4.4 RAG Agent 原理与搭建#
在前面两个小节的内容中我们详细介绍了大模型中的 Function Calling 机制以及如何借助 LangChain 中的 Tool 修饰器来快速完成流程的搭建。作为铺垫,在了解完 Function Calling 的作用以后再来看如何解决我们在第4.1节中所遗留的问题,即自主判断是否使用知识检索以及将复杂问题进行分解。
4.4.1 RAG Agent 原理#
为了解决上面所提到的问题,我们需要引入一种新的机制——RAG Agent(也称为 Agentic RAG),即 RAG 智能体。RAG Agent 也称为 Agentic RAG,它在传统 RAG 的基础上引入了 Agent 机制,这使得大模型不再只是被动地接收检索结果,而是主动参与整个决策过程,即它自己判断是否需要检索、检索什么、检索几次,以及何时停止等。RAG Agent 的整个驱动流程如图4-5所示。
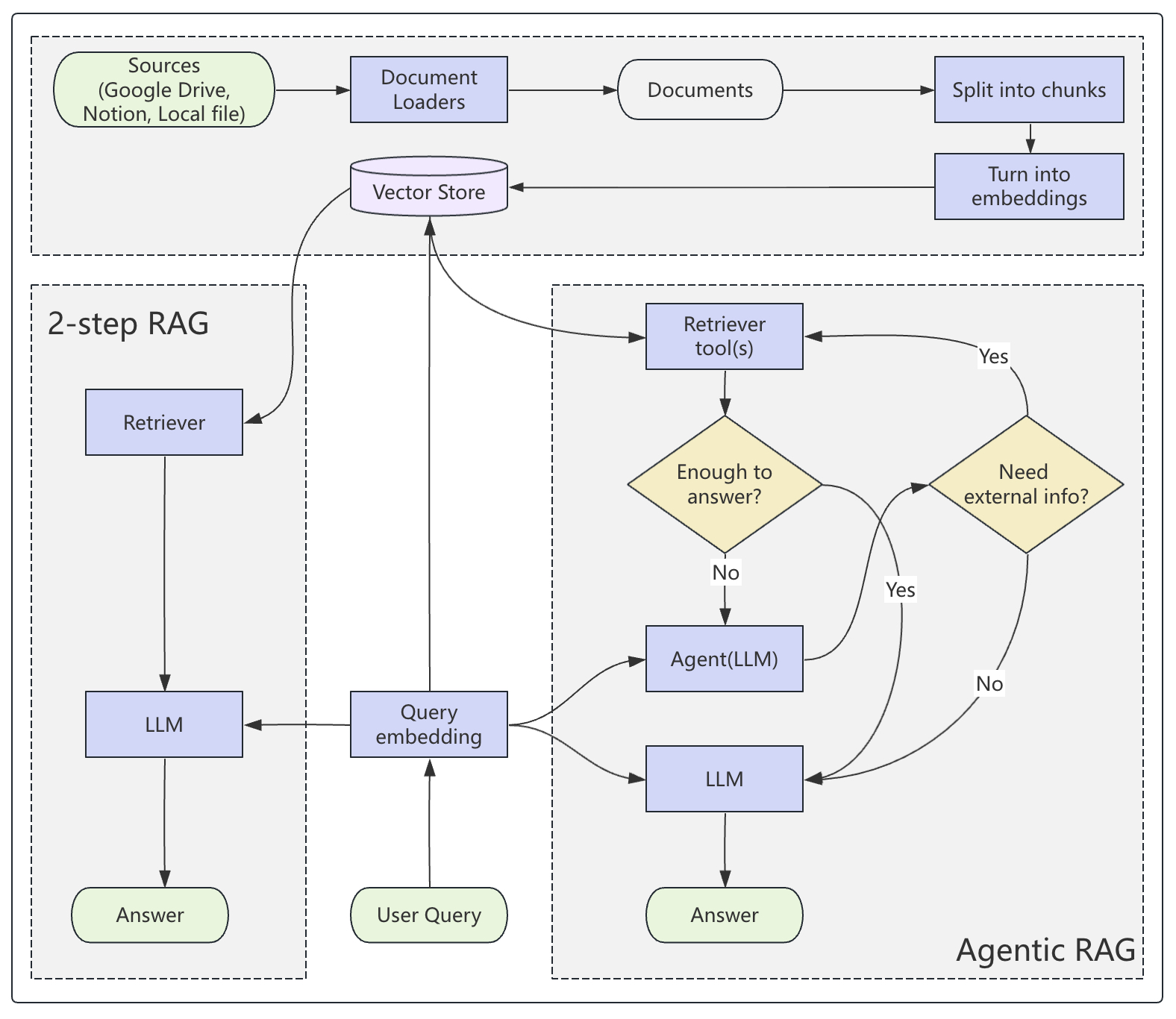
如图4-5所示,上半部分是将原始文档向量化并存储到数据库的过程,下面左右两侧则是 2-Step RAG(传统 RAG) 与 RAG Agent 的流程对比。可以发现,RAG 整个流程分成固定的两步:先检索,再生成。无论用户问什么,系统都会先去知识库检索相关内容,再把检索结果连同问题一起喂给大模型,从而让模型的回答有据可查。
这种架构的优点非常明显,流程固定、行为可预测,每次请求最多发生一次大模型调用;延迟稳定,调试和排查问题也相对容易。但是它的局限性同样清晰,即检索这一动作是"无条件执行"的,不管问题是否真的需要检索,系统都会走一遍完整流程。因此,对于那些问题明确、知识库结构清晰的场景,如文档问答机器人、FAQ 系统,两步式 RAG 是非常合适的选择。
对比 RAG Agent,它在传统 RAG 的基础上引入了 Agent(智能体)机制,不再把“是否检索”作为一个固定步骤,而是把检索能力封装成一个工具,交给大模型驱动的 Agent 自己决定什么时候去检索、用什么内容去检索、检索几次以及何时停止等。这样 Agent 在处理用户问题时会进行多步推理,根据推理的中间结果动态决定下一步行动,并且还可以在不同的工具之间灵活切换,也可以在一次对话中多次调用检索工具,而这也被称为推理与行动(Reasoning Acting, ReAct)[2],将在第4.10节内容中详细介绍。
因此, RAG Agent 这种架构更加灵活性,尤其适合需要同时访问多个数据源、或者问题本身比较复杂需要多步推理的场景,比如研究助手类的应用。当然,灵活性的代价是延迟不确定、执行路径难以预判,因此在对响应速度要求严格的场景下需要谨慎评估使用。
下面,我们将基于第4.1节中的实现代码进行改造来搭建完整的 RAG Agent 流程。以下完整示例代码可参见 Code/Chapter04/C05_tool_semantic_search.py 文件。
4.4.2 大模型实例化#
由于接下来将借助 LangChain 框架来实现整个流程,所以需要使用经过 LangChain 封装的 Chat 模型,示例代码如下:
1 from langchain_openai import ChatOpenAI
2 def get_llm_model():
3 model = ChatOpenAI(
4 api_key=os.getenv('DASHSCOPE_API_KEY'),
5 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
6 model="qwen3.6-plus-2026-04-02")
7 return model上述代码将会返回一个基于 LangChain 框架适配的 OpenAI SDK 实例化对象。
4.4.3 定义语义检索工具#
进一步,我们需要将整个语义检索过程封装成一个工具,供后续大模型使用,示例代码如下:
1 @tool
2 def retrieve_context(query: str, config: RunnableConfig):
3 """
4 信息检索工具,通过检索得到的信息回答用户提问。
5 Args:
6 query: 待检索向量,例如用户提问或子问题。
7 """
8 vector_store = config['configurable'].get("vector_store")
9 k = config['configurable'].get("k")
10 artifact = vector_store.similarity_search(query, k=k)
11 content = "\n\n".join(
12 (f"Source: {doc.metadata}\nContent: {doc.page_content}")
13 for doc in artifact)
14 return content在上述代码中,第2行 query 是业务参数即用户的提问(或经过大模型拆解后的子问题),由大模型决定并自动填充;config 为框架保留的用户自定义参数,通过后续 agent.stream() 中的 config 参数传入。第8~9行是获取得到向量库实例化对象 vector_store 和参数 k。第10~14行则是将检索得到的内容返回,提供给后续大模型作为输入。
这里有一个细节值得注意,@tool 装饰器下面的描述不只是注释(第4行),它是 Agent 决定是否调用这个工具的依据之一,后面大模型将根据它来判断当前场景是否适合调用该工具,因此描述要写清楚工具的用途。
4.4.4 提示词构建#
进一步,我们需要预先定义一个系统提示词内容模板,示例代码如下:
1 def build_prompt():
2 prompt = ("你是一个问答助手,严格遵守以下规则:\n"
3 "1. 回答任何问题之前,必须调用 retrieve_context 工具检索相关内容。\n"
4 "2. 你的回答必须且只能基于 retrieve_context 工具返回的内容。\n"
5 "3. 回答时每一条结论必须在检索结果中有明确的原文依据,禁止通过人物关系、上下文语义、逻辑推断等方式得出检索结果中未直接陈述的结论。\n"
6 "4. 严禁调用任何第三方工具、MCP 服务或外部 API。\n"
7 "5. 如果某条信息在检索结果中没有明确原文支撑,直接略去,不得在回答中提及'该信息未出现'、'无法作答'、'检索结果未包含'等任何说明。\n"
8 "6. 如果检索结果完全与问题无关,才回答'根据现有文档无法回答该问题'。\n"
9 "7. 最后的输出结果请格式化、严肃、正式输出,不要随意分段。\n")
10 return prompt从上述代码可以看出,对于预设提示词我们明确要求当用户问题需要使用工具时,那么回答该(子)问题必须使用工具先检索再回答,并且还对其它特殊情况做出了严格的限制。当然,尽管这样有时候模型的回答也并不尽如人意。所以,在实际情况中,为了让模型的最终输出结果符合实际要求,提示词模板会经过多次反复调试,亦或是切换为更加智能的模型或采用其它手段。
4.4.5 生成用户回答#
在完成上述过程以后,我们便可以借助大模型来对用户提问进行拆解或直接生成最终的回答内容,示例代码如下:
1 def main(agent, query, vector_store, k):
2 config = {"configurable": {"vector_store": vector_store, "k": k}}
3 for event in agent.stream({"messages": [{"role": "user", "content": query}]},
4 stream_mode="values", config=config):
5 last_msg = event["messages"][-1]
6 if isinstance(last_msg, ToolMessage):
7 last_msg.pretty_print()
8 pass
9 else:
10 last_msg.pretty_print()在上述代码中,第3~4行内部便是 LangChain 为我们封装的整个 RAG Agent 迭代调用流程。第6~10行则是详细输出每一步的结果,如果不需要看到检索得到的相关信息,注释掉第7行即可。
4.4.6 运行结果#
在完成整个RAG Agent 流程搭建以后,可以通过如下方式来进行使用:
1 if __name__ == '__main__':
2 tools = [retrieve_context]
3 model = get_llm_model()
4 prompt = build_prompt()
5 vector_store = get_vector_store()
6 agent = create_agent(model, tools, system_prompt=prompt)
7 query = ["张无忌是谁?",
8 "本小说的主角是谁?一旦里找到小说主角,请继续检索他的出生背景等详细信息?"]
9 for q in query:
10 main(agent, q, vector_store, k=3)python在上述代码运行结束以后,对于第7行中的问题将会得到类似如下结果:
================================ Human Message =================================
张无忌是谁?
================================== Ai Message ==================================
Tool Calls:
retrieve_context (call_b17e656a7d204db7a4a67f)
Call ID: call_b17e656a7d204db7a4a67f
Args:
query: 张无忌
================================= Tool Message =================================
Name: retrieve_context
Source: {'level_1': '第十六回 《九阴真经》', 'pk': 4652907197........}
================================== Ai Message ==================================
根据现有文档无法回答该问题。根据上结果可以看出,模型首先根据用户输入 “张无忌是谁?”提取到了 retrieve_context 工具对应的参数 ”张无忌“。最终,检索得到的内容无法回答“张无忌是谁?”这一问题。
对于第8行中的问题将会得到类似如下结果:
================================ Human Message =================================
本小说的主角是谁?一旦里找到小说主角,请继续检索他的出生背景等详细信息?
================================== Ai Message ==================================
Tool Calls:
retrieve_context (call_a031c55c27064320b188e0)
Call ID: call_a031c55c27064320b188e0
Args:
query: 小说主角是谁
================================= Tool Message =================================
Name: retrieve_context
Source: {'level_1': '“金庸作品集”新序', 'pk': 464859367376683008, 'source': ...: 0}
Content: 小说是写给人看的。小说的内容是人。
小说写一个人、几个人、一群人、或成千成万人的和心态,不能......
================================== Ai Message ==================================
Tool Calls:
retrieve_context (call_7a46fe80c2d44439bfee80)
Call ID: call_7a46fe80c2d44439bfee80
Args:
query: 射雕英雄传主角是谁
================================= Tool Message =================================
Name: retrieve_context
Source: {'level_1': '后记', 'pk': 465290817678344355, 'source': '.....}
Content: 《射雕英雄传》作于一九五七年到一九五九年,在《香港商报》连载。......
================================== Ai Message ==================================
Tool Calls:
retrieve_context (call_45fe0e0d897a42d7af99cb)
Call ID: call_45fe0e0d897a42d7af99cb
Args:
query: 郭靖的出生背景
================================= Tool Message =================================
Name: retrieve_context
Source: {'level_1': '第七回 比武招亲', 'pk': 465261515437506672, 'source': '......}
Content: 郭靖之母是浙江临安人,江南六怪都是嘉兴左近人氏,他从小听惯了江南口音,听那少年说的正是自己乡音,......
================================== Ai Message ==================================
本小说的主角是郭靖。郭靖之母是浙江临安人,他从小听惯江南口音;他一生长于沙漠,与拖雷、华筝交好,由江南六怪授艺,自蒙古而来。可以发现,大模型首先对用户问题进行了拆解,得到了第1个子问题“小说主角是谁?”;进一步得到了子问题“ 射雕英雄传主角是谁”;最后得到了子问题“郭靖的出生背景”并结合回答了用户的初始问题。
到此,对于 RAG Agent 的原理及实现过程我们就介绍完了。
引用#
[1] https://docs.langchain.com/oss/python/langchain/retrieval
[2] Yao S, Zhao J, Yu D, et al. React: Synergizing reasoning and acting in language models[J]. arXiv preprint arXiv:2210.03629, 2022. https://arxiv.org/pdf/2210.03629