第 1 章 深度学习简介#
深度学习的进展是多个领域早期贡献的结果。在深度学习领域的演进中,数学、神经科学、计算机科学和统计学等学科的早期研究发挥了至关重要的作用,为深度学习的理论、方法和应用奠定了坚实的基础。在这一进程中,一些关键人物在这些学科的交叉领域中发挥了重要作用,他们的合作努力极大地推动了深度学习领域的发展和应用。与此同时,随着诸如TensorFlow、PyTorch等深度学习框架的涌现,为深度学习的推动提供了更加强大的工具和推进动力。在本章内容中,将首先从上世纪80年代开始,来梳理深度学习的发展脉络,包括各个重要技术的出现以及深度学习发展的兴衰沉浮等;然后,将对深度学习发展中有突出贡献的人物进行一个简单的介绍,并同时梳理常见的几种深度学习框架;最后,对本书的体系结构及相关资源的获取进行了介绍。由于深度学的发展涉及到方法面面,因此本章节内容将主要对与本书相关的部分进行介绍。
1.1 深度学习的发展阶段#
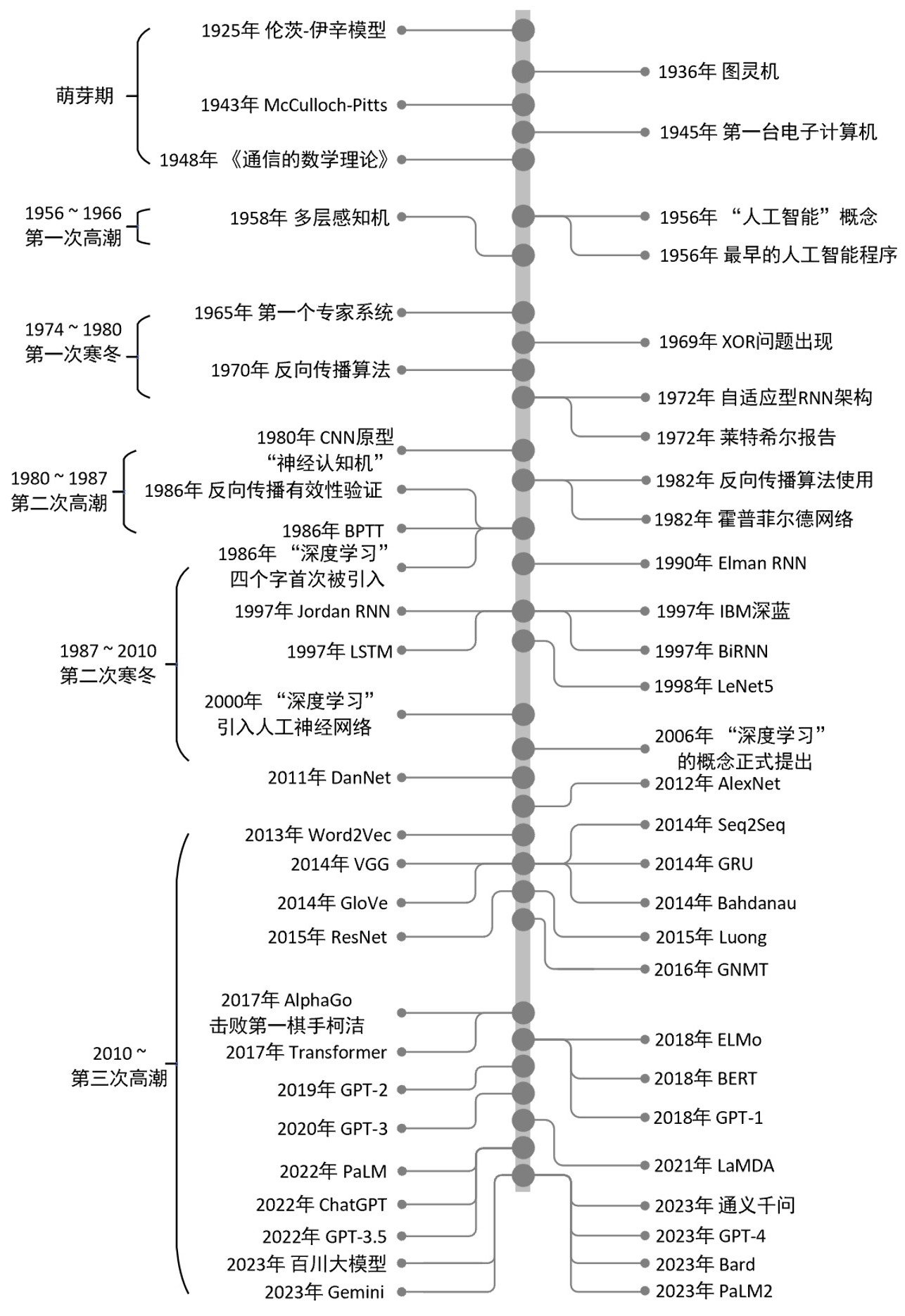
深度学习的概念可以追溯到20世纪80年代,但其真正的兴起和广泛应用要迟至近年。在1980年代,研究人员开始尝试使用多层神经网络来解决复杂的问题,但由于当时计算资源有限、训练困难等问题,深度学习并没有得到广泛的认可和成功。但作为深度学习领域的基础,人工智能(Artificial Intelligence, AI)领域的早理论发展则可追溯至20世纪40年代至50年代末,它也标志着现代计算机科学技术的兴起。
在这一时期,人工智能的萌芽主要集中在解决特定的问题、理解自然语言和基于规则的专家系统。随后,多层感知机的出现激发了深度学习的早期兴趣并奠定了神经网络的基础;进一步,反向传播算法的成功应用成为神经网络研究的重大突破,这一算法在1980年代中期被重新发现和完善,极大地推进了神经网络的训练效率和实用性。紧接着,卷积神经网络的发展,特别是在1990年代的应用和改进,为图像识别和处理带来了革命性的进步。与此同时,循环神经网络的发展为序列数据处理,如语音识别和时间序列分析提供了有效工具。整个人工智能领域所涵盖的研究领域及之间的简单从属关系如图1-1所示。
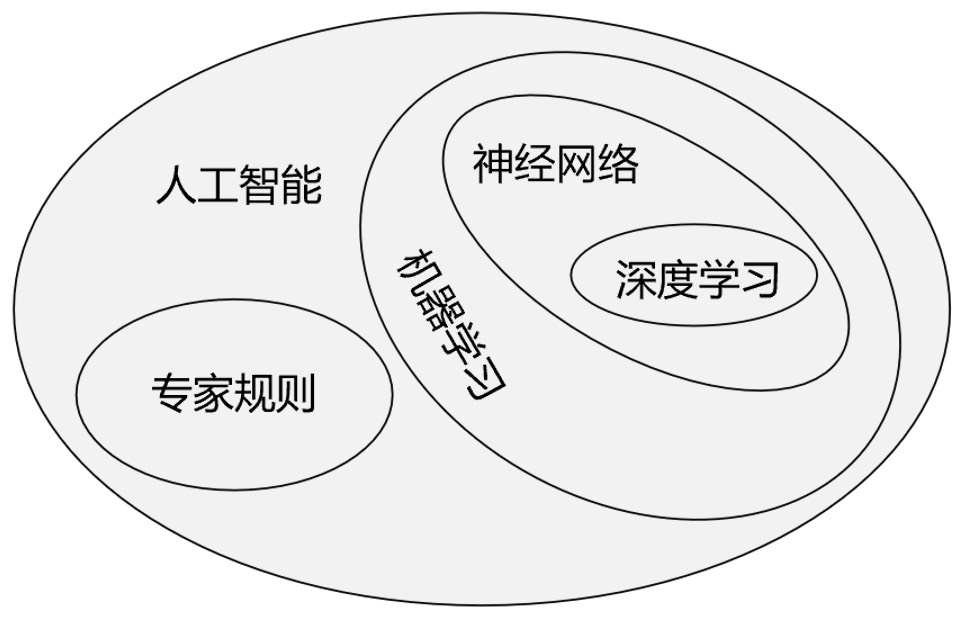
最后,在自然语言处理领域中,AI的发展与应用通过诸如基于变换器的双向编码器表示(Bidirectional Encoder Representations from Transformers, BERT)和生成式预训练变换器(Generative Pretraining Transformer, GPT)等先进模型显著提升了机器翻译、文本生成和语言理解的能力。总体而言,这些发展共同构筑了当代AI领域的基础,推动了技术的不断进步和应用的广泛扩展。
1.1.1 早期理论的发展#
人工智能领域的早期理论发展始于20世纪40至50年代,数学和计算机科学领域取得的关键进展极大地推动了该领域的进程。在此期间,如艾伦·图灵(Alan Turing)、约翰·麦卡锡(John McCarthy)等学者,通过提出革命性的理论概念和计算模型确立了该领域的基本理论框架。同时,约翰·冯·诺伊曼(John von Neumann)关于计算机设计的原理和克劳德·香农(Claude Shannon)的信息理论等,为AI技术的演进也提供了关键性支持。这一时期的理论探索与实际应用的交融,为人工智能领域的持续发展奠定了坚实的基础。
1936年,有着人工智能之父之称的图灵在其论文《可计算数与决策问题的应用》[1]中首次提出了图灵机(Turing Machine)这一概念。在这篇论文中图灵介绍了图灵机这种抽象的理论机器模型,它定义了一个算法是否可计算也就是确定一个问题是否有解。图灵通过其模型展示了特定问题的不可计算性,亦即,不存在能够解决这些问题的算法 [2]。此一重要发现深刻地揭示了计算机能力的边界与局限,对计算机程序设计及人工智能的发展产生了根本性的影响。因此这篇论文也被称为是计算机科学和人工智能领域的里程碑之作,奠定了现代计算机科学的理论基础。
1943年,沃伦·麦卡洛克(Warren McCulloch )和沃尔特·皮茨(Walter Pitts) 提出了一种简化的神经网络模型麦卡洛克-皮茨(McCulloch-Pitts )[3]。该模型基于对生物神经网络的抽象化理解将神经元简化为一种逻辑门(Logic Gates),并且他们认为神经元是一系列具有开和关两种状态的阈值控制单元(Threshold Control Unit),可以通过连接各个神经元建立一个逻辑环路来进行逻辑推导。神经元在进行信号传递时通过计算各个输入值的权重和并同阈值进行比较,只要总和达到了阈电位(Threshold Potential),不论超过了多少都能引起一系列离子通道的开放和关闭,从而形成离子的流动改变跨膜电位 [4],如图1-2所示。
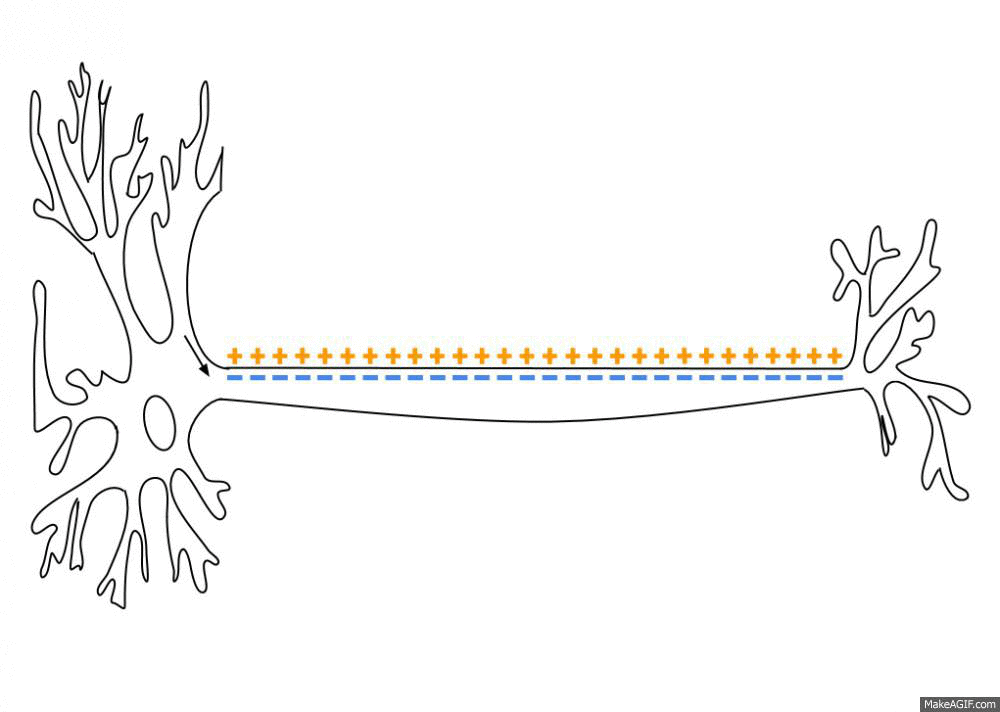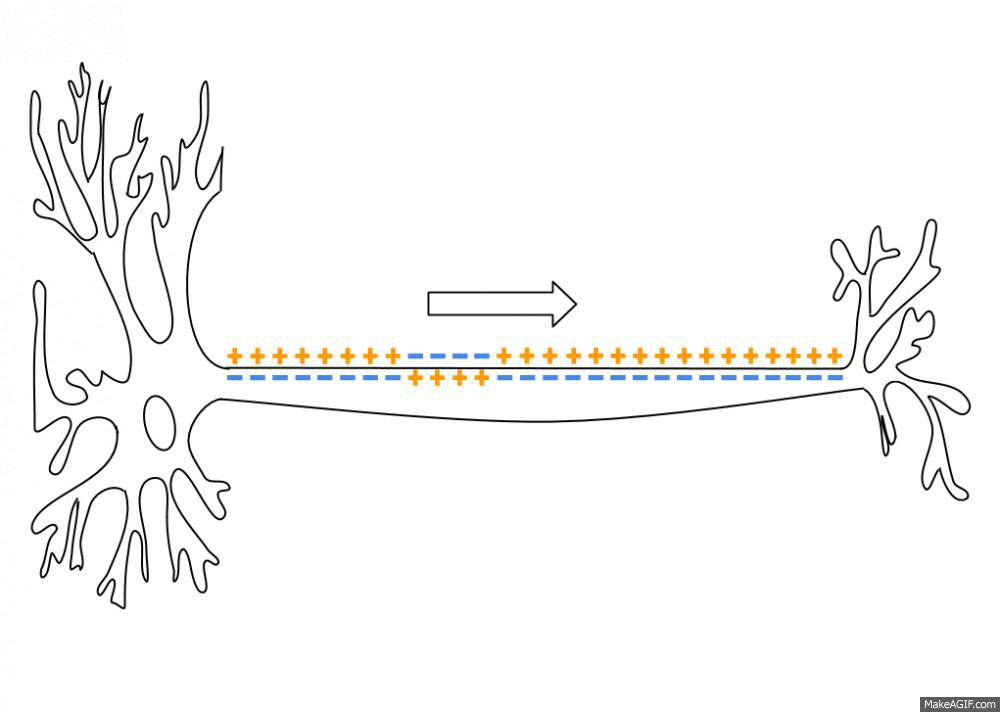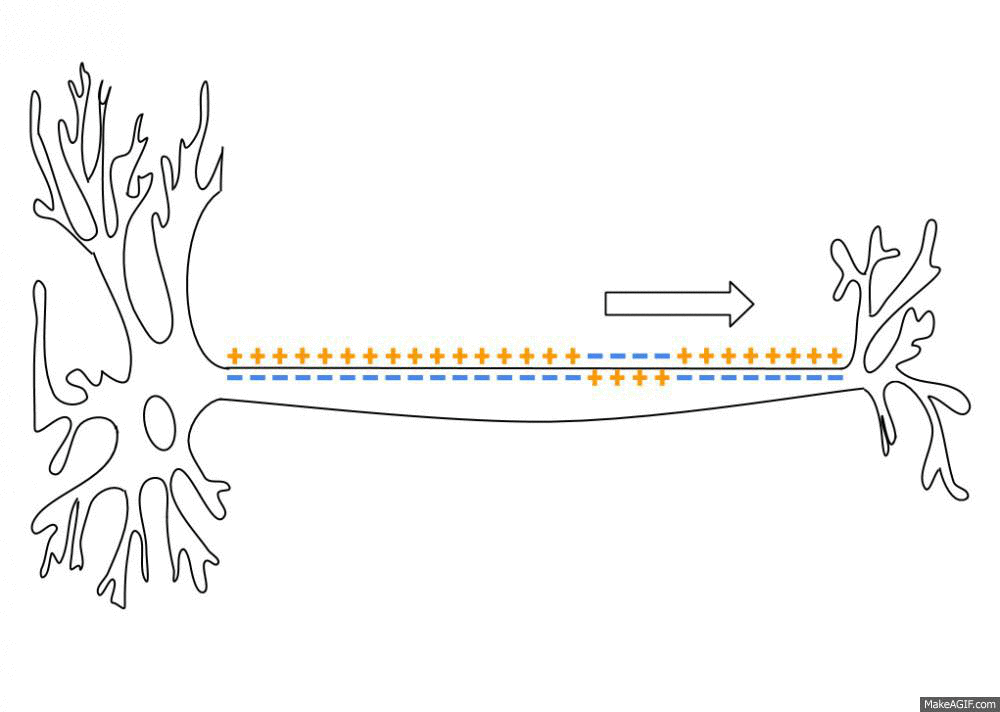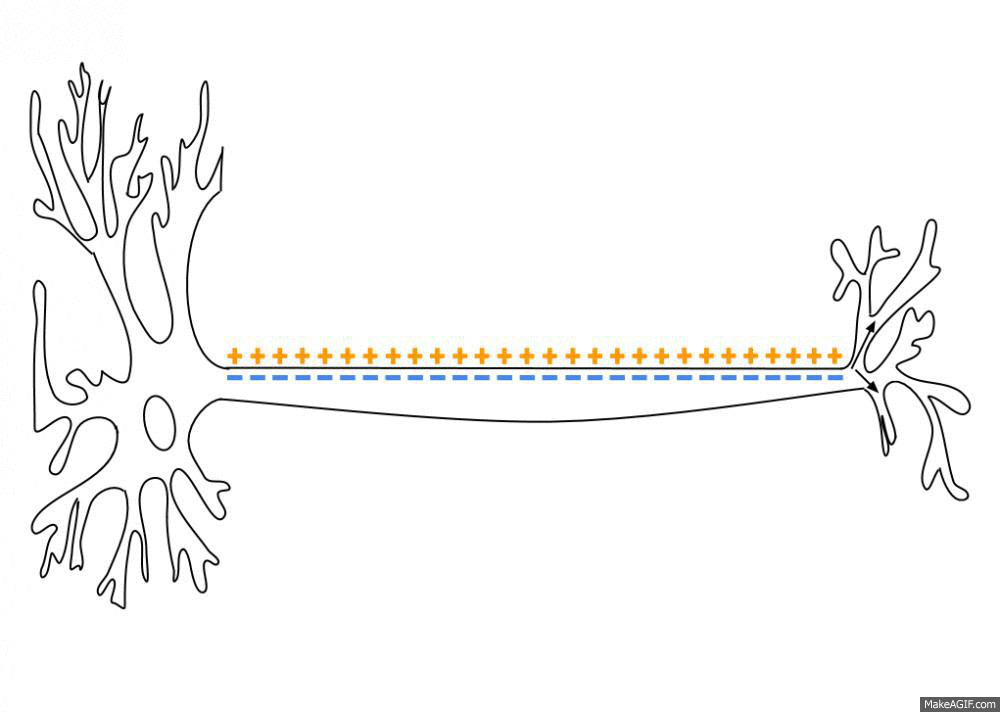
离子流动改变跨膜电位这一过程就可以简单地看作是神经网络的工作原理,同时这也是将神经网络与数学逻辑结合起来的第一次尝试。沃伦·麦卡洛克和沃尔特·皮茨同时也证明了这种简化的神经网络模型能够计算每个可被数学逻辑表达的函数 [5]。这一发现对于理解大脑如何处理信息,以及如何在计算机上模拟这一过程具有重要意义,也对后来的人工神经网络理论产生了深远影响。如图1-3所示便是早期ENIAC的主控制面板。

1945年,在美国宾夕法尼亚大学的约翰·莫奇利(John Mauchly)和约翰·皮斯普·埃克特(J. Presper Eckert)等人的主持下完成了世界上第一台电子计算机(Electronic Numerical Integrator And Computer, ENIAC)设计与建造 [6]。ENIAC是世界上第一台通用计算机,它是图灵完全的电子计算机能够重新编程解决各种计算问题,它的诞生也标志着信息时代的开端为后来的计算机科学和人工智能研究奠定了技术基础。1948年,香农发表了《通信的数学理论》奠定了信息论的基础 [7]。香农通过引入了熵的概念来量化信息中的不确定性,特别是在决策树、信息检索、模式识别等领域中具有重要应用。信息论对理解和建模通信过程中的信息处理非常关键,同样对人工智能的发展产生了深远影响。
总体而言,人工智能早期理论的发展奠定了现代人工智能研究的基础,涉及计算机科学、逻辑学、神经科学和心理学等多个领域。这一时期的研究不仅推动了技术的进步,也引发了关于智能、意识和人机关系等哲学和伦理讨论。
1.1.2 人工智能的萌芽#
1950到1970年代标志着人工智能作为一个独立学科的诞生和初步发展。在这个时期,一系列理论突破和实验性尝试为人工智能的未来发展奠定了基础。1950年,图灵也在他的论文《计算机器与智能》 中首次提出了图灵测试(Turing Test)[8],关于图灵测可以参见9.1节内容。论文开篇即提出一个引人深思的问题:机器能否思考?。通过图灵测试我们可以评估机器是否能够展现出与人类相似的智能。尽管这个测试在当时来看有诸多批评,但是它在思考机器智能的性质和界限方面开辟了新的思路。同时,随着第一台电子计算机的问世专家系统(Expert System)也在这一时期开始兴起。
1956年,在达特茅斯会议(Dartmouth Conference)上约翰·麦卡锡首次正式提出了人工智能这一术语,这也标志着人工智能作为一个独立学科的诞生 [9],因此也推动了对于人工智能的早期探索。他还对后来的列表处理器编程语言(List Processor, LISP)有重大贡献,该语言在人工智能的早期发展中发挥了核心作用。因约翰·麦卡锡推动了人工智能作为一个独立学科的发展以及在人工智能领域的卓越贡献,他在1971年获得图灵奖,同样也被成为人工智能之父[10]。1956年,作为信息处理语言(Information Processing Language, IPL)发明者之一的艾伦·纽厄尔(Allen Newell)和赫伯特·西蒙(Herbert A. Simon)合作开发了逻辑理论家(Logic Theorist)和一般问题解决器(General Problem Solver),旨在模拟人类在解决广泛问题时的思考过程,它们也被称为是世界上最早的两个人工智能程序,其中逻辑理论家更是能够证明《数学原理》中前52个定理中的38个,并且某些证明比原著更加新颖和精巧 [11]。1975年艾伦·纽厄尔和赫伯特·西蒙一起因人工智能方面的基础贡献而被授予图灵奖。
20世纪50年代末,浅层学习(Shallow Learning)在神经网络领域再次流行起来。1958年,弗兰克·罗森布拉特(Frank Rosenblatt)不仅将线性神经网络与阈值函数相结合形成了一种模式分类器,还创造了更为复杂和深层的多层感知机(Multi-Layer Perceptrons, MLPs)[12],如图1-4所示。这些多层感知机的第1层是非学习层具有随机分配的权重,而输出层则具有自适应的可学习参数。虽然这种结构还不属于深度学习,但弗兰克·罗森布拉特实际上已经拥有了后来被称为极端学习机(Extreme Learning Machines, ELMs)的概念,只是当时未得到适当的认可 [5]。在这个时期,研究人员对人工智能的潜力充满了乐观,政府和私人部门在这个时期也对人工智能研究提供了大量的资金支持,一系列重要的里程碑事件和项目推动了人工智能领域的发展。因此,自1956年起的十年里也被称为是人工智能发展的第一次高潮。
1969年, 马文·明斯基(Marvin Minsky) 和 西摩·佩珀特(Seymour Papert)在他们的论著《感知器:计算几何简介》中详细讨论了异或门(eXclusive-OR gate, XOR)问题,提出单层感知机无法解决非线性可分问题 [13]。XOR函数是一种简单的二元逻辑运算,它仅在输入变量具有不同值时输出1(真),如果输入变量相同则输出0(假)。如图1-5所示便是一种经典线性不可分情况。
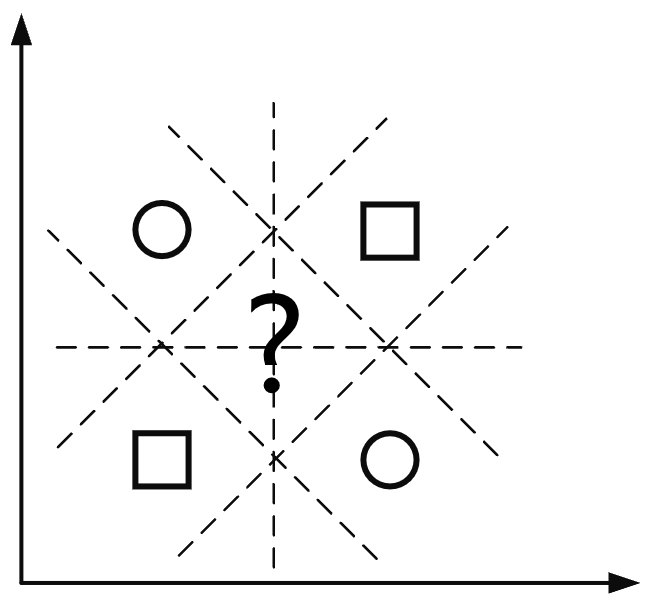
马文·明斯基和西摩·佩珀特的发现对当时神经网络的发展产生了巨大影响,导致一段时间内该领域的研究资金和兴趣显著减少。然而,也正是由于这样的发现催生了后续对更复杂神经网络结构的研究,特别是多层网络和非线性激活函数的研究与应用并最终克服了XOR问题,这对深度学习的发展起到了催化剂的作用。1972年,数学家迈克尔·詹姆斯·莱特希(Michael James Lighthill)为英国科学研究委员会所撰写的《莱特希尔报告》对当时的人工智能研究进行了深刻的批评,指出当前的人工智能在理论上可能很先进但在实际应用中却遇到了重大障碍,大多数研究都没有产生实际应用或商业价值 [14]。这个事件是人工智能发展早期的一个重要转折点,反映了人工智能研究面临的多重困难,包括资金紧缺、技术挑战和公众对人工智能的疑虑,也强调了理论研究和实际应用之间平衡的重要性。因此,1970年代通常也被称为是人工智能的第一个寒冬。
在电子计算机问世以后,研究人员开始尝试使用计算机技术来模拟人类决策的前景,这些系统通常也被描述为专家系统的早期形式 [15]。 例如,生物医学研究人员开始创建用于医学和生物学诊断应用的计算机辅助系统,即通过使用患者的症状和实验室测试结果作为输入来生成诊断结果 [16,17],如图1-6所示。专家系统分为两个子系统:推理机和知识库,知识库代表事实和规则,而推理机则是将规则应用于已知事实以推断出新事实 [15]。1965年,被认为是第一个专家系统的丹德拉(Dendritic Algorithm, Dendral)项目诞生 [18],其主要目的是研究科学假设的形成和发现,例如通过分析质谱并利用化学知识帮助有机化学家识别未知的有机分子。1970年代,专家系统作为人工智能的一个子领域开始获得关注,这一时期的代表作包括用于有机化学分析的启发式丹德拉系统(Heuristic Dendral)和用于医疗诊断的米辛(Mycin)系统,而它们都是源于早期的丹德拉项目。

1950到1970年代的人工智能研究奠定了这个领域的基础。这个时期的研究为后来更复杂和高级的人工智能技术发展铺平了道路。虽然当时的技术和理论有其局限性,但它们对于理解和构建智能系统的探索是至关重要的。在这个时期,人工智能领域的研究人员对这个新兴学科的未来充满乐观,许多人预测机器将很快能够模仿甚至超越人类智能,不过同时大家也开始意识到实现这些目标的复杂和挑战。
1.1.3 反向传播算法的发展#
1980年代对于深度学习的发展来说是一个关键时期,特别是反向传播算法的提出和应用为训练复杂神经网络提供了有效方法,对神经网络的研究产生了积极影响并带领人工智能走出了当时的寒冬进入了第二次高潮。反向传播算法可以有效地计算神经网络中每个权重误差的梯度,从而使得深度神经网络通过梯度下降等优化方法进行训练成为可能,进而大大推动了整个人工智能领域的发展。
1676年戈特弗里德·威廉·莱布尼茨(Gottfried Wilhelm Leibniz )首次在学术论文中提出了微积分的链式法则,它在今天的神经网络中至关重要,使得我们能够精确计算出神经网络中权重参数的微小调整对于最终输出结果的影响 [5]。梯度下降(Gradient Descent, GD)技术最初由奥古斯丁-路易·柯西(Augustin-Louis Cauchy)在1847年提出 [19],后由雅克·阿达玛(Jacques Hadamard)进一步发展 [20],它是神经网络中的关键优化方法。随机梯度下降(Stochastic Gradient Descent, SGD)是梯度下降的变体,由赫伯特·罗宾斯(Herbert Robbins)和萨顿·莫罗(Sutton Monro)于1951年提出 [21],它每次更新参数时只随机选择一个训练样本来计算梯度(详见3.3节内容)。
1970年,赛普·林纳因马(Seppo Linnainmaa)首次发表了现在众所周知的反向传播算法(Back Propagation, BP)[22],同时也被称为自动微分的反向模式(The Reverse Mode of Automatic Differentiation),它是当今众多流行神经网络软件包的核心不分,例如PyTorch 和Tensorflow等深度学习框架。尽管反向传播算法在1970年就已经被提出,但实际上直到1982年保罗·韦伯斯(Paul Werbos)才首先描述了通过误差的反向传播来训练人工神经网络的过程 [23]。不过反向传播算法真正开始普及则是在1986年由大卫·鲁梅尔哈特(David Rumelhart) 、杰弗里·辛顿(Geoffrey Hinton)和罗纳德·威廉姆斯(Ronald Williams)联合发表在《自然》杂志的开创性论文后 [24]。在论文中作者详细阐述了反向传播算法如何有效地通过神经网络传递误差信息并据此更新网络权重以最小化输出误差,并展示了其在多层神经网络中的有效性,解决了如何有效训练多层神经网络的问题,因此也成为了后续深度学习能够蓬勃发展的基石。
在反向传播算法出现之前训练多层网络是非常具有挑战性的,因为难以准确地计算出隐藏层的误差。反向传播算法的应用使得在多层网络中有效地传递误差信息成为可能,从而大幅提高了多层神经网络的训练效率和效果。反向传播算法的提出和成功应用不仅推动了神经网络的发展,也为理解和改进更复杂的学习算法提供了重要的理论基础。尽管反向传播算法在训练神经网络方面极为有效,但它也带来了如陷入局部最小值等问题。同时,随着网络规模的增加反向传播算法的计算复杂性也随之上升。这在当时的计算能力下仍是一个重大挑战,因此也限制了更深层网络的训练。
1980年代反向传播算法的发展是深度学习历史上的一个里程碑。它不仅解决了训练多层神经网络的关键问题,也开启了深度学习在随后几十年里的快速发展。虽然存在一些局限性和挑战,但反向传播算法无疑是推动整个人工智能领域向前发展的关键因素之一。
1.1.4 卷积神经网络的发展#
1990年代对于深度学习的发展是一个重要的十年,特别是卷积神经网络(Convolutional Neural Network, CNN)的发展和应用,这些成就为后来深度学习在图像识别领域的突破奠定了基础。到2010年代,卷积神经网络在图形处理单元(Graphics Processing Units, GPU)的普及下实现了显著的性能提升。GPU的高并行计算能力使得更深、更复杂的CNN模型得以高效训练,从而打破了之前由硬件限制所带来的瓶颈。此外,这一时期也见证了一系列创新性的网络架构的诞生,如亚历克斯·克里泽夫斯基(Alex Krizhevsky)等人提出的AlexNet、牛津大学计算机视觉组(Visual Geometry Group, VGG)提出的VGGNet、以及何凯明等人提出的残差网络(Residual Network, ResNet)等,它们不仅在深度和准确度上实现了突破,也在网络设计上提出了新的思路。这些进展不仅在学术上产生了重大影响,也极大地推动了深度学习技术在工业界的应用。CNN的成功应用进一步证明了深度学习在解决高维数据问题中的强大能力,为人工智能技术的发展开辟了新的道路。
卷积神经网络的概念最早是由日本学者福岛邦彦(Kunihiko Fukushima)于1980年所提出 [25],他设计了一种名为神经认知机(Neocognitron)的神经网络模型,这可以看作是卷积神经网络的早期原型。神经认知机是一种多层的神经网络,具有类似于现代卷积神经网络的结构,用于模拟人类视觉系统对物体的识别过程。值得一提的是,早在1969年福岛邦彦就已经为神经网络引入了修正线性单元(Rectified Linear Unit, ReLU)[26],如今ReLU在神经网络中得到了广泛应用(详见3.12.3节内容)。在1989年,杨立昆(Yann LeCun)基于反向传播算法进一步发展了卷积神经网络,并在实际应用中取得了成功,尤其是在当时的手写邮编数字识别任务上 [27],如图1-7所示。1998年,杨立昆及其团队基于卷积操作提出了著名的LeNet5 [28]网络模型(详见4.4节内容),并采用了反向传播和梯度下降算法来自动学习网络权重参数,是现代卷积神经网络的一个标志性成果。

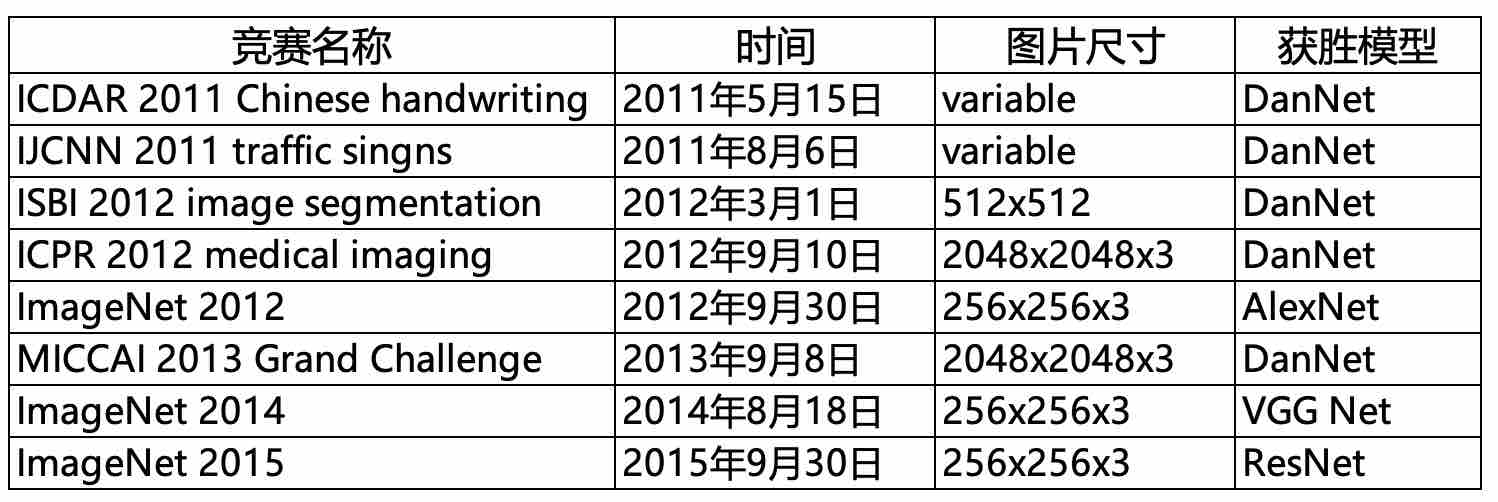
2011年,由丹·奇雷森(Dan Ciresan)等人领衔的团队基于GPU的卷积神经网络DanNet [29],它在网络深度和推理速度上都超越了2006年之前早期GPU加速的卷积神经网络 [5]。令人瞩目的是,DanNet在2011年成为了首个在计算机视觉竞赛中取得胜利的纯深度卷积神经网络,这标志着该技术在实际应用中的重大突破。从2011年到2012年,DanNet连续在四场比赛中胜出,尤其是在2011年的国际神经网络联合会议( International Joint Conference on Neural Networks, IJCNN)比赛中,DanNet显著超越了其他所有参赛者并首次在国际赛事中实现了超人类的视觉模式识别,如表1-1所示。
2012年,由亚历克斯·克里泽夫斯基、伊利亚·苏茨克维尔(Ilya Sutskever)和杰弗里·辛顿共同提出的8层神经网络AlexNet [30](详见4.5节内容)在当年的大规模视觉识别挑战(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)中(详见5.4.1节内容)取得了压倒性胜利,被认为是开启了人工智能春天,并进一步增加了人们对人工神经网络的兴趣。在此之前,虽然深度学习的理论和模型已经存在,但在大规模图像识别任务上还未得到广泛认可,而这一成就证明了深度卷积神经网络在图像识别领域的巨大潜力。2014年由牛津大学计算机视觉组(Visual Geometry Group, VGG)提出的19层神经网络VGGNet [31](详见4.6节内容)赢得了2014年的ILSVRC图像识别比赛,它是继AlexNet之后的又一个里程碑事件,进一步推动了深度学习在计算机视觉领域的发展。2015年,当研究者们还在为苦恼因网络层数过深而导致的神经网络退化问题时,微软研究院何凯明等人提出了基于残差学习网络深度可达152层的深度学习模型ResNet(详见4.9节内容),而它也是首个真正拥有数百层的深度前馈神经网络。ResNet在深度学习领域的发展史上是一个重要的里程碑,它不仅解决了深层神经网络在训练中的问题,还大幅提升了网络模型在各种任务中的精度,对后续深度学习的研究和应用产生了深远影响,这一技术现在几乎已经成为了每个深度学习模型的标配。
卷积神经网络技术在深度学习领域的发展经历了几个关键阶段。最初,福岛邦彦于1980年提出了神经认知机,这是早期CNN的原型。然而,CNN的重大突破发生在1998年,当时杨立昆等人设计了LeNet5模型并成功应用于手写数字识别,证明了CNN在图像处理领域的有效性。2012年,AlexNet的出现在ILSVRC挑战赛中取得了显著成绩,标志着深层CNN的崛起,并促进了GPU加速和ReLU激活函数等技术的普及。此后,深度学习领域见证了诸如VGGNet和ResNet等更高级CNN架构的出现,它们通过增加网络深度和复杂性进一步提升了性能。这些发展不仅推动了计算机视觉的革命,也为自然语言处理、音频分析等其他领域的深度学习应用奠定了基础。
1.1.5 循环神经网络的发展#
1990年代同样也是循环神经网(Recurrent Neural Network, RNN)络取得突破性发展的十年。当时的研究者开始探索如何让模型能够在隐藏层中保持一种状态或记忆使得网络能够利用前一时刻的信息,以此来对时序数据进行处理。RNN正是在这样的理念和动机下逐步发展而来。RNN与人类大脑类似,它们具有反馈方式的循环结构,这种结构使得RNN能够处理序列数据并在内部保持记忆状态,因此,RNN在理解语言、预测时间序列等领域表现出色。然而,RNN也面临一些挑战,如梯度消失或梯度爆炸的问题限制了它们处理长序列的能力。为了克服这些问题,研究者们提出了长短期记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)等网络结构,这些变体通过特殊的门控机制改进了RNN的长期依赖处理能力。
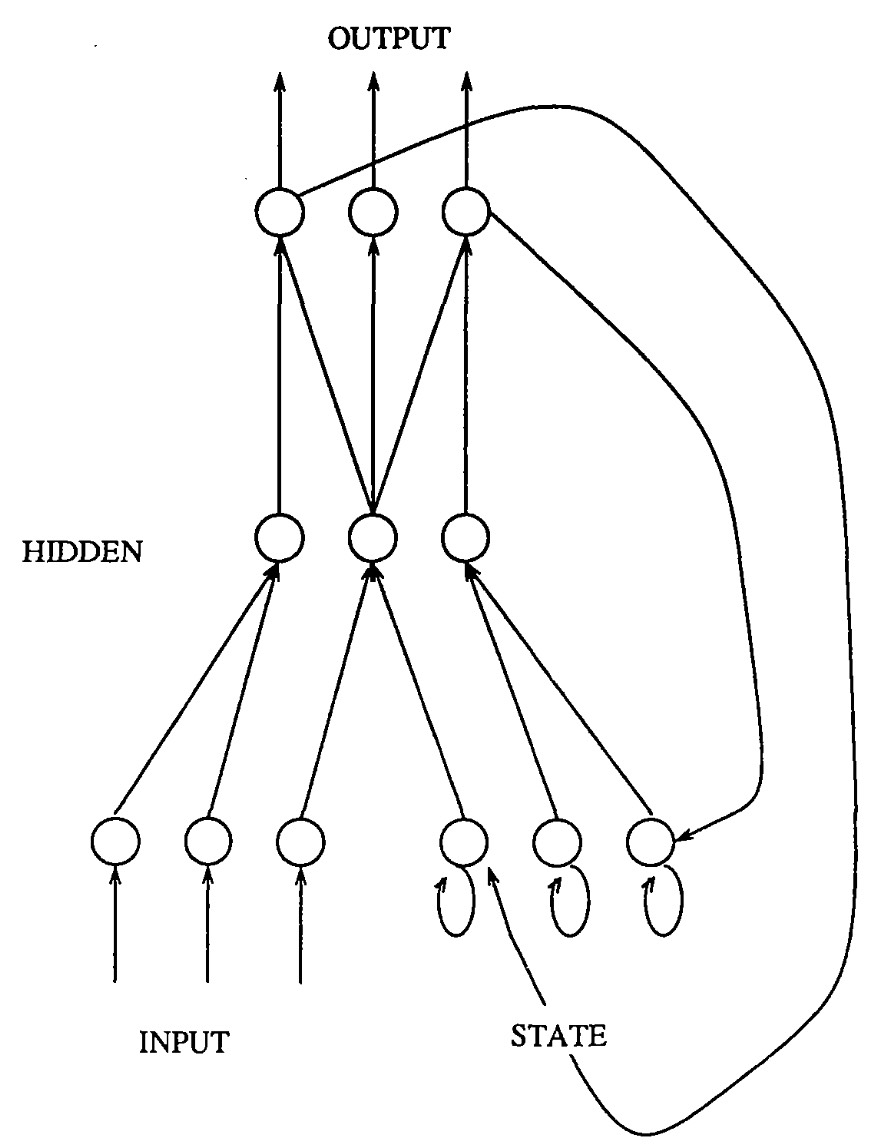
最初的非学习型RNN架构伦茨-伊辛( Lenz-Ising)模型是由物理学家恩斯特·伊辛( Ernst Ising) 和威廉·伦茨( Wilhelm Lenz )在1925年所提出,该模型能根据输入条件达到平衡状态,为后来的学习型RNN奠定了基础 [32]。在1972年,甘利俊一(Shun-Ichi Amari)对伦茨-伊辛架构进行了改进,使其具备了自适应能力可以通过改变其连接权重来学习输入与输出模式之间的关联 [33]。10年后的1982年,该网络被重新发表,提出了一种被称为霍普菲尔德网络(Hopfield Network)[34] 的可学习型RNN模型,其中每个神经元的输出都会影响其自身的下一个状态,即具有自反馈性质。虽然霍普菲尔德网络自身不是RNN,但其在神经网络时间动态和网络记忆方面的探索为RNN的发展提供了启发。1990年杰弗里·洛克·埃尔曼(Jeffrey Locke Elman)等人提出了一种具有短期记忆能力的循环神经网络 Elman Networt [35],这也是我们现在最常使用的一种RNN网络结构(详见7.1节内容),如图1-8所示。与之类似的还有1997年迈克尔·乔丹(Michael Jordan)等人提出的Jordan Network [36]模型,它仅仅只是在隐藏层的计算方式上与Elman Network有所差别。在这段时间中,不少学者开始研究基于时间的反向传播(Back Propagation Through Time, BPTT)算法(详见7.1节内容)来训练RNN模型 [37,38,39]。
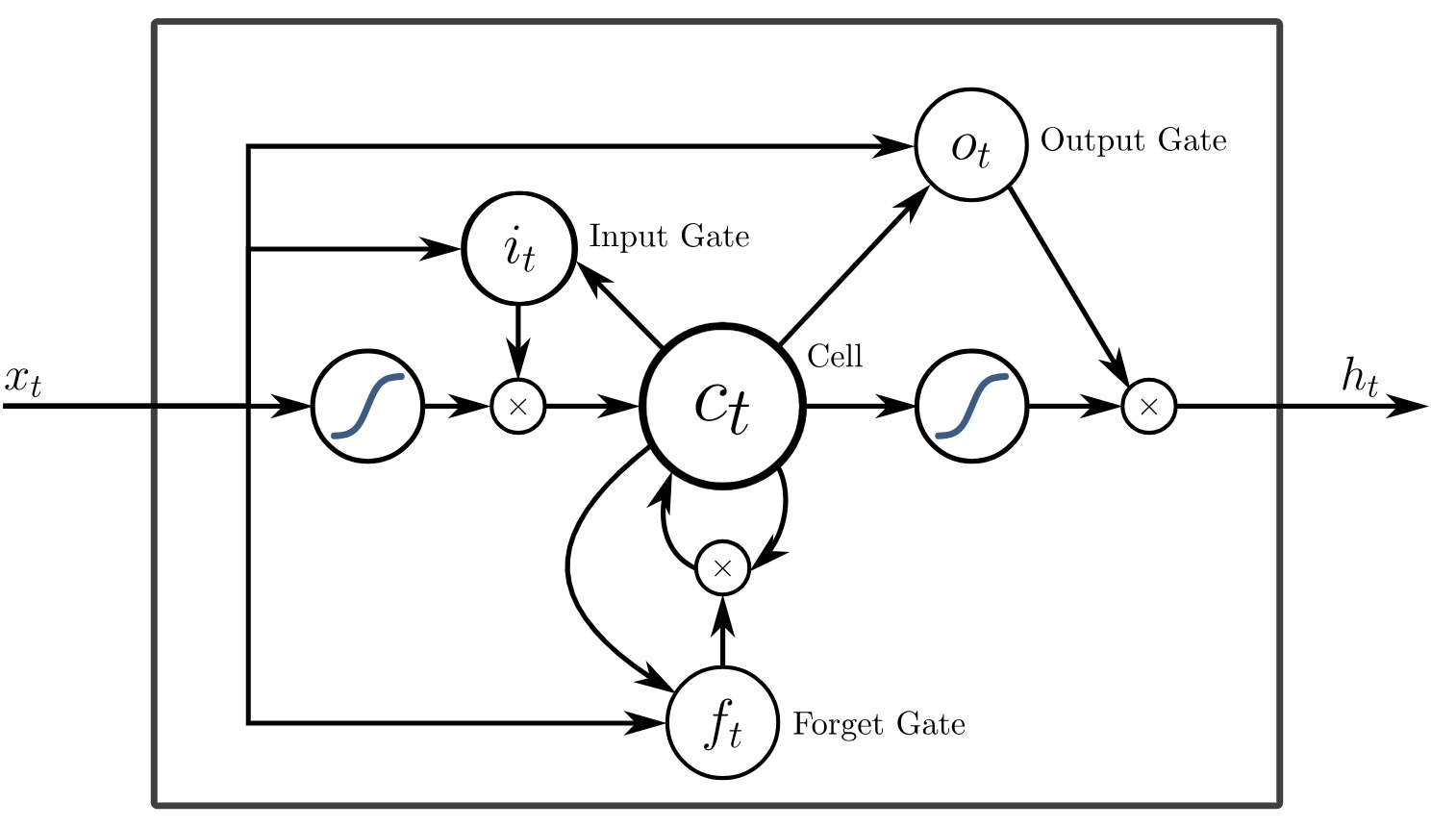
随着RNN研究的深入,研究人员发现在长序列上训练RNN时会遇到梯度消失(Gradient Vanishing)和爆炸(Gradient Exploding)的问题 [40],这极大地限制了模型的学习能力和应用范围。1997年,塞普·霍赫赖特(Sepp Hochreiter)和于尔根·施密德胡伯(Jürgen Schmidhuber)提出了著名的长短期记忆网络LSTM[41],它通过引入门控机制有效地控制了信息的流入和流出,使得网络即使在处理长序列数据时也能够保持梯度稳定,从而解决传统RNN中的梯度消失或爆炸问题(详见7.3节内容)。紧接着,于尔根·施密德胡伯等人在2000年又提出了带有含有窥视连接(Peephole Connections)的循环记忆单元[42],如图1-9所示。2014年曹庆贤 (Kyunghyun Cho)等人在受到LSTM模型的启发,提出了基于门控的循环单元GRU[43]模型,它主要是为了解决LSTM的复杂性和计算成本问题,同时保持LSTM在处理长序列数据时对梯度消失问题的有效应对,是一种更加简化和高效的RNN变体(详见7.4节内容)。
为了提高模型对序列数据的理解和处理能力,特别是在需要同时考虑过去和未来信息的场景中,1997年迈克·舒斯特(Mike Schuster)等人提出了双向循环神经网络(Bidirectional Recurrent Neural Network, BiRNN)模型 [44],使得模型能够同时利用输入序列过去和未来的信息(详见7.5节内容)。同时,实验表明在LSTM中使用双向编码技术能够有效提高模型的预测精度 [45]。随着任务场景的复杂化,研究人员开始尝试将CNN和RNN这两种技术进行结合 [46,47,48],并且还取得了不错的成果(详见8.3节内容)。
循环神经网络技术在深度学习领域的发展可概述为几个关键阶段。初始阶段RNN被设计为用于处理序列数据的时序模型,通过在每个时间步引入前一个时间步的信息来实现模型的记忆功能。然而,标准RNN面临着梯度消失和爆炸的问题,限制了其在长序列学习中的能力。为解决这些问题LSTM应运而生,通过引入门控机制以保持长期依赖,显著提高了模型在复杂序列任务上的性能。接着GRU随后被提出,以更简洁的方式在许多任务中达到了近似LSTM的效果。此外,双向RNN扩展了标准RNN,通过同时处理正向和反向序列信息,增强了模型对上下文的理解能力。
1.1.6 自然语言处理的发展#
深度学习技术的出现对图像处理和自然语言处理(Neural Language Processing, NLP)领域产生了革命性的影响,标志着这两个领域的发展进入了一个新的时代。随着深度学习技术的出现,NLP领域从最初的词嵌入技术[49,50] 到RNN、LSTM的应用,再到近年来注意力机制(Attention Mechanism)[51,52]和基于变换器(Transformer) [53]模型的兴起,极大地提高了机器对人类语言的理解和生成能力。这些技术在机器翻译[51,52,53,54] 、情感分析 [55]、文本生成 [53,56,57,58] 等多个方面均取得了显著进步。
在基于深度学习的NLP应用中一个关键问题就是如何有效地表示文本信息。在NLP领域的早期应用之一便是词嵌入这种技术,通过神经网络模型将词语的高维空间稀疏向量(Sparse Vector)表示成低维空间的稠密向量(Dense Vector),从而捕捉词与词之间的语义关系,如图1-10所示。2013年,托马斯·米科洛夫(Tomas Mikolov) [49]等人提出了第一种基于神经网络技术的词到向量的模型来生成词向量(Word Embedding)或(Word Vector),使得近义词之间的相似性和词之间的语义类比能够通过计算得到(详见9.2节内容)。为了考虑上下文中词频对词向量语义的影响,2014年杰弗里·彭宁顿(Jeffrey Pennington) [50]等人提出了全局向量的词嵌入模型( Global Vectors for Word Representation, GloVe),即基于全局角度来考虑词与词之间共现信息的词向量训练方法(详见9.4节内容)。为了克服静态词向量的缺陷,2018年马修·彼得斯(Matthew E Peters)等人提出了一种基于LSTM的深度双向语言模型(Embeddings from Language Models, ELMo)来学习词向量的动态表示 [59],即对于同一个词在不同的语境中用不同的词向量来进行表示(详见10.1节内容)。

在NLP领域中,一个重要的应用场景就是机器翻译任务。早期的机器翻译系统主要依赖于基于规则和统计的方法。这些系统通过制定语言学规则来转换文字,或使用大量的双语语料库进行统计分析,以找出源语言和目标语言之间的对应关系。然而,这些方法的局限性在于对语言的灵活性和多样性处理不足,以及对复杂句式和隐喻的理解不够深入。2014年,谷歌公司伊利亚·苏茨克维尔(Ilya Sutskever)等人提出了一种基于LSTM的序列到序列(Sequence to Sequence, Seq2Seq)神经机器翻译模型(Neural Machine Translation, NMT)[60],它对自然语言处理和机器学习领域产生了深远影响,开创了使用深度学习方法处理序列到序列任务的新纪元(详见9.7节内容)。2016年,谷歌公司又基于Seq2Seq的NMT模型提出了谷歌神经机器翻译模型(Google Neural Machine Translation, GNMT)模并将其运用在了谷歌翻译服务中 [54]。2014年,德米特里·巴达努(Dzmitry Bahdanau)等人首次提出了一种基于Seq2Seq架构的加法注意力机制模型 [51],2015年明汤·卢昂(Minh-Thang Luong)等人又提出了一种乘法形式的注意力机制模型 [52]。通过注意力机制,模型可以动态地将注意力权重分配到序列的不同位置上,从而提高模型的预测能力(详见9.10节内容)。
由于RNN和LSTM对序列顺序处理特性,因此无法充分利用现代计算硬件(如GPU)的并行处理能力,而这也极大地限制了模型训练的效率尤其是在处理大规模数据时。2017年,阿西什·瓦斯瓦尼(Ashish Vaswani)等人 [53]提出了基于编码器-解码器架构的Transformer模型,其利用自注意力(Self-Attention)机制有效地解决了这一问题(详见10.2节内容)。自注意力机制的引入标志着NLP领域进入了一个全新的时代,它使模型能够专注于输入序列中的特定部分,从而提高处理长序列的能力。不过尽管如此,Transformer架构在提出后并没有引起巨大的反响,直到2018年BERT模型的 [55]提出并直接刷新了多个NLP任务的记录以后,研究者们才再次回过头来研究自注意力机制(详见10.6节内容)。正是由于BERT模型的出现,其预训练(Pre-training)和微调(Fine-tuning)两阶段的范式极大地推动了NLP领域的发展,成为了当代NLP领域的一个重要里程碑。2018年和2019年OpenAI公司基于自注意力机制陆续了提出了GPT-1 [56]和GPT-2 [57] 生成式模型,但同样没有引起业界的关注,直到GPT-3系列模型 [58] 的出现才引起了巨大的轰动(详见10.13节和10.14节内容),通用人工智能(Artificial General Intelligence, AGI)这一概念又开始进入了人们的视野。GPT-1到GPT-3展现了大语言模型(Large Language Model, LLM)在文本生成能力上的显著提升。GPT系列模型通过大规模的语料库预训练,能够生成连贯、富有逻辑性的文本。2022年,基于GPT-3.5的ChatGPT模型一经发布在短短的2个月内就达到了月活跃用户1亿的数量。在GPT-3模型发布34个月以后,2023年3月15日OpenAI在万众瞩目下发布了其最新一代支持多模态的大模型GPT-4 [61],同时也发布了基于GPT-4的ChatGPT模型 (详见10.20节内容)。
在GPT系列模型发布以后,国内外各大公司也分别推出了自己研发的大语言模型。谷歌公司于2021年5月发布了其第一款语言模型对话应用程序式语言模型(Language Model for Dialogue Applications,LaMDA)[62],并于2022年4月和2023年5月发布了第二代和第三代语言模型通路语言模型 (Pathways Language Model, PaLM)及PaLM2 [63]。2023年3月,谷歌也推出了首个基于LaMDA的聊天机器人诗人(Bard )[64],2023年4月改用了更为强大的PaLM模型。在2023年12月,谷歌深度大脑(DeepMind)推出了双子座(Gemini)大语言模型 [65],被定位为与OpenAI的GPT-4抗衡的产品系列,Bard的底层驱动也由PaLM换成了Gemini模型[66]。2023年3月,百度公司也推出了自家首款聊天机器人文心一言 [67]。2023年4月,阿里巴巴公司推出了通义千问聊天机器人 [68]。2023年6月和9月,百川智能分别发布了其第一代和第二代语言模型百川大模型 [69] (详见10.18节内容),如图1-11所示。

Transformer、BERT和GPT的发展不仅是NLP领域的一个重大突破,也是整个深度学习领域的里程碑。这些模型通过更有效的结构和训练方法,大幅提高了机器对人类语言的理解和生成能力。它们的成功应用不仅推动了AI技术的发展,也为未来人工智能的应用提供了新的可能性和方向。随着技术的不断进步,我们可以期待这些模型在未来将带来更多创新和变革。
引用#
[1] Turing A M. On computable numbers with an application to the Entscheidungsproblem [J]. Journal Of Mathematics, 1936, 58(5): 345-363.
[2] https://zh.wikipedia.org/wiki/图灵机
[3] https://en.wikipedia.org/wiki/Warren_Sturgis_McCulloch
[4] https://zh.wikipedia.org/wiki/动作电位
[5] Schmidhuber J. Annotated history of modern AI and Deep learning [J]. arXiv preprint, 2022, arXiv:2212.11279.
[6] https://zh.wikipedia.org/wiki/电子数值积分计算机
[7] Shannon C E. A mathematical theory of communication [J]. The Bell system technical journal, 1948, 27(3): 379-423.
[8] Turing A M. Computing machinery and intelligence[M]. Springer Netherlands, 2009.
[9] https://en.wikipedia.org/wiki/Dartmouth_workshop
[10] https://en.wikipedia.org/wiki/John_McCarthy_(computer_scientist)
[11] https://zh.m.wikipedia.org/wiki/艾伦·纽厄尔
[12] Rosenblatt F. The perceptron: a probabilistic model for information storage and organization in the brain [J]. Psychological review, 1958, 65(6): 386.
[13] Minsky M, Papert S. An introduction to computational geometry[J]. Cambridge tiass, HIT, 1969, 479(480): 104.
[14] https://en.wikipedia.org/wiki/Lighthill_report
[15] https://en.wikipedia.org/wiki/Expert_system
[16] Ledley RS, and Lusted LB. Reasoning foundations of medical diagnosis. Science, 1959, 130(3366): 9–21.
[17] Weiss SM, Kulikowski CA, Amarel S, Safir A. A model-based method for computer-aided medical decision-making. Artificial Intelligence, 1978, 11(1–2): 145–172.
[18] https://en.wikipedia.org/wiki/Dendral
[19] Lemarechal C. Cauchy and the Gradient Method [J]. Doc Math Extra, 2012, 2:251-254.
[20] Hadamard J. Mémoire sur le problème d’analyse relatif à l’équilibre des plaques élastiques encastrées[M]. Imprimerie nationale, 1908.
[21] Robbins H, Monro S. A Stochastic Approximation Method. The Annals of Mathematical Statistics. 1951, 22(3):400.
[22] Linnainmaa S. Taylor expansion of the accumulated rounding error[J]. BIT Numerical Mathematics, 1976, 16(2): 146-160.
[23] Werbos P J. Applications of advances in nonlinear sensitivity analysis [C] Berlin, Heidelberg: Springer Berlin Heidelberg, 2005(1): 762-770.
[24] Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. Nature, 1986, 323(6088): 533-536.
[25] Fukushima K. Neural network model for a mechanism of pattern recognition unaffected by shift in position—Neocognitron [J]. Trans. IECE, 1979, (62)10:658-665.
[26] Fukushima K. Visual feature extraction by a multilayered network of analog threshold elements [J]. IEEE Transactions on Systems Science and Cybernetics. 1969, 5(4): 322-333.
[27] LeCun Y, Boser B, Denker J S, et al. Backpropagation Applied to Handwritten Zip Code Recognition [J], Neural Computation, 1989, 1(4): 541-551.
[28] LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[29] Ciresan D C, Meier U, Masci J, et al. Flexible, High Performance Convolutional Neural Networks for Image Classification [C]. International Joint Conference on Artificial Intelligence, 22th International Joint Conference on Artificial Intelligence, 2011.
[30] Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks. 25th Neural Information Processing Systems, 2012.
[31] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, 770-778.
[32] Ising E. Beitrag zur Theorie des Ferromagnetismus [J]. Z. Phys. 1925, 1(1): 253-258.
[33] Amari S I. Learning patterns and pattern sequences by self-organizing nets of threshold elements [J]. IEEE Transactions, 1972, 1197-1206.
[34] Hopfield J J. Neural networks and physical systems with emergent collective computational abilities [J]. Proceedings of the national academy of sciences, 1982, 79(8): 2554-2558.
[35] Elman J L. Finding structure in time[J]. Cognitive science, 1990, 14(2): 179-211.
[36] Jordan M I. Serial order: A parallel distributed processing approach [M] Advances in psychology. North-Holland, 1997, 121: 471-495.
[37] Werbos P J. Generalization of backpropagation with application to a recurrent gas market model [J]. Neural networks, 1988, 1(4): 339-356.
[38] Werbos P J. Backpropagation through time: what it does and how to do it [J]. Proceedings of the IEEE, 1990, (78)10:1550-1560.
[39] Rumelhart D E, Hinton G E, Williams R J. Learning Internal Representations by Error Propagation [J], Parallel Distributed Processing, 1986, (1)71: 599-607.
[40] Hochreiter S. Untersuchungen zu dynamischen neuronalen Netzen [J]. Diploma thesis, TUM, 1991.
[41] Hochreiter S, Schmidhuber J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780.
[42] https://en.wikipedia.org/wiki/Long_short-term_memory
[43] Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [J]. arXiv preprint, 2014, arXiv:1406.1078.
[44] Schuster M, Paliwal K K. Bidirectional recurrent neural networks [J]. IEEE transactions on Signal Processing, 1997, 45(11): 2673-2681.
[45] Thireou T, Reczko M. Bidirectional long short-term memory networks for predicting the subcellular localization of eukaryotic proteins [J]. IEEE/ACM transactions on computational biology and bioinformatics, 2007, 4(3): 441-446.
[46] Zhou C, Sun C, Liu Z, et al. A C-LSTM neural network for text classification [J]. arXiv preprint, 2015, arXiv:1511.08630.
[47] Li Y, Wang X, Xu P. Chinese Text Classification Model Based on Deep Learning [J]. Future Internet, 2018, 10(11):113.
[48] Kunfu Wang, Pengyi Zhang, et al. A Text Classification Method Based on the Merge-LSTM-CNN Model [C] Journal of Physics: Conference Series, 2020, 1646(1): 012110.
[49] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J].arXiv preprint, 2013, arXiv:1301.3781.
[50] Pennington J, Socher R, Manning C. GloVe: Global Vectors for Word Representation [C]. In Proceedings of the 9th Conference on Empirical Methods in Natural Language Processing, 2014, 1532–1543.
[51] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint, 2014, arXiv:1409.0473.
[52] Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation [J]. arXiv preprint, 2015, arXiv:1508.04025.
[53] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [J]. Advances in neural information processing systems, 2017, 30.
[54] Wu Y, Schuster M, Chen Z, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation [J]. arXiv preprint, 2016, arXiv:1609.08144.
[55] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint, 2018, arXiv:1810.04805.
[56] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training [J]. 2018.
[57] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
[58] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners [J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[59] Matthew E Peters, Neumann M, et al. Deep Contextualized Word Representations [C]. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2018, 1: 2227–2237.
[60] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[J]. Advances in neural information processing systems, 27, 2014.
[61] Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report[J]. arXiv preprint, 2023, arXiv:2303.08774.
[62] https://en.wikipedia.org/wiki/LaMDA
[63] https://en.wikipedia.org/wiki/PaLM
[64] https://zh.wikipedia.org/wiki/Bard
[65] https://en.wikipedia.org/wiki/Gemini_(language_model)
[66] Bard体验地址:https://bard.google.com/chat/
[67] 文心一言体验地址: https://yiyan.baidu.com/
[68] 通义千问体验地址: https://tongyi.aliyun.com/qianwen/
[69] 百川大模型体验地址:https://www.baichuan-ai.com/chat