经过前面几个章节的介绍,相信各位读者对于有监督学习和无监督学习这两类机器学习算法已经有了清晰地认识,即前者需要通过样本的真实标签来学习模型中的参数而后者则不需要。因为我们可以根据不同的场景和用途来选择不同类型的算法进行建模。在本章内容中,将会介绍另外一种介于有监督和无监督算法之间的一类机器学习算法——半监督学习(Semi-supervised learning )。
当大家在谈论到分类或者回归任务时,绕不开的一个话题就是标注数据。在有监督的学习任务中,通常都需要大量的标注数据才能有效地使得模型学习到输入$x$到输出$y$之间的映射关系。然而,在实际情况中这一条件却很难满足,因为数据标注既耗费时间同时成本又高昂,并且在很多场景下还需要引入领域专家来对数据进行标注。因此,在这样的情境下半监督学习方式就应运而生了,而它的核心思想就是通过少量有标签的数据和大量无标签的数据来完成整个模型训练。
13.1 Self-Training 自训练算法#
Self-Training是一种通过迭代扩展训练集来提升模型性能的半监督学习方法,从本质上来讲Self-Training并不是一种特定的算法而是一种训练策略,也就是说任何一种有监督算法都可以通过自训练这一策略来进行学习,如图13-1所示便是Self-Training的学习路线图。

13.1.1 Self-Training 算法思想#
Self-Training算得上是几种半监督学习方法中最简单易懂的一种,其核心思想是先通过少量的标注数据来训练一个弱的分类器,然后再通过这个弱分类器来对无标签的样本进行标注,当满足一定条件时(例如预测概率大于某个阈值)则将预测的结果作为该样本的真实标签,接着再次以当前已有的标注数据来训练模型并对无标签的样本进行标注并反复迭代,最后直到达到停止条件时结束。整个Self-Training的迭代过程可以通过图13-2来进行表示。
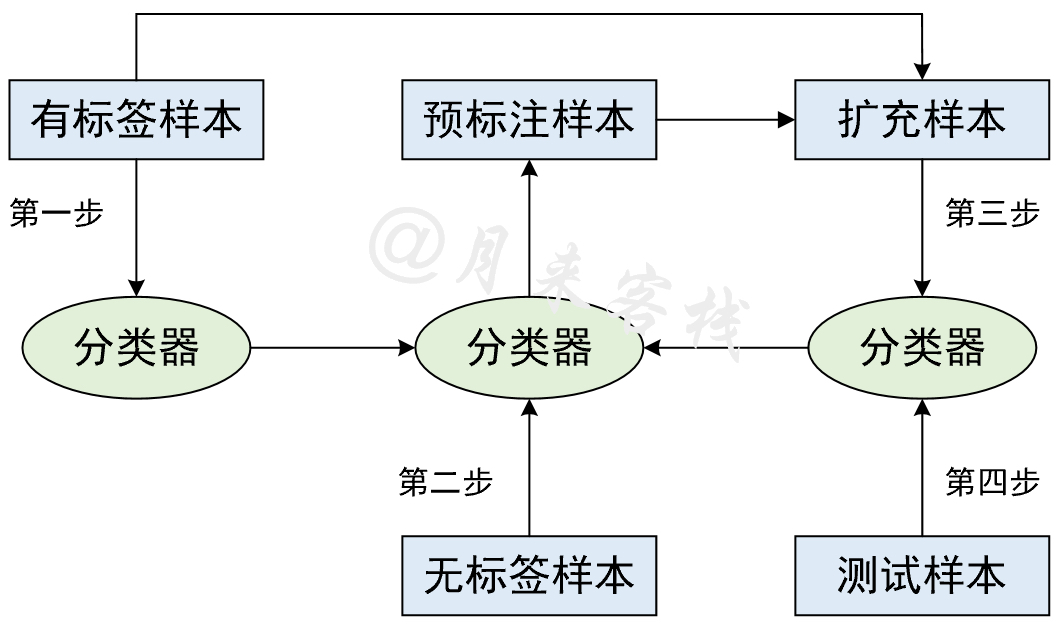
如图13-2所示,第1步先通过少量的标注数据来训练一个弱的分类器;第2步再用这个弱分类器来对无标签的数据样本进行预测,并按某种策略将预测得到的部分标签作为样本的真实标签;第3步则是利用当前所有有标签的样本(包括第2步处理后的样本)来训练分类器,如果达到停止条件则进入第4步,否则继续进入第2步对无标签的样本进行预测;第4步是利用第3步训练得到的分类器在测试集上进行评估。
13.1.2 Self-Training 示例代码#
在介绍完Self-Training算法的思想后,下面来介绍在sklearn中如何使用Self-Training模块,以下完整代码可参见 AllBooKCode/Chapter13/C01_self_training.py 文件。在sklearn中,可以通过sklearn.semi_supervised中的SelfTrainingClassifier模块来使用Self-Training算法,示例代码如下:
1 def load_data():
2 x, y = load_iris(return_X_y=True)
3 x_train, x_test, y_train, y_test = \
4 train_test_split(x, y, test_size=0.3, random_state=2022)
5 rng = np.random.RandomState(20)
6 random_unlabeled_points = rng.rand(y_train.shape[0]) < 0.3
7 y_mixed = deepcopy(y_train)
8 y_mixed[random_unlabeled_points] = -1
9 return x_train, x_test, y_train, y_test, y_mixed在上述代码中,第2~4行分别是读取数据集并划分成训练集和测试集两个部分。第5~8行是确定$30\%$的样本,并将其原始的正确标签重置为-1,即没有标签的样本。第9行则是返回最后处理完成的结果。
进一步,这里使用第10章中介绍的SVM来作为分类器利用Self-Training策略来训练模型,示例代码如下:
1 def test_self_training():
2 x_train, x_test, y_train, y_test, y_mixed = load_data()
3 svm = SVC(probability=True)
4 print(f"一共有{np.sum(y_mixed == -1)}个样本无标签.")
5 model = SelfTrainingClassifier(svm, threshold=0.6)
6 model.fit(x_train, y_mixed)
7 y_pred = model.predict(x_test)
8 print(f"模型在测试集上的准确率为: {accuracy_score(y_pred, y_test)}")
9
10 if __name__ == '__main__':
11 test_self_training()在上述代码中,第3行则是定义一个分类模型,这里是以SVM为例并通过参数probability指定需要返回每个样本的预测概率,而这对于Self-Training训练策略来说也是必须的。第5~6行则是先实例化了一个SelfTrainingClassifier类对象,并指定了分类器和概率阈值,即将预测概率大于阈值的情况视为预测正确。第7~8行则是在测试集上对训练好的模型进行评估。
上述代码运行结束后便会输出类似如下结果:
1 一共有27个样本无标签.
2 模型在测试集上的准确率为: 0.977813.1.3 Self-Training算法原理#
根据Self-Training算法的思想可知,Self-Training本质上可以看做是一种模型的训练策略,因为它并不涉及对于算法本身的改变,此时模型将会作为一个可变的参数来供Self-Training使用。在这个过程中,唯一需要确定的便是第2步中对于预测结果的筛选。通常来讲,可以设定一个概率阈值来决定其最终所属的分类类别。
例如对于一个三分类任务来说,模型在样本$x$上对于每个类别的预测概率为$0.6,0.3,0.1$,同时设定概率阈值为$p$。如果是按照分类算法一般的处理流程,那么样本$x$将会被确定为第$0$个类别。但是在Self-Training中还会根据设定的概率阈值$p$来进行筛选,如果预测概率小于概率阈值,即$0.6< p$那么样本$x$将会继续被归为无标签样本;如果预测概率大于概率阈值,即$0.6\geq p$那么样本$x$才会被确定为第$0$个类别,这一点详见13.1.4的代码实现。
因此,Self-Training算法的一个最大优点就是它能够快速地直接运用于已有的有监督学习算法进行半监督建模学习。
13.1.4 从零实现Self-Training算法#
在介绍完如何通过sklearn来完成Self-Training算法的建模过程后再来看如何从零实现Self-Training算法。根据13.1.3节介绍可知,分类器需要返回每个样本的预测概率,这里将以第10章中介绍的支持向量机为基础来进行实现。以下完整示例代码可参见 AllBooKCode/Chapter13/C02_self_training_imp.py 文件。
1. 类初始化实现
首先,需要实现predict_proba方法来返回样本的预测概率,示例代码如下:
1 from Chapter10.C16_svm_impl import SVM
2
3 class MySVM(SVM):
4 def __init__(self, **kwargs):
5 super(MySVM, self).__init__(**kwargs)
6
7 def predict_proba(self, X):
8 _, prob = self.predict(X, return_prob=True)
9 return prob在上述代码中,第1行是导入之前我们自己实现的SVM模型。第7~9行是返回样本的预测概率值,这里之所以要再次实现一个predict_proba方法而不是直接使用predict方法来返回概率是为了和sklean中的实现风格保持统一,这样下面实现的Self-Training模型同样也可以使用sklearn中的其它分类模型,因为sklearn中的分类模型都是通过predict_proba方法来返回预测的概率值。
接下来,定义一个类和对应的初始化方法,示例代码如下:
1 class SelfTrainingClassifier(object):
2 def __init__(self, base_estimator,
3 threshold=0.75, max_iter=10):
4 self.base_estimator_ = base_estimator
5 self.threshold = threshold
6 self.max_iter = max_iter在上述代码中,第4行base_estimator表示指定的分类器。第5行threshold表示指定的概率阈值。第6行max_iter表示迭代次数,即图13-2中第2步和第3步的循环迭代次数。
2. 模型拟合实现
进一步,再来实现Self-Training模型的拟合部分,示例代码如下:
1 def fit(self, X, y):
2 if not (0 <= self.threshold < 1):
3 raise ValueError("参数 threshold 必须属于 [0,1) 的范围")
4 has_label = y != -1
5 if np.all(has_label): # 如果全都有标签,则表示为有监督学习
6 logging.warning("y 中均为有标签的数据样本")
7 self.transduction_ = np.copy(y) #
8 self.labeled_iter_ = np.full_like(y, -1) # 用来记录每个无标签样本被拟合的次数
9 self.labeled_iter_[has_label] = 0
10 self.n_iter_ = 0
11 if not hasattr(self.base_estimator_, "predict_proba"):
12 msg = "base_estimator ({}) 需要实现 predict_proba 方法来返回每个样本的预测概率!"
13 raise ValueError(msg.format(type(self.base_estimator_).__name__))
14 while not np.all(has_label) and (self.max_iter is None or
15 self.n_iter_ < self.max_iter):
16 self.n_iter_ += 1
17 self.base_estimator_.fit(X[has_label], self.transduction_[has_label])
18 prob = self.base_estimator_.predict_proba(X[~has_label])
19 pred = self.base_estimator_.classes_[np.argmax(prob, axis=1)]
20 max_proba = np.max(prob, axis=1)
21 selected = max_proba > self.threshold
22 selected_full = np.nonzero(~has_label)[0][selected]
23 self.transduction_[selected_full] = pred[selected]
24 has_label[selected_full] = True
25 self.labeled_iter_[selected_full] = self.n_iter_
26 if selected_full.shape[0] == 0:
27 self.termination_condition_ = "no_change" # 结束标志:没有变化
28 break
29 if self.n_iter_ == self.max_iter:
30 self.termination_condition_ = "max_iter"
31 if np.all(has_label):
32 self.termination_condition_ = "all_labeled"
33 self.base_estimator_.fit(X[has_label], self.transduction_[has_label])
34 self.classes_ = self.base_estimator_.classes_
35 return self在上述代码中,第2~3行是验证概率阈值必须属于区间$[0,1)$之间。第4行是获得没有标签的样本在数据集中的索引,其中-1代表没有标签,为False ,非-1代表有标签为True。第5~6行是判断如果所有样本都有标签,将会进行提示,此时也相当于有监督的学习方式。第7~8行用来初始化一个向量,用来记录每个无标签样本被拟合的次数,因为在预测概率小于阈值的情况下该样本会再次被预测。
第11~13行是用来判断分类器中是否存在predict_proba这个方法。第14行开始则是进行整个预测与拟合的循环迭代过程,循环条件为存在没有标签的样本且最大迭代次数为空或累计迭代次数小于最大迭代次数,即停止条件为所有样本均有标签或者是累计迭代次数大于最大迭代次数。第17行是取有标签的部分的样本对模型进行拟合。第18行是对每个没有标签的样本进行预测,此时prob的形状为[n_samples,n_classes]。第19行是以最大预测概率作为每个样本初始的预测结果,并进一步得到每个样本对应的标签值,此时pred的形状为[n_samples,]。第20~21行则是先取每个样本预测概率中的最大值,然后判断该概率值是否超过设定的概率阈值并得到对应的索引。第22行是根据预测概率超过阈值的样本索引选择哪些标签的预测结果是可信的,其中np.nonzero()可用于返回非False位置对应的索引,如 (array([3, 4, 5]),)。
第23行是将预测样本中最大的预测概率大于阈值的预测结果(标签)更新到标签结果中。第24~25行则是设定原本无标签的对应样本为有标签状态,以及更新每个样本点拟合次数。第26~28行表示当前模型的预测结果并没有产生新的标注数据,所以退出迭代并记录停止的状态。第29~32行则是分别记录不同的迭代停止状态。第33行是最后利用所有有标签的样本进行一次模型的拟合。
在完成模型的拟合部分实现之后,再来实现模型的预测部分,示例代码如下:
1 def predict(self, X):
2 return self.base_estimator_.predict(X)
3
4 def predict_proba(self, X):
5 return self.base_estimator_.predict_proba(X)可以看出,这两个方法本质上就是调用了分类器各自对应的预测方法。
3. 使用示例
最后,可以通过如下方式来使用上面实现的SelfTrainingClassifier模型,示例代码如下:
1 def test_self_training():
2 x_train, x_test, y_train, y_test, y_mixed = load_data()
3 svm = MySVM()
4 # svm = SVC(probability=True)
5 print(f"一共有{np.sum(y_mixed == -1)}个样本无标签.")
6 model = SelfTrainingClassifier(svm, threshold=0.6)
7 model.fit(x_train, y_mixed)
8
9 y_pred = model.predict(x_train)
10 print(f"模型训练结束的标志为:{model.termination_condition_}")
11 print(f"模型在训练集上的准确率为: {accuracy_score(y_pred, y_train)}")
12 y_pred = model.predict(x_test)
13 print(f"模型在测试集上的准确率为: {accuracy_score(y_pred, y_test)}")
14
15 if __name__ == '__main__':
16 test_self_training()在上述代码中,第3-4行为实例化一个SVM的类对象。第6-7行则是模型的训练拟合过程。第9-13行是模型在训练集和测试集上的验证结果。
在上述代码运行结束后将会看到了类似如下所示的结果:
1 一共有27个样本无标签.
2 第 1 次迭代结束后,有 14 个未标记样本增加了新标签.
3 模型训练结束的标志为:no_change
4 模型在训练集上的准确率为: 0.9905
5 模型在测试集上的准确率为: 0.977813.1.5 小结#
在本节内容中,我们首先介绍了半监督学习的基本概念,即它是通过少量有标签的数据和大量无标签的数据来完成整个模型训练的过程;然后介绍了半监督学习中最简单的Self-Training算法,包括其思想与具体原理以及它在sklearn中的使用方法;最后详细介绍了如何从零开始实现Self-Training模型。在下一节内容中,我们将开始介绍第2种常见的基于图结构的半监督学习模型——标签传播算法。
引用#
[1] Xiaojin Zhu, Semi-Supervised Learning Tutorial, University of Wisconsin, Madison, USA
[2] https://en.wikipedia.org/wiki/Semi-supervised_learning
[3] https://scikit-learn.org/stable/modules/semi_supervised.html
[4] Olivier Chapelle, Bernhard Schölkopf, and Alexander Zien, Semi-Supervised Learning, MIT Press.