推:在循环神经网络中由于每个样本的序列长度并不相同,如果使用批归一化进行标准化那么当模型推理时只要出现样本序列长度大于训练时最长的样本序列长度时,那么归一化过程将无法进行,因为此时需要对每个时间片的输出结果进行标准化并输入到下一个时刻中。
6.4 层归一化#
在上一节内容中,我们详细介绍了批归一化的动机原理及实现过程,总体来讲批归一化的核心思想是以一个小批量数据样本为单位在对应维度上进行标准化。但也正是由于这一特性使得批量归一化会受到小批量样本数量的影响,同时,显而易见批归一化也不能直接用于循环神经网络。在这样的背景下,层归一化(Layer Normalization)[1]便应运而生了。
6.4.1 层归一化动机#
根据6.3节内容可知,批归一化需要先计算一个小批量数据中每个通道上所有样本特征图的均值和方差,然后再根据对应的公式进行标准化。可见,此时小批量样本的数量便会影响均值和方差的估计结果。同时,在循环神经网络中由于每个样本的序列长度并不相同,如果使用批归一化进行标准化那么当模型推理时只要出现样本序列长度大于训练时最长的样本序列长度时,那么归一化过程将无法进行,因为此时需要对每个时间片的输出结果进行标准化并输入到下一个时刻中。除此之外,对于训练数据来说其长度越长则对应的样本数量将会越少,如果仍旧使用批归一化这类跨样本的归一化方法那么极端情况下将会出现归一化失真的情况。
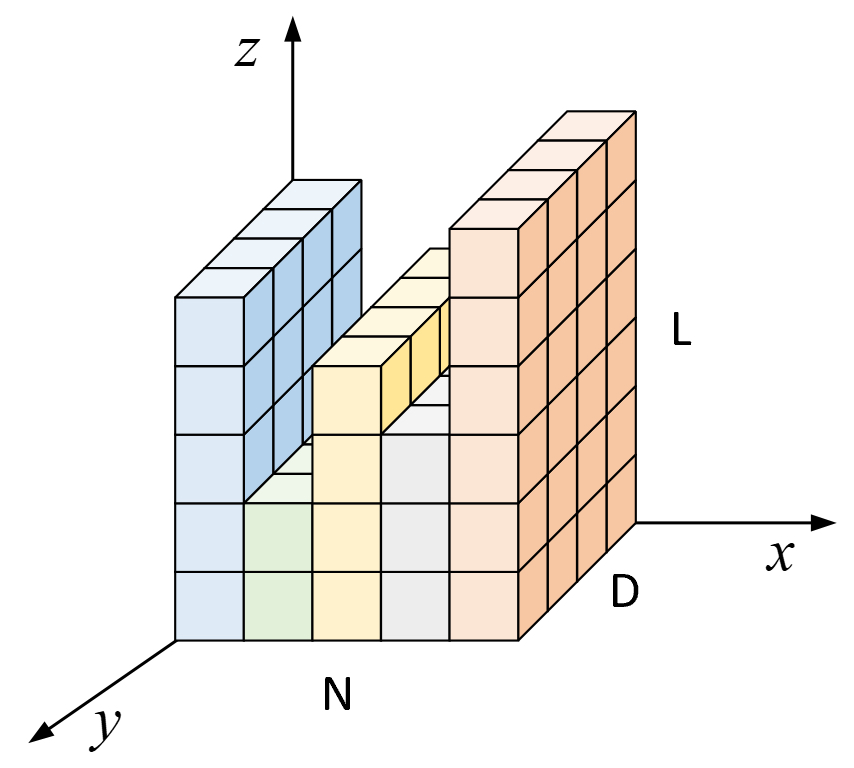
如图6-15所示为文本序列批归一化序列图,其$x$轴、$y$轴和$z$轴分别表示小批量样本数量、词向量维度和样本序列长度,即图6-15中有5个样本,从左到右其长度分别的5、2、4、3和6,且每个词的维度为4维。如果此时对于整个小批量样本同时在$z$轴这个维度上采用批归一化进行标准化,那么在对进行第3个词的位置进行标准化时第2个样本便不会参与,进一步在对第6个词的位置进行标准化时便只有第5个词参与,而这便会影响整个归一化结果。退一步来说,即便通过这样的方式进行标准化,那么当测试样本的长度大于6时,该位置便没有对应的批归一化模型参数。
由于跨样本间进行标准化会受到上述因素的影响,因此层归一化提出了以每个样本为独立单位进行标准化的思想。具体地,对于普通的前馈神经网络来说,以每个样本当前层的所有神经元为整体进行标准化;对于卷积神经网络来说,以每个样本在当前层的所有特征通道为整体进行标准化;对于循环神经网络来说,则是以每个样本在当前时刻的输出向量为整体进行标准化,即图6-15中$y$˙轴所在的维度。
6.4.2 层归一化原理#
1. 归一化原理
从归一化的计算过程来看,层归一化同批归一化的计算公式类似,即式(6-15)~式(6-18)所示先计算均值和方差,然后进行标准化,最后再进行缩放和平移,唯一的差别在于两者选择归一化的维度不同,但也有研究表明缩放和平移操作反而会对于层归一化有害 [3]。如图6-16所示便是两者在对卷积特征进行归一化时维度选择的差异之处。
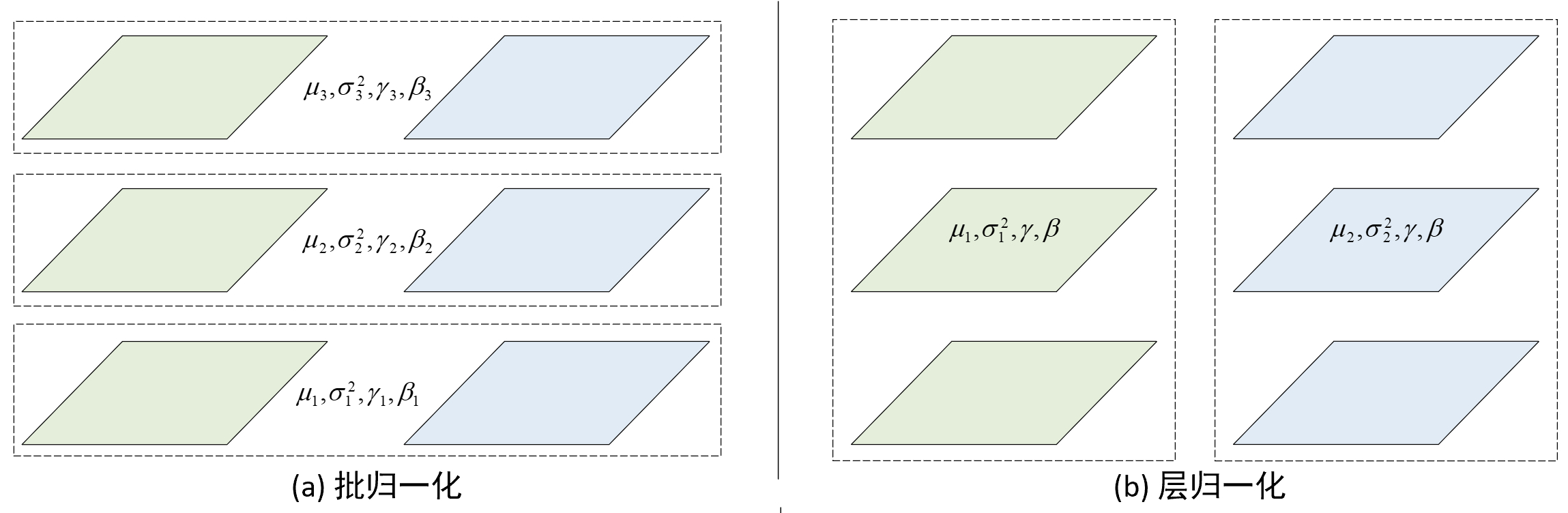
如图6-16所示,左右两边为分别是批归一化和层归一化的归一化维度示意图,其一共包含有2个样本和3个特征通道。从图6-16(a)可以看出,批归一化在进行标准化时是将所有小批量样本看成的一个整体,并逐一对每个通道进行标准化,且每个通道有各自独立的均值$\mu_i$、方差$\sigma^2_i$和权重参数$\gamma_i,\beta_i$(4个值均为标量);对于图6-16(b)中的层归一化来说,它在进行标准化时是将每个样本看做一个整体,并同时对所有通道进行标准化,且每个样本均有各自独立的均值$\mu_i$和方差$\sigma^2_i$(2个值均为标量)但共享权重参数$\gamma,\beta$(2个值均为向量,维度为$p\times q\times c$,分别表示特征图的长、宽和通道数)。
2. CNN中的归一化
下面仍旧以6.3.2节中特征图用层归一化的方式来进行计算示例。如图6-17所示左右两边分别为一个样本,且均有3个特征通道,则层归一化在进行标准化时以每个样本(图中虚线框部分)为单位进行处理,同时可知$\gamma$和$\beta$的维度均为75,即将3个通道拉伸后的总维度。
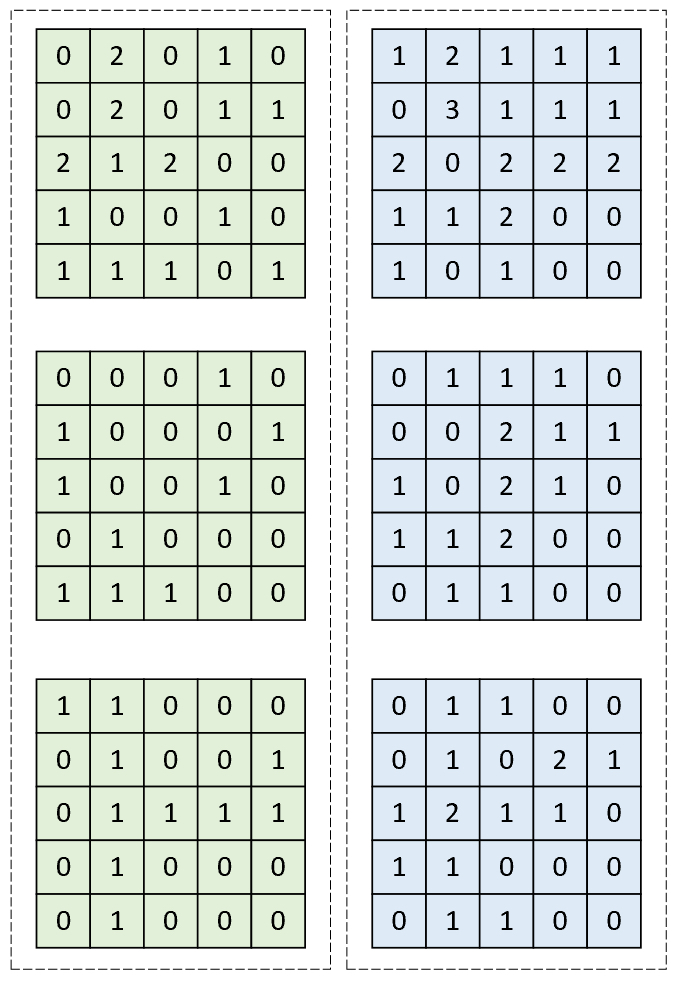
根据图6-17可知,则此时对于左右两个样本来说其均值和方差分别为
$$ \begin{aligned} \mu_1=&\frac{1}{75}(0+2+0+1+0+,...,+0+1+0+0+0)\approx0.4933\\[2ex] \sigma^2_1=&\frac{1}{75}((0-0.4933)^2+(2-0.4933)^2+,...,+(0-0.4933)^2)\approx0.3566\\[2ex] \mu_2=&\frac{1}{75}(1+2+1+1+1+,...,+0+1+1+0+0)=\approx0.7733\\[2ex] \sigma^2_2=&\frac{1}{75}((1-0.7733)^2+(2-0.7733)^2+,...,+(0-0.7733)^2)\approx0.5486\\[2ex] \end{aligned} \tag{6-23} $$进一步根据式(6-17),此时假定$\epsilon=0$,则此时对于左侧的样本点有
$$ \frac{0-0.4933}{\sqrt{0.3566+0}}\approx-0.8261,\;\;\;\;\frac{2-0.4933}{\sqrt{0.3566+0}}\approx2.5229,\;\;\;\;\frac{1-0.4933}{\sqrt{0.3566+0}}\approx0.8484\tag{6-24} $$对于右侧的样本点有
$$ \frac{1-0.7733}{\sqrt{0.5486+0}}\approx0.3060,\;\;\;\;\frac{2-0.7733}{\sqrt{0.5486+0}}\approx1.6561,\;\;\;\;\frac{3-0.7733}{\sqrt{0.5486+0}}\approx3.0062\tag{6-25} $$根据式(6-18),此时假定$\gamma=[1,1,...,1]_{1\times75},\beta=[0,0,...,0]_{1\times75}$,则有
$$ \begin{aligned} -0.8261\times1+0&=-0.8261\\[1ex] 2.5229\times1+0&=2.5229\\[1ex] 0.8484\times1+0&=0.8484\\[2ex] 0.3060\times1+0&=0.3060\\[1ex] 1.6561\times1+0&=1.6561\\[1ex] 3.0062\times1+0&=3.0062\\[1ex] \end{aligned}\tag{6-26} $$这里需要再次提醒的是,所有样本在进行平移和缩放时共享参数$\gamma$和$\beta$。
最后,图6-17中每个样本最后一个通道层归一化后的结果(可以同图6-13的结果进行对比)为
1 [[ 0.8484, 0.8484, -0.8261, -0.8261, -0.8261],
2 [-0.8261, 0.8484, -0.8261, -0.8261, 0.8484],
3 [-0.8261, 0.8484, 0.8484, 0.8484, 0.8484],
4 [-0.8261, 0.8484, -0.8261, -0.8261, -0.8261],
5 [-0.8261, 0.8484, -0.8261, -0.8261, -0.8261]]
6
7 [[-1.0441, 0.3060, 0.3060, -1.0441, -1.0441],
8 [-1.0441, 0.3060, -1.0441, 1.6561, 0.3060],
9 [ 0.3060, 1.6561, 0.3060, 0.3060, -1.0441],
10 [ 0.3060, 0.3060, -1.0441, -1.0441, -1.0441],
11 [-1.0441, 0.3060, 0.3060, -1.0441, -1.0441]]上述完整计算示例代码可参见Code/Chapter06/C04_LN/ln_compute.py文件。
3. RNN中的归一化
在理解了CNN中的批归一化计算过程后RNN便相对简单多了。不过这里需要知道的一点是,虽然论文[1]中作者提出的原始动机是对RNN中每个时刻的输出进行归一化然后再将归一化后的结果输入到下一个时刻并以此类推,但是在目前的实际使用中往往只会对RNN最后一层所有时刻计算结束后的输出进行标准化,因此前者在PyTorch中也并没有相关实现,不过在TensorFlow的addons模块中可以通过调用 LayerNormSimpleRNNCell进行实现。