6.3 批归一化#
在前面两节内容中,我们详细介绍了如何通过学习率动态调整以及梯度裁剪策略来提高模型的效果,在接下来的几节内容中我们将开始陆续介绍一些能够加速模型收敛速度的优化方法。我们知道,在机器学习中一种常见的提高模型收敛速度的方法就是对输入特征进行标准化,例如将每一列特征维度的方差和均值分别标准化为0和1。虽然在深度学习中我们也能够采用这一策略,但这还远远不够。在本节内容中,我们将会介绍深度学习中使用最为广泛的,由谷歌于2015年发表在ICML上所介绍的一种标准化方法——批归一化(Batch Normalization, BN)[1]。
6.3.1 批归一化动机#
在深度学习中,随着网络层数的加深越是越靠近输入层的权重参数其对应的梯度也将会越小(这是由反向传播的性质所决定,可见3.3节内容),所以这就导致靠近输出层的权重参数能够更容易的得到训练,而靠近输入层的权重参数则更新缓慢。也正是由于两端的权重参数在更新节奏上相差太大网络底部的参数更新不及时,使得顶部的参数每次都要根据底部的前向传播结果来重新适应数据的分布,从而加大了网络的训练难度。
假设现在有式(6-10)所示这么一个网络
$$ \mathcal{L}=F_2(F_1(u,\Theta_1),\Theta_2)\tag{6-10} $$其中$F_1,F_2$为任意的两个非线性变换,$u$为原始的网络输入,$\Theta_1,\Theta_2$分别为两个网络层的参数。
现在的目的是通过最小化$\mathcal{L}$来求得参数$\Theta_1,\Theta_2$的取值。此时,我们也可以将$F_2$的输入看成是$x=F_1(u,\Theta_1)$,那么根据式(6-10)有
$$ \mathcal{L}=F_2(x,\Theta_2)\tag{6-11} $$接着根据式(6-12)就可以完成参数$\Theta_2$的迭代求解
$$ \Theta_2\leftarrow\Theta_2-\alpha\frac{\partial F_2(x,\Theta_2)}{\partial \Theta_2}\tag{6-12} $$由式(6-12)可知,由于输入$u$的分布每次在经过网络层$F_1$之后都会发生改变,这意味着网络层$F_2$中的参数$\Theta_2$每次都需要重新来学习适应输入值$x$的分布。也就是说,尽管一开始对原始的输入$u$进行了标准化,但经历过一个网络层后它的分布就发生了改变,那么下一层又需要重新学习另外一种分布,这就意味着每一层其实都是在学习不同的分布。Batch Normalization的思想便是在神经网络中添加一层归一化操作,使得网络中每一层输入的分布都尽可能地接近标准高斯分布,从而减轻这种问题。
6.3.2 批归一化原理#
1. 归一化原理
假设现在有一个$d$维的网络层,其输出为$x=(x^{(1)},x^{(2)},...,x^{(d)})$,那么对于每一个维度都可以通过式(6-13)中的方法进行标准化
$$ \hat{x}^{(k)}=\frac{x^{(k)}-E[x^{(k)}]}{\sqrt{Var[x^{(k)}]}}\tag{6-13} $$其中,$E[x^{(k)}]$和$Var[x^{(k)}]$分别是第$k$个维度在所有样本上计算得到的期望和方差。
但如果仅仅只是简单通过式(6-13)中的计算方法来对每个维度进行标准化,那么在某些情况下将会改变该维度原有的表示信息。例如在对Sigmoid激活函数的输入值进行标准化时,通过公式(6-13)标准化后的输入值可能只会趋于0附近,从而把Sigmoid变成了一个线性激活函数。为了解决这一问题,可以加入了一组学习的参数$\gamma^{(k)}$和$\beta^{(k)}$来对$\hat{x}^{(k)}$进行了一次线性变换,即
$$ y^{(k)}=\gamma^{(k)}\hat{x}^{(k)}+\beta^{(k)}\tag{6-14} $$其中$y^{(k)}$就是最后得到的标准化结果,而$\gamma^{(k)}$和$\beta^{(k)}$也会随着网络中的权重参数一起训练,当且仅当$\gamma^{(k)}=\sqrt{Var[x^{(k)}]}$,$\beta^{(k)}=E[x^{(k)}]$时,公式(6-14)就变成了恒等变换,也就相当于没有进行标准化(如果网络确实需要的话)。
2. 小批量归一化
由于计算机硬件条件的限制等,我们不可能同时将所有的数据一次性输入到网络中进行训练,因此通常情况下都是输入小批量的样本到网络中进行训练,而这也是小批量归一化这个名字的由来。
现假设现有一个样本数量为$m$的小批量数据$\mathcal{B}=\{x_1,x_2,\cdots, x_m\}$,同时由于BN是独立地对每个神经元的输出值进行标准化,这意味着每个神经元都有自己独立的参数,这里以对第$k$个神经元标准化为例进行介绍。具体的,对于整个BN的详细过程为
①在小批量数据样本上根据式(6-15)计算第$k$个神经元输出结果的均值
$$ \mu_{\mathcal{B}}\leftarrow\frac{1}{m}\sum_{i=1}^mx_i\tag{6-15} $$②在小批量数据样本上根据式(6-16)计算第$k$个神经元输出结果的方差
$$ \sigma^2_{\mathcal{B}}\leftarrow\frac{1}{m}\sum_{i=1}^m(x_i-\mu_{\mathcal{B}})^2\tag{6-16} $$③根据式(6-17)以及$\mu_{\mathcal{B}}$和$\sigma^2_{\mathcal{B}}$对$x_i$进行标准化
$$ \hat{x}_i\leftarrow\frac{x_i-\mu_{\mathcal{B}}}{\sqrt{\sigma^2_{\mathcal{B}}+\epsilon}}\tag{6-17} $$④根据式(6-18)对$\hat{x}_i$进行缩放和平移
$$ y_i\leftarrow \gamma\hat{x}_{i}+\beta\equiv \text{BN}_{\gamma,\beta}(x_i)\tag{6-18} $$其中$\mu_{\mathcal{B}}$为在小批量样本$\mathcal{B}$上对$x_i$期望的估计,$\sigma^2_{\mathcal{B}}$为对$x_i$方差的估计,而$\hat{x}_i$则表示标准化后的结果,$y_i$表示线性变换后的结果,也就是最后真正需要的结果。同时,为了防止方差为0的情况在进行标准化时分母额外的加了一个很小的常数$\epsilon$。这里需要说明的是,$\mu_{\mathcal{B}}$和$\sigma^2_{\mathcal{B}}$并不是整个数据集真实的期望与方差,而仅仅只是根据采样的小批量样本估计得到。
3. 预测时的归一化
根据上面内容的介绍,我们已经清楚了批归一化在网络训练时的详细计算过程,同时根据式(6-15)~式(6-18)可知,批归一化中一共有5个参数,$\mu_{\mathcal{B}},\sigma^2_{\mathcal{B}},\epsilon,\gamma$和$\beta$。在这5个参数中,模型在训练阶段里前两个参数是在小批量样本中估计得到,第3个参数则是预先设定的常数(例如1e-5),后面两个参数是随机初始化后随着网络一起训练得到。所以,现在的问题便是当模型在预测阶段时$\mu_{\mathcal{B}},\sigma^2_{\mathcal{B}}$应该如何得到?
为了保证模型在整个测试阶段所使用到的均值$\mu_{\mathcal{B}}$和方差$\sigma^2_{\mathcal{B}}$都相同,一种常见的做法便是在训练过程中采用移动平均策略来估计整个训练集的均值和方差并用于测试阶段中,具体的计算方式为
$$ \begin{aligned} \text{moving\_mean} &= \text{momentum} \times \text{moving\_mean} + (1.0 - \text{momentum}) \times \text{mean}\\ \text{moving\_var} &= \text{momentum} \times \text{moving\_var} + (1.0 - \text{momentum}) \times \text{var} \end{aligned}\tag{6-19} $$其中$\text{mean}$和$\text{var}$是指在每个小批量样本上通过式(6-15)和式(6-16)估计而来,并且通过调节系数$\text{momentum}$可以控制$\text{moving\_mean}$和$\text{moving\_var}$到底是更接近于真实的值还是训练时每个小批量上的估计值。
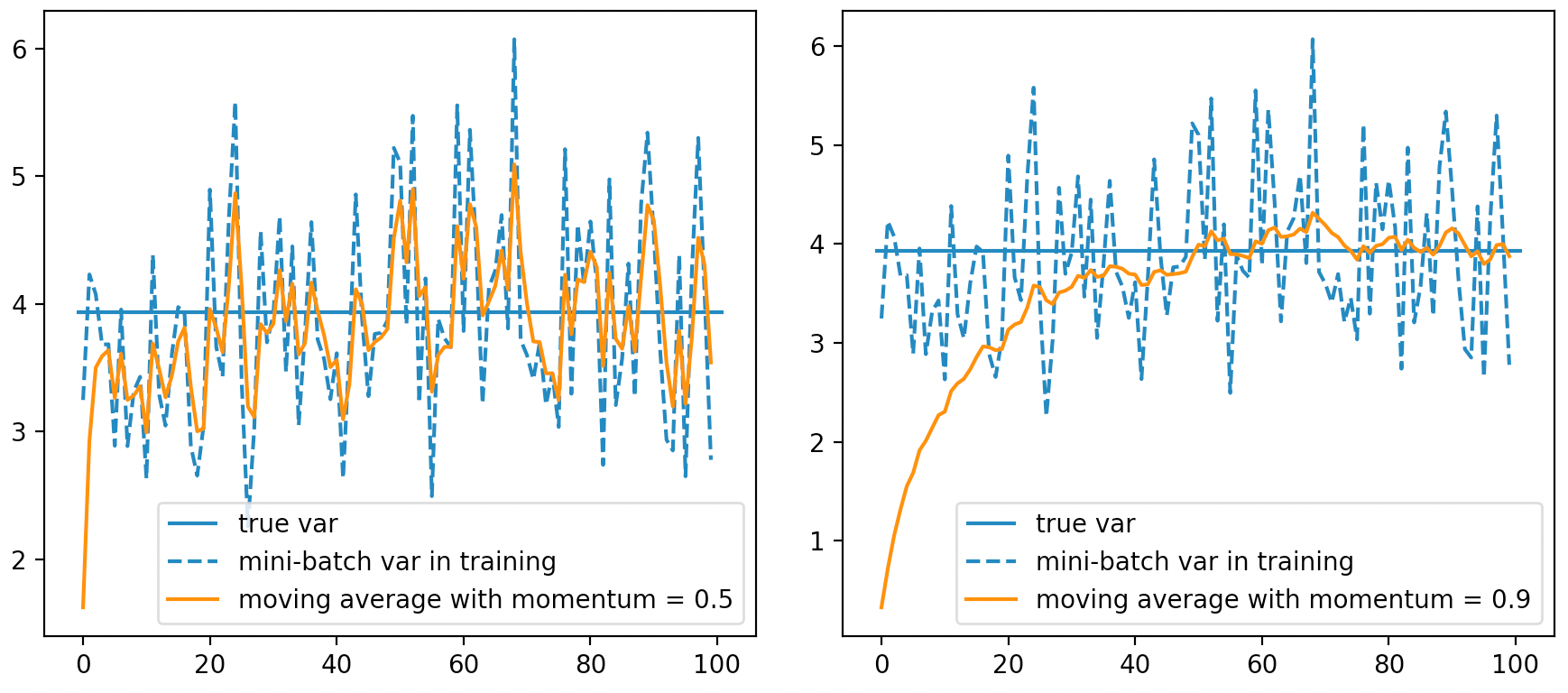
如图6-12所示为不同$\text{momentum}$取值下在小批量样本上计算得到的估计方差(虚折线)、移动平均方差(实折线)和真实方差(水平直线)的变化模拟图。从图6-12(左)可以发现,$\text{momentum}$越小移动平均计算得到的方差就会越靠近训练过程中的估计方差;而根据图6-12(右)可以发现,$\text{momentum}$越大则移动平均计算得到的方差便会更加靠近真实的方差。所以,一般情况下都可以通过调节$\text{momentum}$参数来平衡两者之间的关系。进一步,在通过移动平均的方法计算得到的均值和方差后,再结合训练得到$\gamma$和$\beta$便可以在预测过程中对每一层的输出值进行标准化了。
4. CNN中的归一化
对于卷积操作来说,为了能够使得批归一化遵循卷积特有的性质,所以需要将每个通道的所有神经元以同一个均值、方差、$\gamma$和$\beta$进行标准化。假设某个小批量有$m$个样本,特征图的长和宽分别是$p$和$q$,那么对于每个通道来说,都是用该通道对应的$m\times p \times q$个值来计算均值和方差,并对这$m\times p \times q$个值进行标准化。也就是说,在普通的前馈网络中批归一化是以每一个神经元为单位进行标准化,而在卷积中则是以每个通道为单位进行标准化。
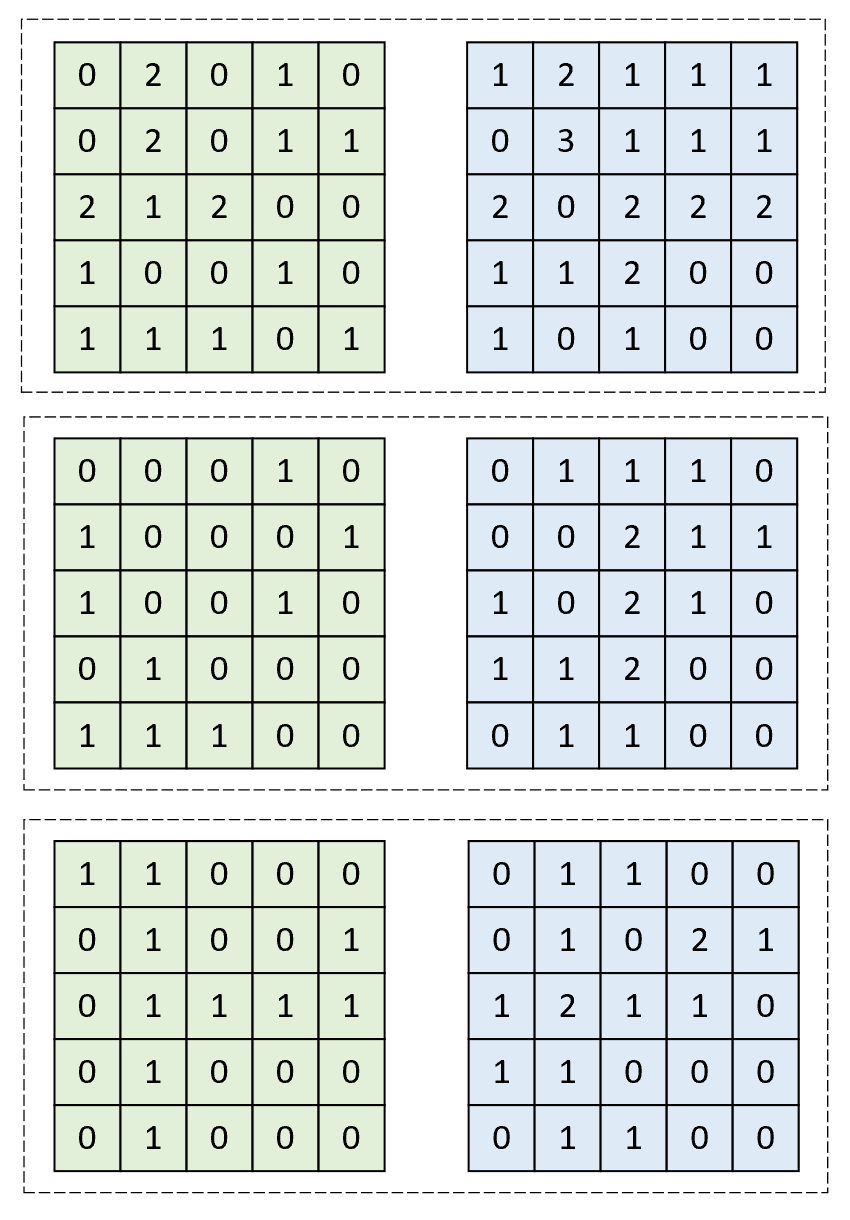
如图6-13所示为两个样本在某卷积层的3个特征图输出结果,且使用批归一化在标准化时是以每个通道(图中虚线框部分)为单位进行,则此时对于最下面的通道来说均值和方差分别为
$$ \begin{aligned} u_1=&\frac{1}{50}((1+1+0+0+0+,...,+0+1+0+0+0)\\[1ex] &+(0+1+1+0+0+,...,0+1+1+0+0))=0.5\\[2ex] \sigma_1^2=&\frac{1}{50}((1-0.5)^2+(1-0.5)^2+(0-0.5)^2+...)=0.33 \end{aligned} \tag{6-20} $$进一步根据式(6-17),此时假定$\epsilon=0$,则有
$$ \frac{1-0.5}{\sqrt{0.33+0}}\approx0.8704,\;\;\;\;\frac{0-0.5}{\sqrt{0.33+0}}\approx-0.8704,\;\;\frac{2-0.5}{\sqrt{0.33+0}}\approx 2.6111\tag{6-21} $$根据式(6-18),此时假定$\gamma=0.2,\beta=0$,则有
$$ \begin{aligned} 0.8704\times0.2+0&\approx0.1741\\[1ex] -0.8704\times0.2+0&\approx-0.1741\\[1ex] 2.6111\times0.2+0&\approx0.5222 \end{aligned}\tag{6-22} $$最后,图6-13中最后两个通道批归一化后的结果为
1 [[ 0.1741, 0.1741, -0.1741, -0.1741, -0.1741],
2 [-0.1741, 0.1741, -0.1741, -0.1741, 0.1741],
3 [-0.1741, 0.1741, 0.1741, 0.1741, 0.1741],
4 [-0.1741, 0.1741, -0.1741, -0.1741, -0.1741],
5 [-0.1741, 0.1741, -0.1741, -0.1741, -0.1741]]
6
7 [[-0.1741, 0.1741, 0.1741, -0.1741, -0.1741],
8 [-0.1741, 0.1741, -0.1741, 0.5222, 0.1741],
9 [ 0.1741, 0.5222, 0.1741, 0.1741, -0.1741],
10 [ 0.1741, 0.1741, -0.1741, -0.1741, -0.1741],
11 [-0.1741, 0.1741, 0.1741, -0.1741, -0.1741]]上述完整计算示例代码可参见Code/Chapter06/C03_BN/bn_compute.py文件
到此为止对于批归一化的原理及计算过程就介绍完了。下面,我们再来进一步介绍如何从零实现归一化及其相关的特性。
6.3.3 批归一化实现#
在介绍完整个批归一化操作的原理后,我们再来看如何通过PyTorch进行实现。以下完整示例代码可以参见Code/Chapter06/C03_BN文件。
1. 前向传播
根据6.3.2节内容的介绍可知,首先需要定义整个批归一化中的相关参数及维度信息,示例代码如下所示:
1 class BatchNormalization(nn.Module):
2 def __init__(self,num_features=None,
3 num_dims=4,momentum=0.1,
4 eps=1e-5):
5 super(BatchNormalization, self).__init__()
6 shape = [1, num_features]
7 if num_dims == 4:
8 shape = [1, num_features, 1, 1]
9 self.momentum = momentum
10 self.num_features = num_features
11 self.eps = eps
12 self.gamma = nn.Parameter(torch.ones(shape))
13 self.beta = nn.Parameter(torch.zeros(shape))
14 self.register_buffer('moving_mean', torch.zeros(shape))
15 self.register_buffer('moving_var', torch.zeros(shape))在上述代码中,第2行num_features用来指定特征的数量,对于全连接层来说便是当前层对应的神经元个数,对于卷积层来说便是当前层对应的通道数。第3行中num_dims用来判断当前层是全连接层(num_dims=2)还是卷积层(num_dims=4),momentum是用来指定移动平均中的控制参数。第6~8行用来设定$\gamma$和$\beta$等参数的形状。第9~13行则是初始化批归一化中的相关参数,其中nn.Parameter()表示定义一个模型参数,然后将其加入到该模型对应的参数列表中,同时它有一个重要的属性就是可训练,即requires_grad=True。第14~15行则是初始化移动平均中均值和方差,其中register_buffer()为从nn.Module()中继承的方法,用于注册一个不可训练但同属为模型一部分的参数,以便在保存模型权重参数时能将其一同保存。
在完成上述初始化工作后便可以进一步实现批归一化的整个前向传播过程,示例代码如下所示:
1 def forward(self, inputs):
2 X = inputs
3 if len(X.shape) not in (2, 4):
4 raise ValueError("仅支持全连接层或卷积层")
5 if self.training:
6 if len(X.shape) == 2:
7 mean = torch.mean(X, dim=0)
8 var = torch.mean((X - mean) ** 2, dim=0)
9 else:
10 mean = torch.mean(X, dim=[0, 2, 3], keepdim=True)
11 var = torch.mean((X - mean) ** 2, dim=[0, 2, 3], keepdim=True)
12 X_hat = (X - mean) / torch.sqrt(var + self.eps)
13 self.moving_mean = self.momentum * self.moving_mean + (1.0 - self.momentum) * mean
14 self.moving_var = self.momentum * self.moving_var + (1.0 - self.momentum) * var
15 else:
16 X_hat = (X - self.moving_mean) / torch.sqrt(self.moving_var + self.eps)
17 Y = self.gamma * X_hat + self.beta
18 return Y在上述代码中,第3~4行用来判断是否为全连接层或是卷积层。第5~14行表示模型当前处于训练阶段,其中第6~8行分别是计算全连接层中每个神经元对应的均值和方差,第10~11行分别是计算卷积层中每个通道对应的均值和方差,同时由于下一步计算时需要利用到PyTorch中的广播机制,所以设定了keepdim=True,第12行则是进行初始的批归一化操作,第13~14行是在训练集上进行移动平均来估计整个数据集的均值和方差。第16行是在测试集上进行初始的归一化操作。第17~18行则是进行缩放与平移,并返回最后的结果。
在实现完上述代码后还可以通过如下方式来进行检验,示例代码如下所示:
1 if __name__ == '__main__':
2 x = torch.randint(0, 10, (1, 2, 4, 4), dtype=torch.float32)
3 bn = BatchNormalization(num_features=2, num_dims=4)
4 print(bn(x))
5 bn = nn.BatchNorm2d(num_features=2)
6 print(bn(x))在上述代码中,第3、5行分别是上述实现的批归一化和PyTorch中的实现,最后的部分输出结果如下所示:
1 tensor([[[[ 0.2560, -0.4886, 0.6282, -1.2332],
2 [-0.4886, 1.3728, 1.7451, -1.6055],
3 ...
4 [ 1.2633, -0.4792, 0.5663, 0.5663]]]], grad_fn=<AddBackward0>)
5 tensor([[[[ 0.2560, -0.4886, 0.6282, -1.2332],
6 [-0.4886, 1.3728, 1.7451, -1.6055],
7 ...
8 [ 1.2633, -0.4792, 0.5663, 0.5663]]]], grad_fn=<NativeBatchNormBackward0>)2. 使用示例
由于BatchNormalization同样是继承自类nn.Module,因此对于它的使用也同其它网络层一样。这里以4.4节中介绍的LeNet5网络模型为例,批归一化的使用方法如下所示:
1 class LeNet5(nn.Module):
2 def __init__(self, ):
3 super(LeNet5, self).__init__()
4 self.conv = nn.Sequential(
5 nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),
6 BatchNormalization(num_features=6, num_dims=4),
7 nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),
8 nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),
9 BatchNormalization(num_features=16, num_dims=4),
10 nn.ReLU(inplace=True),nn.MaxPool2d(2, 2))
11 self.fc = nn.Sequential(
12 nn.Flatten(),
13 nn.Linear(in_features=16 * 5 * 5, out_features=120),
14 BatchNormalization(num_features=120, num_dims=2),
15 nn.ReLU(),
16 nn.Linear(in_features=120, out_features=84),
17 BatchNormalization(num_features=84, num_dims=2),
18 nn.ReLU(),
19 nn.Linear(in_features=84, out_features=10))在上述代码中,第6、9、14和17行便是新加入的批归一化操作,其中对于前面两个归一化来说num_features便是对应的上一层卷积核的个数,后两个归一化中num_features对应的是上一层神经元的个数,num_dims则是指输入张量的维度。
在定义完上述LeNet5网络的前向传播过程之后,便可进行网络的训练过程,输入结果如下所示:
1 Epochs[1/3]--batch[0/938]--Acc: 0.0469--loss: 2.432
2 Epochs[1/3]--batch[50/938]--Acc: 0.9688--loss: 0.4447
3 Epochs[1/3]--batch[100/938]--Acc: 0.9531--loss: 0.2289
4 Epochs[1/3]--batch[150/938]--Acc: 0.9688--loss: 0.1339
5 ...
6 Epochs[1/3]--Acc on test 0.9808从上述输出结果可以看出,相比于4.4节不含批归一化的LeNet5模型,加入批归一化后网络的收敛速度有了明显的加快。同时,根据是否采用批归一化操作还能得到如图6-13所示的损失曲线图。
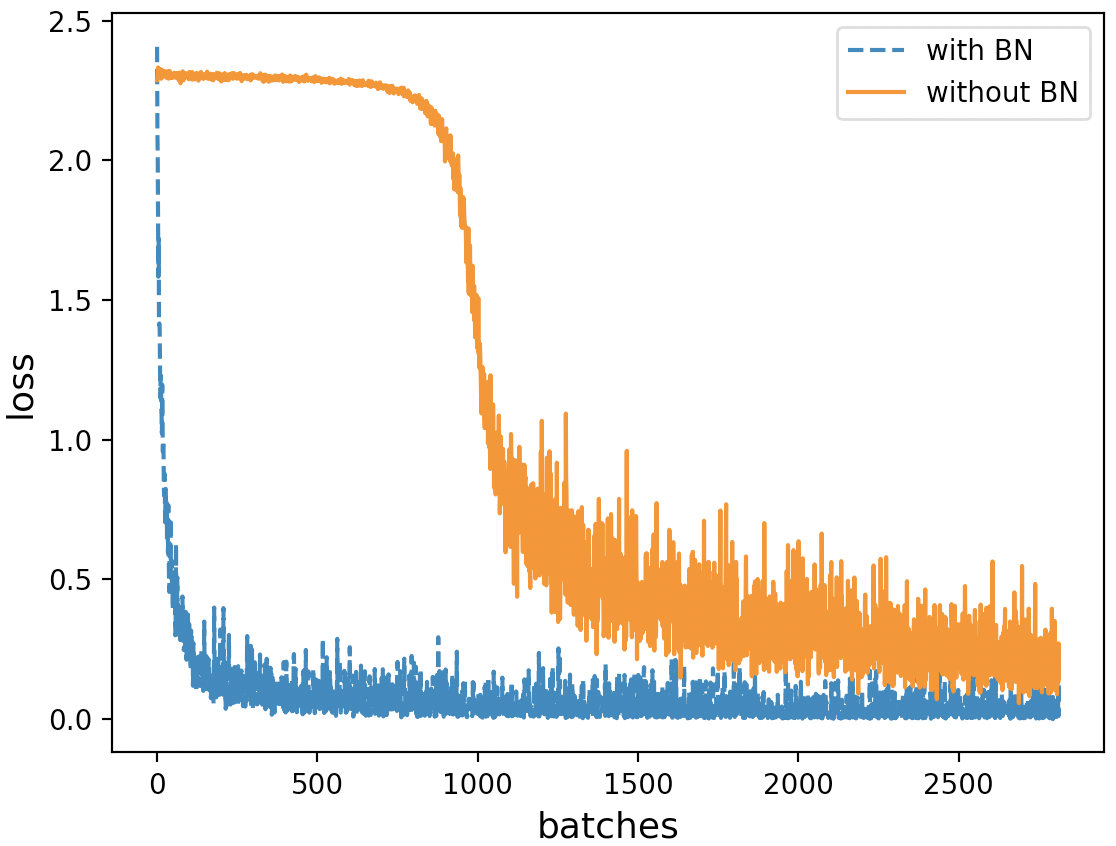
如图6-14所示,上下分别是未使用和使用批归一化后模型损失曲线的变化情况,可以看出使用批归一化的模型在大约500个小批量迭代后就开始进行入了收敛阶段,而没有使用批归一化的模型则在2500个小批量迭代后才逐步开始收敛。除此之外,使用批归一化后的模型还支持使用更大的学习率以及能够增强模型的泛化能力,各自读者可以自行设置相关实验进行验证。
3. 使用顺序
在上面批归一化的使用示例中我们可以发现一个明显的规律,那就是批归一化层均是放在卷积层或全连接层之后非线性变换之前。之所以这样做是因为非线性变换通常都会导致输入的分布发生改变,如果是在激活函数之后使用批归一化那么每次输入到激活的特征分布便是不同的,而这样就没有达到批归一化的初衷。同时,论文作者还认为激活函数之前的线性组合更接近于一个对称的高斯分布,如果是以“线性组合+批归一化+非线性变换”的顺序进行,那么这将使得每次输入到激活函数中的值都具有类似的分布,从而更有利于网络的训练。
当然,上述观点也只是原论文中作者的视角,在实际运用中依然有研究者将批归一化放到了激活函数之后使用。
6.3.4 小结#
在本节内容中,我们首先介绍了批归一化算法提出的原因和动机;然后详细介绍了批归一化的原理及过程,包括训练时的归一化和预测时的归一化等;进一步,介绍了如何从零开始在PyTorch框架中实现批归一化算法的计算过程;最后,以LeNet5模型为例对批归一化层的使用和效果进行了示例和验证。
引用#
[1] Ioffe S, Szegedy C, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. ICML, PMLR, 2015, 37:448-456.