=0.3, min_samples=10)
8 db.fit(X)
9 print(f"调整兰德系数为: {adjusted_rand_score(y, db.labels_)}")在上述代码中,第1行是导入基于密度的聚类模块。第2行是导入一个函数,并通过第5行所示的方式来构造形如图11-25右边所示数据集。第6行是对数据样本进行标准化处理。第7行是利用DDBSCAN聚类算法对样本进行聚类处理,其中eps和min_samples表示用于构建核心样本的两个关键参数,eps越大且min_samples越小则最终得到的簇结构将会偏少,反之则得到簇结构将会偏多,详细原理见下文。第8~9行则是对于样本进行聚类处理,并通过调整兰德系数来对聚类结果进行评估。
11.10.3 DBSCAN算法核心概念#
在正式介绍DBSCAN算法的原理之前,先来介绍算法中几个非常重要的核心概念,核心样本、直接可达、可达和异常样本。同时,在DBSCAN算法中还有两个非常关键的超参数,半径$r$和最小样本数$\text{minPts}$,如图11-26所示。
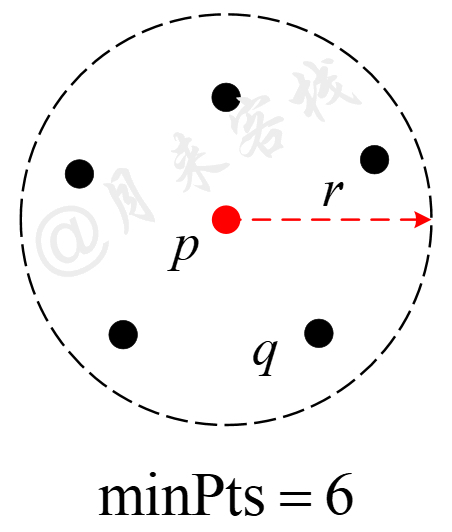
1)核心样本(Core Point):以样本点$p$为圆心$r$为半径作圆,如果圆域内至少存在$\text{minPts}$个样本(包括$p$自身),则称$p$为核心样本,否则称为非核心样本(Non-core Point)。
2)直接可达(Directly Reachable ):以核心样本$p$为圆心$r$为半径,圆域内的所有样本点对于$p$来说直接可达。
如图11-26所示,以样本点$p$为圆心$r$为半径作圆,圆域内恰好存在$\text{minPts}=6$个样本,则此时称$p$为核心样本,称$q$称为非核心样本。同时,称圆域内的所有样本对于核心样本$p$来说直接可达。值得注意的一点是,直接可达是针对核心样本而言,例如图11-26中样本$q$对于$p$来说直接可达,但不能说成样本$p$对于$q$来说直接可达。
3)可达(Reachable):如果存在样本点 $p_1,p_2,...,p_n$,且 $p=p_1,q=p_n$,$p_{i+1}$对于$p_i$来说直接可达,那么称$q$对于$p$来说可达。注意,这里暗含着$p_1,...,p_{n-1}$均为核心样本。
4)异常点(Outliers):如果样本点$O$对于其它任何样本点来说均不直接可达,则称样本点$O$为异常点。
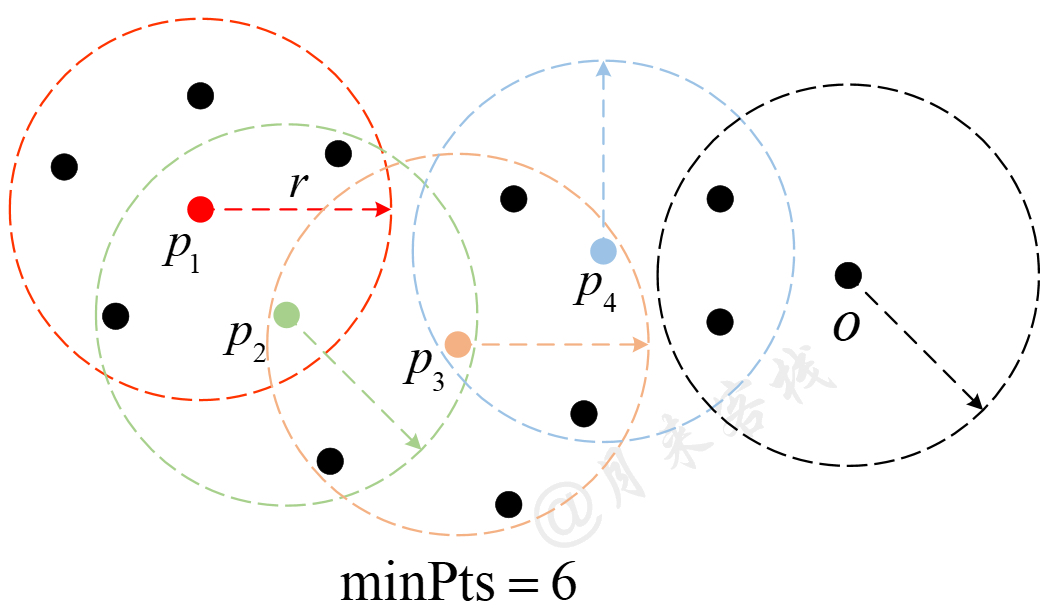
如图11-27所示,$p_1,p_2,p_3,p_4$均为核心样本,且$p_2$对于$p_1$来说直接可达,$p_3$对于$p_2$来说直接可达,$p_4$对于$p_3$来说直接可达,因此$p_4$对于$p_1$来说可达。同时,由于样本点$O$既不是核心样本,且对于其它样本来说也不直接可达,因此$O$为异常点。