第 3 章 文档标准化与语义检索#
RAG 的核心思想是在大模型生成答案之前,先从外部知识库中检索与当前问题最相关的内容,再将检索结果作为上下文提供给模型。要实现这一过程,首先需要将原始文档整理为可被程序统一处理、切分、向量化和检索的标准化数据。
本章将围绕文档标准化与语义检索的构建过程展开介绍。本节首先介绍文档在进入 RAG 系统之前所需经历的预处理流程,以及如何借助 LangChain 完成不同类型文档的加载与标准化。
3.1 文档加载与标准化#
3.1.1 语义检索的基本构建流程#
从工程实现角度看,一个基础语义检索系统的构建过程通常可以分为 4 个步骤:① 文档加载;② 文本切分;③ 向量化表示;④ 存储与检索。其整体流程如图 3-1 所示。
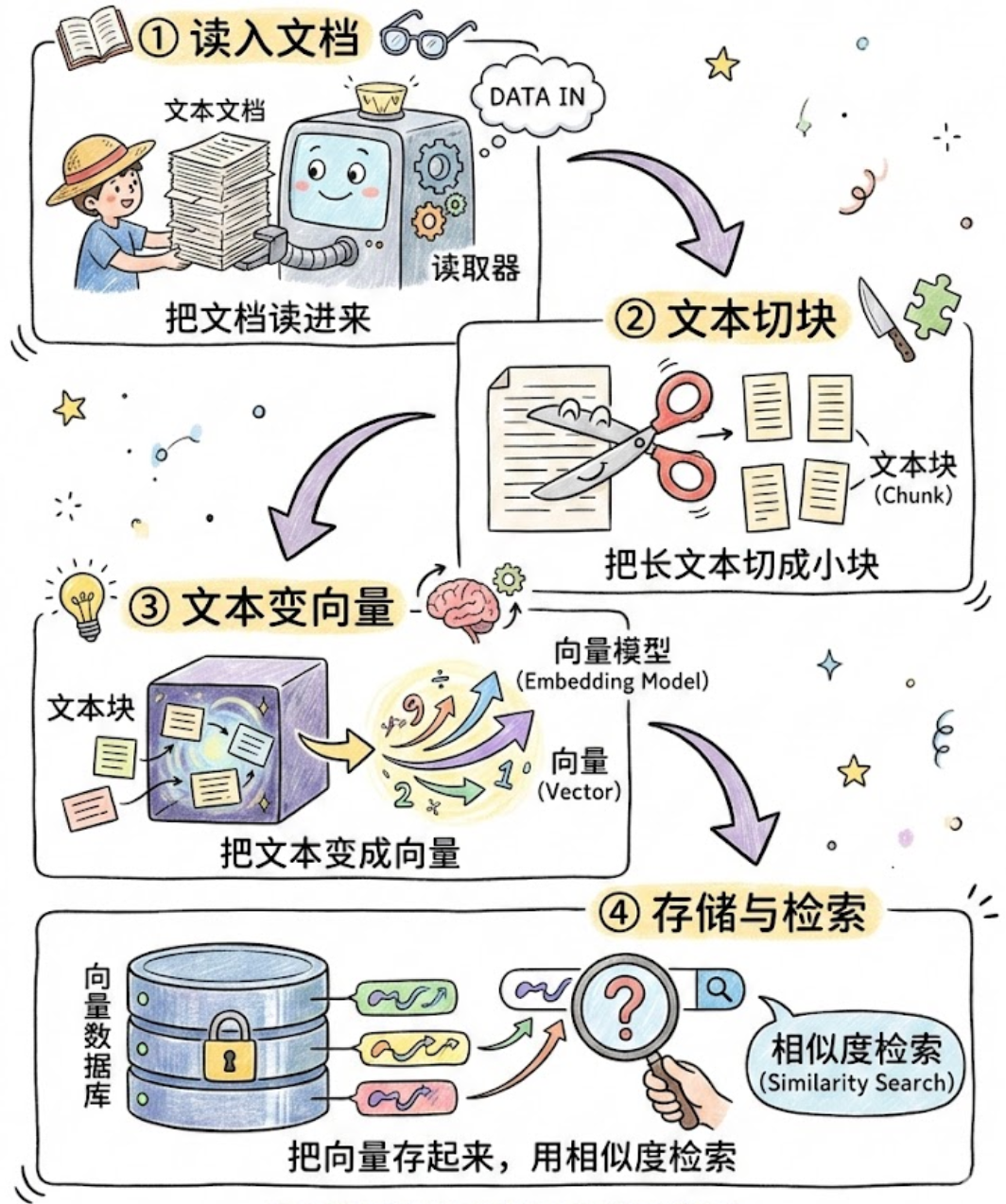
由图3-1可以看出,这 4 个步骤虽然在概念上相对清晰,但在实际实现中都包含了大量细节,其中,文档加载与文本切分尤其关键,因为原始资料的来源往往并不统一,既可能是 PDF、TXT、HTML,也可能是 Word、CSV 或数据库导出文件。如果不能先将这些异构数据统一转换为标准结构,后续的切分、向量化和检索流程就难以稳定开展。
因此,在进入文本切分策略之前,首先需要解决的问题并不是如何切块,而是如何让不同来源、不同格式的原始文档,以统一的数据结构进入后续处理流程。这正是文档加载与标准化的核心任务。
3.1.2 LangChain 中的标准化文档对象#
为了统一后续处理流程,LangChain 在文档加载阶段引入了 Document 对象。无论文档原始格式如何,只要经过加载器处理,最终都可以被转换为统一的 Document 实例列表。
一个 Document 对象通常包含以下 3 个核心字段:
page_content:文档正文内容;metadata:元数据,例如文件来源、页码、章节信息等;id:可选标识,用于在特定场景中标记文档对象。
这种设计的意义在于,后续的文本切分器、向量化模型、向量数据库以及检索器,并不需要关心输入最初是 PDF 还是 HTML,而只需要面向统一的 Document 结构进行处理。换言之,文档标准化完成之后,后续流程面对的将不再是“文件”,而是一组具备统一接口的文本对象。
例如,在加载 PDF 文件时,LangChain 通常会自动完成如下处理:
① 将 PDF 的每一页转换为一个 Document 对象;
② 将页码、来源文件等信息写入 metadata;
③ 以列表形式返回全部页面,供后续切分和向量化流程继续使用。
理解 Document 对象的意义非常重要,因为它构成了文档加载与后续处理环节之间的接口边界。只要能够将任意来源的数据转换为 Document 列表,原则上就可以接入 LangChain 的后续能力。
3.1.3 常见文档类型的加载方式#
在实际项目中,最常见的原始知识载体通常包括 PDF、纯文本文件和 HTML 页面。LangChain 已经为这些常见场景提供了对应的加载器,开发者通常只需要完成依赖安装与路径指定,即可获得标准化后的 Document 列表。
首先,需要安装本节示例所需的基础模块:
pip install langchain_community langchain_core(1) PDF 文件加载
对于 PDF 文件,可以使用 PyPDFLoader 完成加载。示例代码如下:
1 from langchain_community.document_loaders import PyPDFLoader
2
3 def load_pdf_file(file_path=None):
4 loader = PyPDFLoader(file_path)
5 docs = loader.load() # 返回由多个 Document 对象组成的列表
6 print(len(docs)) # 每个 Document 对象通常对应 PDF 的一页
7 print(docs[0].page_content) # 输出第一页的文本内容
8 print(docs[0].metadata) # 输出元数据
9 return docs在上述代码中,第 4 行通过文件路径实例化 PyPDFLoader,第 5 行调用 load() 方法完成文档解析,最终返回一个由多个 Document 对象组成的列表。
下面以一个共 3 页的 PDF 文件为例,运行上述代码后,输出结果可能类似如下形式:
3
前言 作为《跟我一起学机器学习》的姊妹篇,两年之后《跟我一起学深度学习》一书也终于出版了。 北宋大家张载有言:“为天地立心, 为生民立命, 为往圣继绝学,为万世开太平”,这两部编著虽然没有这样的...
{'producer': 'macOS 版本15.5(版号24F74) Quartz PDFContext', 'creator': 'PyPDF', 'creationdate': "D:20260213071757Z00'00'", 'moddate': "D:20260213071757Z00'00'", 'source': '../data/DLWM.pdf', 'total_pages': 3, 'page': 0, 'page_label': '1'}从输出结果可以看出,PyPDFLoader 不仅提取了页面文本,还自动记录了来源文件、总页数、当前页码等信息。这些元数据在后续进行切分、检索结果定位以及答案溯源时都具有重要价值。
(2)TXT 与 HTML 文件加载
除 PDF 之外,纯文本文件与 HTML 页面也是知识库构建中非常常见的原始数据来源。对于这两类文件,可以分别使用 TextLoader 与 BSHTMLLoader 进行加载。示例代码如下:
1 def load_text_file(file_path=None):
2 loader = TextLoader(file_path)
3 docs = loader.load()# 通常只有 1 个 Document 对象
4 return docs
5
6 def load_html_file(file_path=None):
7 loader = BSHTMLLoader(file_path)
8 docs = loader.load()
9 return docs上述代码在执行结束以后,便会得到同样的Document 对象。与 PDF 不同,TXT 和 HTML 文件没有天然的分页结构,因此加载完成后返回的 docs 列表只包含 1 个 Document 对象。后续若需要进一步拆分为适合向量化与检索的文本片段,则通常在文本切分阶段完成。
除上述类型外,document_loaders 模块还提供了更丰富的加载能力,例如 Word 文件对应的 Docx2txtLoader、CSV 文件对应的 CSVLoader、对象存储文件对应的 S3FileLoader 等,整体支持范围如图 3-2 所示。
在工程实践中,优先使用官方提供的加载器通常能够显著降低文档预处理成本,并减少对底层文件解析逻辑的重复实现。
3.1.4 自定义加载器与文档对象构造#
尽管 LangChain 已经提供了大量现成的加载器,但在实际项目中仍然可能遇到标准加载器尚未覆盖的数据来源。例如,企业内部系统导出的专用格式文件、非标准接口返回结果,或者经过业务规则预处理后的文本内容,都可能需要开发者自行完成标准化封装。
在这种情况下,最直接的做法是手动构造 Document 对象,示例代码如下:
1 def construct_document():
2 docs = [
3 Document(page_content="这是手动构造的第一页内容",
4 metadata={"source": "可在此记录来源、章节或文件路径"}),
5 Document(page_content="这是手动构造的第二页内容",
6 metadata={"source": "custom-doc"},
7 id=3)]
8 print(len(docs)) # 2
9 print(docs[0].page_content) # 这是手动构造的第一页内容
10 print(docs[0].metadata) # {"source": "可在此记录来源、章节或文件路径"}
11 return docs从上述代码可以看出,只要将文本正文写入 page_content,并将必要的来源信息写入 metadata,就可以手动构造满足 LangChain 后续处理要求的 Document 对象列表。这种方式适合对原始数据已经完成额外清洗或转换的场景。
如果希望实现更加规范、可复用的加载逻辑,也可以参照 TextLoader 等现有实现,自定义加载器类并继承 BaseLoader,然后重写其中的 lazy_load() 方法。这样不仅能够保留统一的加载接口,也更便于在项目中复用和扩展。
本节所有完整示例代码可参见 Code/Chapter03/C01_file_loader.py 文件。
至此,我们已经完成了如何从原始文件到标准化 Document 对象转换的介绍,后续章节将在此基础上进一步介绍文本切分策略,以及如何将标准化后的文本内容转换为可检索的向量表示。