10.6 BERT网络#
经过前面几节内容的介绍,我们对Transformer模型已经有了清晰地认识。不过说起Transformer模型在它发表之初并没有引起太大的反响,直到它的后继者BERT[1]模型的出现才使得大家再次回过头来仔细研究Transformer模型。在接下来的几节内容中,我们将主要从BERT模型的基本原理、模型实现、预训练模型在下游任务中的运用以及掩码任务和下句预测任务这几个方面来详细介绍BERT模型。
10.6.1 BERT动机#
虽然预训练语言模型对于很多下游处理任务的性能都有着显著的提升,但现有预训练模型的网络结构却限制了模型自身的表达能力,其中最主要的一点就是模型的单向编码。例如在传统的RNN或者是GPT[2]中,模型在建模时使用的均是从左到右(Left-to-Right)或者从右到左(Right-to-Left)的建模方式,这就使得模型在编码过程中只能够看到当前时刻之前的信息,而不能够同时捕捉到当前时刻之后的信息。

如图10-25所示,对于这句样本来说无论模型采用的是从左到右还是从右到左的编码方,模型在对词“it”进行编码时都不能有效地捕捉到其具体所指代的信息。这就类似于我们人在阅读这句话时一样,在没有看到“tired”这个词之前我们同样也无法判断“it”具体所指代的事物。例如如果我们把“tired”这个词换成“wide”,则“it”指代的就变成了“street”。所以,如果模型采用的是双向编码的方式,那么从理论上来看就能够很好的避免这个问题。
基于这样的动机,德夫林(Devlin)等人[1]于2018年10月提出了一种采用双向表示的编码器(Bidirectional Encoder Representations from Transformers, BERT)来实现模型的双向编码学习能力。整体来看BERT模型的整体结构并不复杂,它本质上就等同于Transformer中的编码器,只是模型在预训练的过程中使用了掩码语言模型(Mask Language Model, MLM)和下句预测(Next Sentence Prediction, NSP)这两项任务。下面我们首先开始介绍BERT模型的基本原理。
10.6.2 BERT结构#
BERT网络结构整体上是由多层的Transformer编码器所构建,如图10-26所示便是一个详细的BERT模型网络结构图。从图10-26可以发现其上半部分的结构与10.3节内容中介绍的Transformer编码器类似,只不过在输入层部分新加入了句子编码(Segment Embedding)。
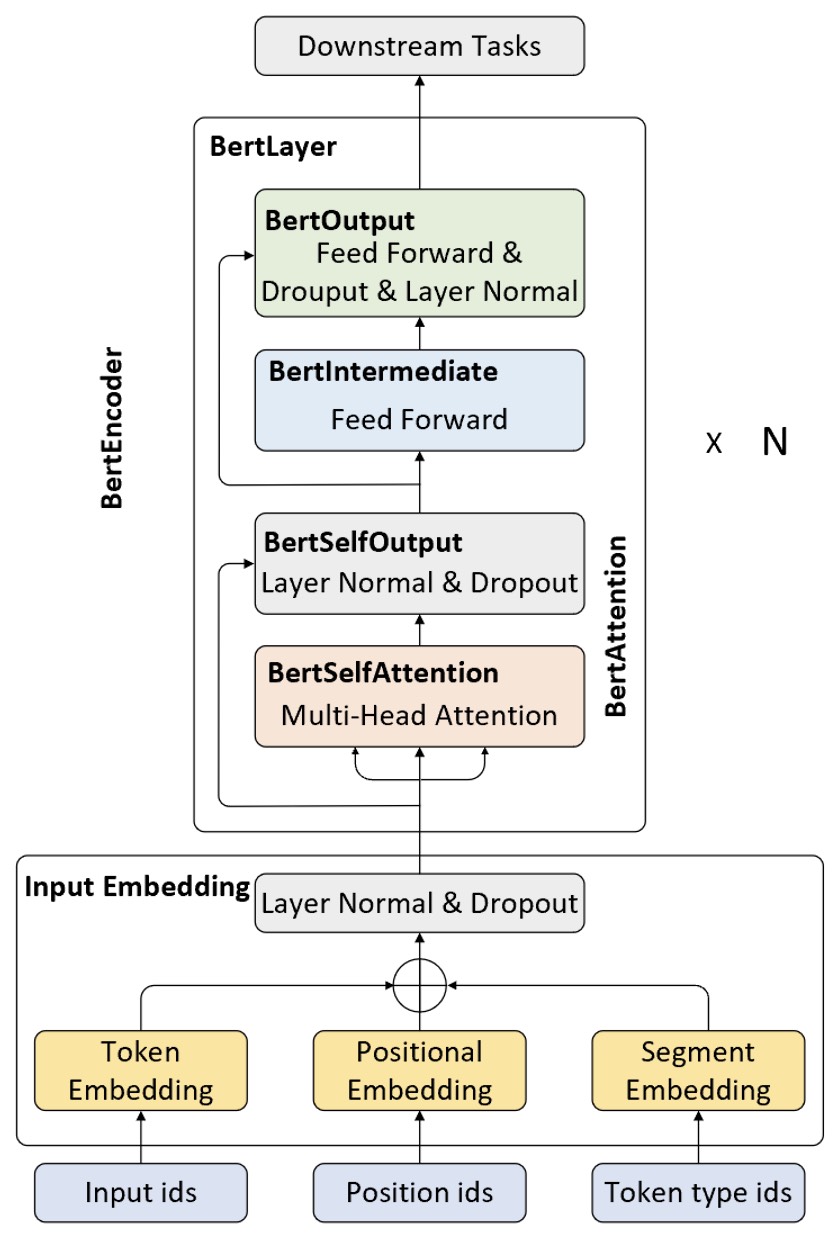
如图10-26所示,其上半部分便是BERT编码器,其整体由多个BERT编码层(即原文中指代的 Transformer Blocks)所构成。具体地,在论文中作者分别用 $L$来表示编码层的格式,即BERT编码器是由$L$ 个编码层所构成;用$H$来表示模型的维度;用$A$来表示多头注意力中多头的个数。同时,作者分别就$\text{BERT}_{\text{BASE}} (L=12,H =768,A=12)$和$\text{BERT}_{\text{BASE}} (L=24,H =1024,A=16)$这两种尺寸的BERT模型进行了实验对比。由于这部分类似的内容在10.3节内容中已经进行了详细介绍,所以这里就不再 赘述,细节之处见10.7节代码实现。
10.6.3 BERT输入层#
如图10-27所示,在BERT中输入层模块中一共包含3个部分:字符嵌入(Token Embedding)、位置编码(Positional Embedding) 和句子编码(Segment Embedding)。虽然前面两部分在10.3节内容中已经介绍过了,但这里需要注意的是BERT中的位置编码并不是采用公式计算得到,而是类似 普通的嵌入层一样为每一个位置初始化了一个向量然后随着网络一起训练得到。
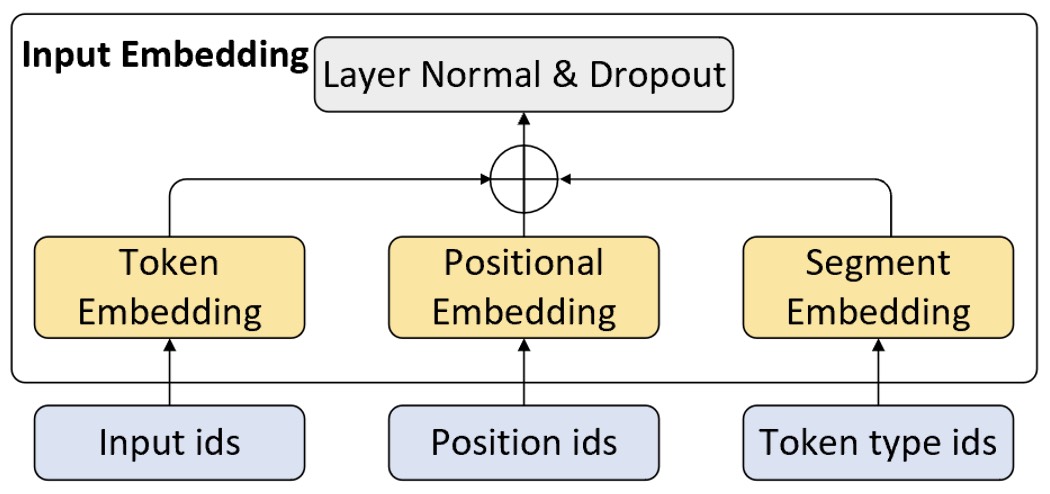
同时,最值得注意的一点是BERT开源的预训练模型最大只支持 512个字符的长度,这是因为模型在训练过程中位置编码的词表的最大长度只有512。
除此之外,第三部分则是BERT模型中所引入的句子编码。由于BERT模型的主要目的是构建一个通用的预训练模型,因此难免需要兼顾到各种NLP 任务场景下的输入。因此句子编码的作用便是用来区分输入序列中的不同部分,其本质是通过一个普通的嵌入层来区分每一个序列所处的位置。例如在下句预测任务中,对于任意一个输入样本来说均由两个句子构成,而句子编码的作用就是对每个字符进行位置标识,以此来区分哪些字符属于第1个句子哪些字符属于第2个句子,因此也可以看出同一个句子中的编码是一样的。最后,再将这三部分的结果相加并标准化便得到了BERT模型的输入。
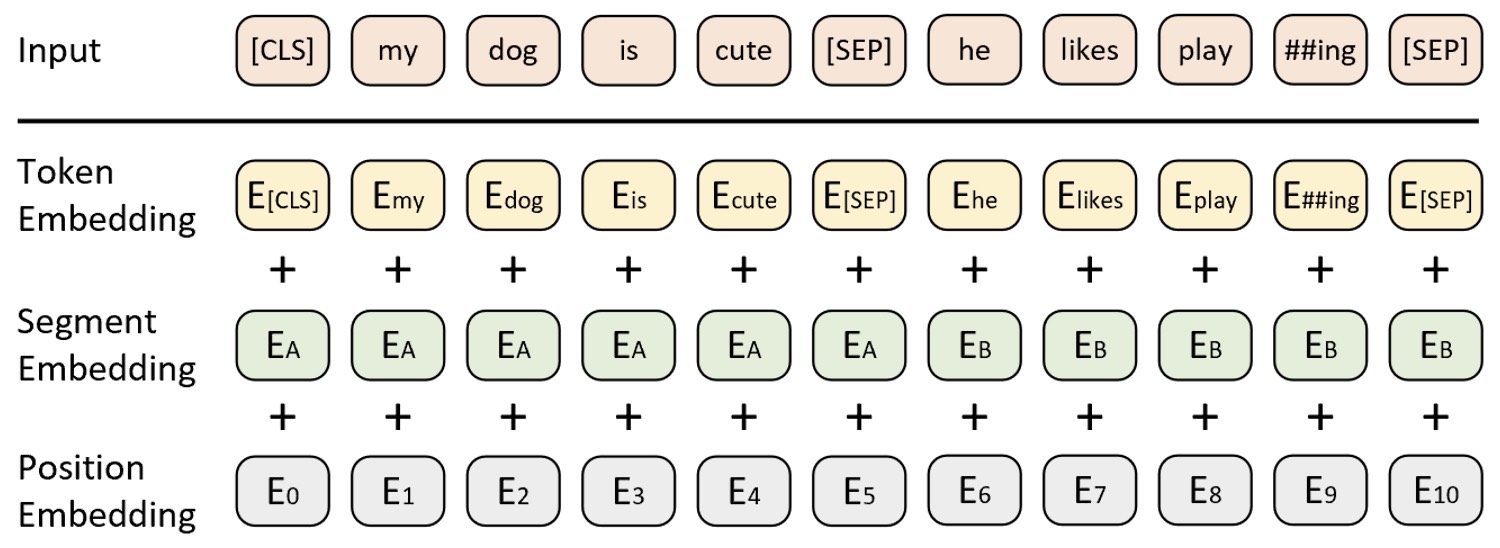
如图10-28所示,最上面的Input表示原始的输入序列,其中第1个字符[CLS]是一个特殊的分类标志,如果下游任务是做文本分类的话,那么在 BERT 的输出结果中可以只取[CLS]对应的向量进行分类(不过实验表明,取所有位置向量的均值往往有着更好的效果);而其中的[SEP]字符则是用来作为将两句话分开的标志。句子编码则同样是用来区分两句话所在的不同位置,对于每句话来说其内部各自的位置向量都是一样的,当然如果原始输入只有一句话,那么句子编码层中对应的每个字符的位置向量均相同。最后,位置编码则是用来标识句子中每个字符各自所在的位置,使得模型能够捕捉到文本“有序”这一特性,具体细节之处可见10.7节代码实现。
10.6.4 预训练任务#
为了能够更好训练BERT模型,论文引入了MLM和NSP这两个预训练任务来训练网络。对于MLM任务来说,它的做法是随机掩盖掉输入序列中$15\%$的字符,即用[MASK]替换掉原有的字符,然后在BERT的输出结果中取对应掩盖位置上的向量进行真实值预测。不过由于模型在后续的微调(Fine-tuning)过程中输入序列并不存在 [MASK]这样的字符,因此这将导致模型的预训练和微调之间存在不匹配的问题。为了解决这一问题,可以将原始MLM做相应调整,即先选定15%的字符,然后将其中的80%替换为[MASK]符号、10%随机替换为其它符号、剩下的10%保持不变。最后取这15% 的字符对应的输出来做分类来预测其真实值。
对于NSP任务来说,它的做法是在每个有AB两个句子构造的样本中,其中50%的情况下B确实为A上下文的下一句话,此时标签为IsNext;另外50%的情况下B为语料中其它的随机句子, 此时标签为NotNext然;最后模型取[CLS]位置上对应的向量来预测B是否为A的下一句话。这样做的目的便是因为在很多下游任务需要依赖于分析两句话之间的关系来进行建模,例如文本蕴含、问题选择等任务场景。
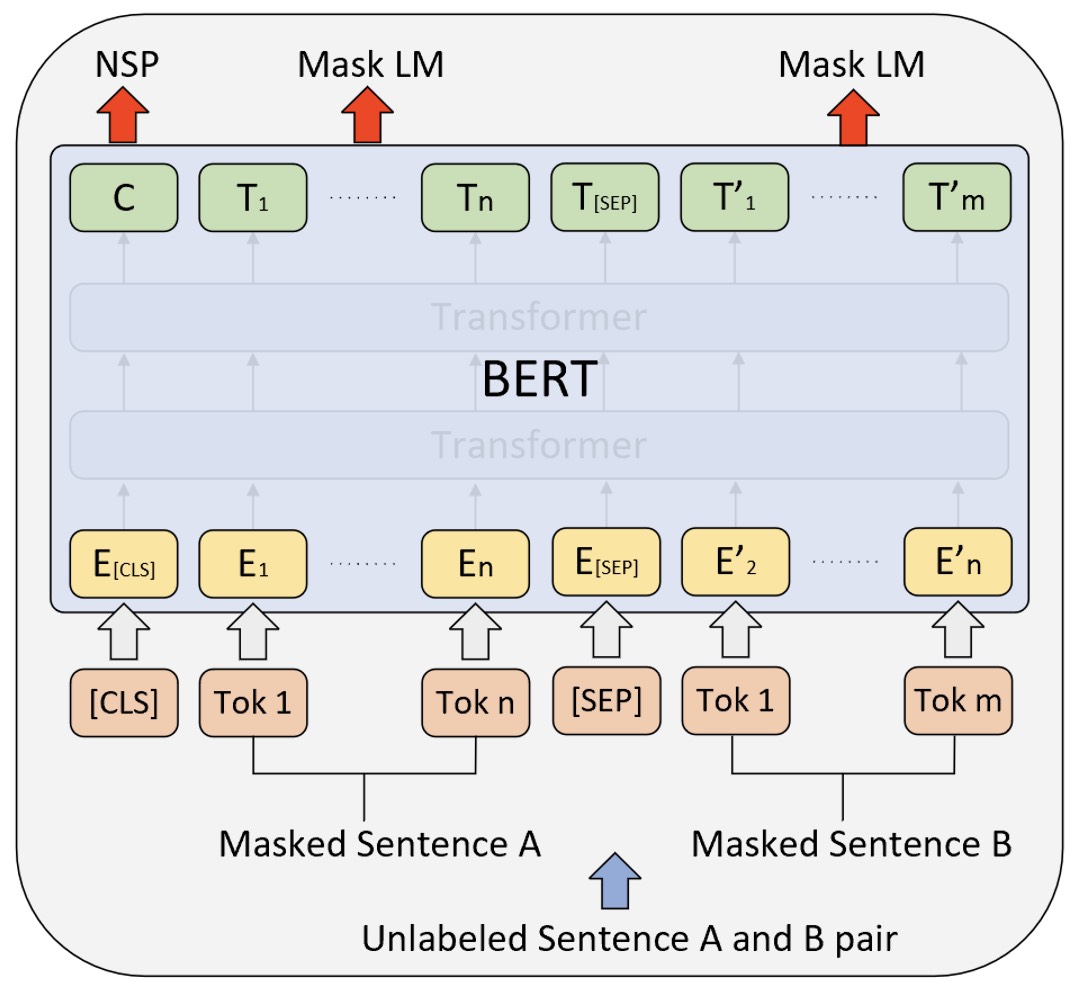
如图10-29所示便是MLM和NSP这两个预训练任务在BERT预训练时的输入输出示意图。在图10-29中,最上层输出的C在训练时用于NSP的分类任务,其它位置上的$T_i$和$T^{\prime}_j$等则用于预测被掩盖掉的字符。
到此,对于BERT模型的原理以及NS和MLM这两个任务的内容就介绍完 了。整体来看,如果单从网络结构上看BERT并没有太大的创新,仅仅只是相当于Transformer中的编码器,并且所谓的”双向“指的也就是其中的自注意力机制。
10.6.5 小结#
在本节内容中,我们首先介绍了BERT模型所提出的动机以及传统语言模型的弊端;然后介绍了BERT模型的基本原理,包括网络结构和输入层的构造;最后详细介绍了用于对BERT进行预训练的MLM和NSP任务。在下节内容中,我们将开始介绍如何基于先前实现的多头注意力机制来实现整个BERT模型。
引用#
[1] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint, 2018, arXiv:1810.04805.
[2] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.