4.4 正则化#
从4.3节的内容可以知道,模型产生过拟合的现象表现为在训练集上误差较小,而在测试集上误差较大,并且我们还讲到之所以会产生过拟合现象是由于训练数据中可能存在一定的噪声,而我们在训练模型时为了尽可能地做到拟合每个样本点(包括噪声),往往就会使用较为复杂的模型。最终使训练出来的模型在很大程度上受到了噪声数据的影响,例如真实的样本数据可能更符合一条直线,但是由于个别噪声的影响使训练出来的是一条曲线,从而使模型在测试集上表现糟糕,因此,可以将这一结果看作由糟糕的训练集导致了糟糕的泛化误差,但仅仅从过拟合的表现形式来看糟糕的测试集(噪声多)也可能导致糟糕的泛化误差。在接下来的内容中,我们将分别从这两个角度来介绍正则化(Regularization)方法中最常用的$\mathcal{l}_2$正则化是如何来解决这一问题的。
这里还是以线性回归为例,我们首先来看在线性回归的目标函数后面再加上一个$\mathcal{l}_2$正则化项项的形式,即
$$ J=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-(\sum\limits_{j=1}^{n}{{{w}_{j}}x_{j}^{(i)}}+b) \right)}^{2}}}+\frac{\lambda }{2n}\sum\limits_{j=1}^{n}{{{({{w}_{j}})}^{2}}};\;\;(\lambda >0)\tag{4-7} $$在式(4-7)中的第2项便是新加入的$\mathcal{l}_2$正则化项(Regularization Term),同时我们也称包含$\mathcal{l}_2$正则化项的线性回归为岭回归(Ridge Regression)。
根据2.1.3节中的内容可知,当真实值与预测值之间的误差越小(表现为损失值趋于0)时,也就代表着模型的预测效果越好,并且可以通过最小化目标函数来达到这一目的。由式(4-7)可知,为了最小化目标函数$J$,第2项的结果也必将逐渐地趋于0。这使最终优化求解得到的$w_j$均会趋于0附近,进而得到一个平滑的预测模型。这样做的好处是什么呢?
4.4.1 测试集导致的泛化误差#
所谓测试集导致糟糕的泛化误差是指训练集本身没有多少噪声,但由于测试集含有大量噪声,使训练出来的模型在测试集上没有足够的泛化能力,而产生了较大的误差。这种情况可以看作模型过于准确而出现了过拟合现象。正则化方法是怎样解决这个问题的呢?
$$ y=\sum\limits_{j=1}^{n}{{{x}_{j}}}{{w}_{j}}+b\tag{4-8} $$假如式(4-8)所代表的模型就是根据式(4-7)中的目标函数训练而来的,此时当某个新输入样本(含噪声)的某个特征维度由训练时的$x_j$变成了现在的$(x_j+\Delta x_j)$,那么其预测输出就由训练时的$\hat{y}$变成了现在的$\hat{y}+\Delta x_jw_j$,即产生了$\Delta x_jw_j$的误差,但是,由于$w_j$接近于$0$附近,所以这使模型最终只会产生很小的误差。同时,如果$w_j$越接近于$0$,则产生的误差就会越小,这意味着模型越能够抵抗噪声的干扰,在一定程度上越能提升模型的泛化能力 [9]。
由此便可以知道,通过在原始目标函数中加入正则化项,便能够使训练得到的参数趋于平滑,进而能够使模型对噪声数据不再那么敏感,缓解了模型的过拟合现象。
4.4.2 训练集导致的泛化误差#
所谓训练集导致糟糕的泛化误差是指,由于训练集中包含了部分噪声,导致我们在训练模型的过程中为了能够尽可能地最小化目标函数而使用了较为复杂的模型,使最终得到的模型并不能在测试集上有较好的泛化能力,但这种情况完全是因为模型不合适而出现了过拟合的现象,而这也是最常见的过拟合的原因。$\mathcal{l}_2$正则化方法又是如何做到在训练过程中就能够降低模型对噪声数据的敏感度的呢?为了便于后面的理解,我们先从图像上来直观地理解一下$\mathcal{l}_2$正则化到底对目标函数做了什么。
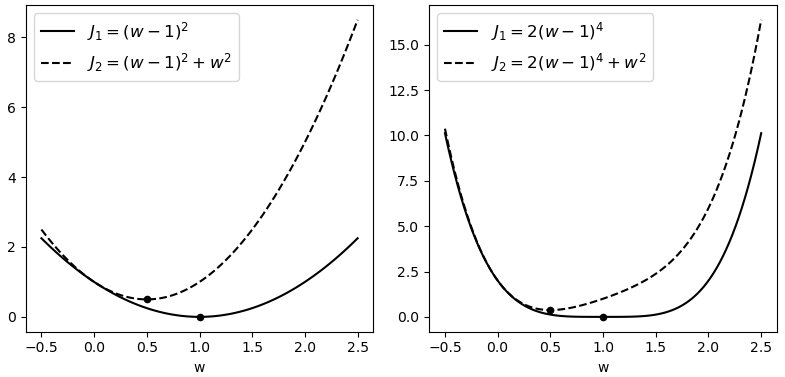
如图4-17所示,左右两边黑色实线为原始目标函数,黑色虚线为添加$\mathcal{l}_2$正则化后的目标函数。可以看出黑色实线的极值点均发生了明显改变,并且不约而同地都更靠近原点。
再来看一张包含两个参数的目标函数在加入$\mathcal{l}_2$正则化后的结果,如图4-18所示。
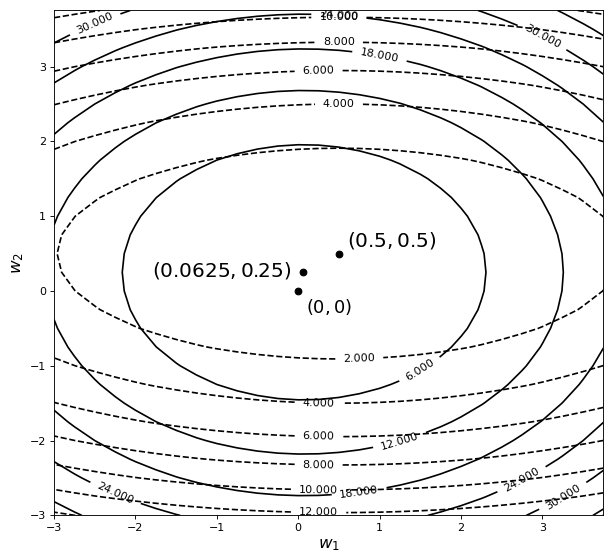
如图4-18所示,图中黑色虚线为原始目标函数的等高线,黑色实线为施加正则化后目标函数的等高线。可以看出,目标函数的极值点同样也发生了变化,从原始的$(0.5,0.5)$变成了$(0.0625,0.25)$,而且也更靠近原点($w_1$和$w_2$变得更小了)。到此我们似乎可以发现,正则化能够使原始目标函数极值点发生改变,并且同时还有使参数趋于0的作用。事实上也正是因为这个原因才使$\mathcal{l}_2$正则化具有缓解过拟合的作用,但原因在哪里呢?
4.4.3 $\mathcal{l}_2$正则化原理#
以目标函数${{J}_{1}}=1/6{{({{w}_{1}}-0.5)}^{2}}+{{({{w}_{2}}-0.5)}^{2}}$为例,其取得极值的极值点为$(0.5,0.5)$,且$J_1$在极值点处的梯度为$(0,0)$。当对其施加正则化项$R=(w_1^2+w_2^2)$后,由于$R$的梯度方向是远离原点的(因为$R$为一个二次曲面),所以给目标函数加入正则化,实际上等价于给目标函数施加了一个远离原点的梯度。通俗点讲,正则化给原始目标函数的极值点施加了一个远离原点的梯度(甚至可以想象成施加了一个力的作用),因此,这也就意味着对于施加正则化后的目标函数$J_2=J_1+R$来讲,因为最小化是取负梯度方向所以$J_2$的极值点$(0.0625,0.25)$相较于$J_1$的极值点$(0.5,0.5)$更加靠近于原点,而这也就是$\mathcal{l}_2$正则化本质之处。
假如有一个模型$A$,它在含有噪声的训练集上表示异常出色,使目标函数$J_1(\hat{w})$的损失值等于$0$(也就是拟合到了每个样本点),即在$w=\hat{w}$处取得了极值。现在,我们在$J_1$的基础上加入$\mathcal{l}_2$正则化项构成新的目标函数$J_2$,然后来分析一下通过最小化$J_2$求得的模型$B$到底产生了什么样的变化。
$$ \begin{aligned} & {{J}_{1}}=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-(\sum\limits_{j=1}^{n}{{w}_{j}}{x_{j}^{(i)}}+b) \right)}^{2}}} \\[1ex] & {{J}_{2}}={{J}_{1}}+\frac{\lambda }{2n}\sum\limits_{j=1}^{n}{{{({{w}_{j}})}^{2}}};\;\;(\lambda >0) \\ \end{aligned}\tag{4-9} $$从式(4-9)可知,由于$J_2$是由$J_1$加正则化项构成的,同时根据先前的铺垫可知,$J_2$将在离原点更近的极值点$w=\tilde{w}$处取得$J_2$的极值,即通过最小化含正则化项的目标函数$J_2$,将得到$w=\tilde{w}$这个最优解,但是需要注意,此时的$w=\tilde{w}$将不再是$J_1$的最优解,即$J_1(\tilde{w})\neq0$,因此通过最小化$J_2$求得的最优解$w=\tilde{w}$将使$J_1(\tilde{w})>J_1(\hat{w})$,而这就意味着模型$B$比模型$A$更简单了,也就代表着从一定程度上缓解了$A$的过拟合现象。
同时,由式(4-7)可知,通过增大参数$\lambda$的取值可以对应增大正则化项所对应的梯度,而这将使最后求解得到更加简单的模型(参数值更加趋近于0)。也就是$\lambda$越大,一定程度上越能缓解模型的过拟合现象,因此,参数$\lambda$又叫做惩罚项(Penalty Term)或者惩罚系数。
最后,从上面的分析可知,在第一种情况中$\mathcal{l}_2$正则化可以看作使训练好的模型不再对噪声数据那么敏感,而对于第二种情况来讲,$\mathcal{l}_2$正则化则可以看作使模型不再那么复杂,但其实两者的原理归结起来都是一回事,那就是通过较小的参数取值,使模型变得更加简单。
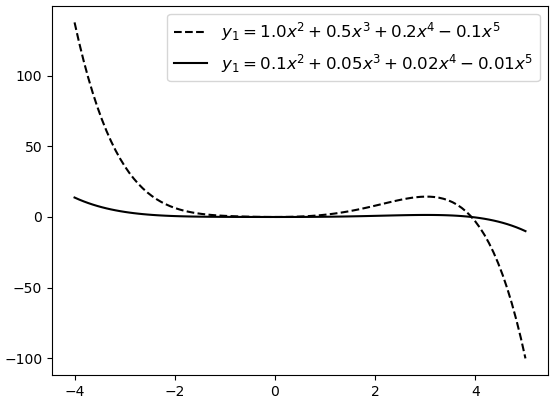
另外值得注意的一点是,很多读者对于复杂模型存在着一个误解。认为高次数多项式表示的模型一定比低次数多项式表示的模型复杂,例如5次多项式就要比2次多项式复杂,但高次项代表的仅仅是更大的模型空间,其中既包含了复杂模型,同时也包含了简单模型。只需将复杂模型对应位置的权重参数调整到更接近于0便可以对其进行简化。如图4-19所示,如果仅从幂次来看,两个模型同样“复杂”,但实际上虚线对应模型的复杂度要远大于实线对应模型的复杂度。
4.4.4 $\mathcal{l}_2$正则化中的参数更新#
在给目标函数施加正则化后也就意味着其关于参数的梯度发生了变化。不过幸运的是正则化是被加在原有目标函数中,因此其关于参数$W$的梯度也只需加上惩罚项中对应参数的梯度即可,同时关于偏置$b$的梯度并没有改变。下面我们就总结一下线性回归和逻辑回归算法加上$\mathcal{l}_2$正则化后的变化。
1. 线性回归
$$ J(W,b)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left[{{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right]}^{2}}}+\frac{\lambda }{2n}\sum\limits_{j=1}^{n}{W_{j}^{2}} \tag{4-10} $$$$ \frac{\partial J}{\partial {{W}_{j}}}=\frac{1}{m}\sum\limits_{i=1}^{m}{\left[{{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right]}\cdot (-x_{j}^{(i)})+\frac{\lambda }{n}{{W}_{j}}\tag{4-11} $$$$ \frac{\partial J}{\partial b}=-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[{{y}^{(i)}}-({{W}^{T}}{{x}^{(i)}}+b) \right]}\tag{4-12} $$可以发现,在梯度的求解公式中仅仅在$W_j$的梯度后加入了新的一项。
2.逻辑回归
$$ J(W,b)=-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\log h({{x}^{(i)}})+(1-{{y}^{(i)}})\log (1-h({{x}^{(i)}})) \right]}+\frac{\lambda }{2n}\sum\limits_{j=1}^{n}{W_{j}^{2}} \tag{4-13} $$$$ \frac{\partial J}{\partial {{W}_{j}}}=-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}-h({{x}^{(i)}}) \right]}x_{j}^{(i)}+\frac{\lambda }{n}{{W}_{j}}\tag{4-14} $$$$ \frac{\partial J}{\partial b}=-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}-h({{x}^{(i)}}) \right]}\tag{4-15} $$从式(4-13)~式(4-15)可以看出,在逻辑回归的梯度求解公式中也仅仅在$W_j$的后面加入了新的一项。同时可以发现,由于在施加了$\mathcal{l}_2$后,其目标函数关于$W_j$的梯度增加的都是相同的部分,因此,此时的梯度下降公式为
$$ W=W-\alpha \left( \frac{\partial J}{\partial W}+\frac{\lambda }{n}W \right)=(1-\alpha \frac{\lambda }{n})W-\alpha \frac{\partial J}{\partial W}\tag{4-16} $$从式(4-16)可以看出,相较于之前的梯度下降更新公式,$\mathcal{l}_2$正则化会令权重$W$先自身乘以小于1的系数,再减去不含惩罚项的梯度。这将使模型参数在迭代训练的过程中以更快的速度趋近于0,因此$\mathcal{l}_2$正则化又叫做权重衰减(Weight Decay)法 [10]。
4.4.5 $\mathcal{l}_2$正则化示例代码#
在介绍完$\mathcal{l}_2$正则化的原理后,下面以加入$\mathcal{l}_2$正则化的线性回归模型为例进行示例。完整代码见AllBooKCode/Chapter04/C16_regularized_regression.py 文件。
1. 制作数据集
由于这里要模拟模型的过拟合现象,所以需要先制作一个容易导致过拟合的数据集,例如特征数量远大于训练样本数量。具体代码如下:
1 def make_data():
2 n_train, n_test, n_features = 50, 100, 100
3 w, b = np.ones((n_features, 1)) * 0.2, 2
4 x =np.random.normal(size=(n_train + n_test, n_features))#
5 y = np.matmul(x, w) + b #用来生成正确标签
6 y += np.random.normal(scale=0.2, size=y.shape)
7 return x,u在上述代码中,第3行代码用来初始化权重和偏置。第5~6行用来随机生成样本的输入特征,同时再加上相应的噪声。
2. 定义目标函数
为了后续方便观察模型的收敛情况,需要定义包含正则化项的目标函数,代码如下:
1 def cost_function(X, y, W, bias, lam):
2 m, n = X.shape
3 y_hat = prediction(X, W, bias)
4 J = 0.5 * (1 / m) * np.sum((y - y_hat) ** 2)
5 Reg = lam / (2 * n) * np.sum(W ** 2) #正则化项
6 return J + Reg在上述代码中,第4行就是普通线性回归中的目标函数。第5行表示正则化项,最后返回原始目标函数加上正则化项的结果。
3. 定义梯度下降
加入正则化后,只需要在参数$W_j$的梯度后加上对应正则化方法的梯度,代码如下:
1 def gradient_descent(X, y, W, bias, alpha, lam):
2 m, n = X.shape
3 y_hat = prediction(X, W, bias)
4 grad_w = -(1 / m) * np.matmul(X.T, (y - y_hat)) + (lam / n) * W
5 grad_b = -(1 / m) * np.sum(y - y_hat)
6 W = W - alpha * grad_w
7 bias = bias - alpha * grad_b
8 return W, bias上述代码整体上与2.7.4节中定义的梯度下降代码一样,仅仅在普通线性回归梯度计算公式的最后加上了正则化项对应的梯度。
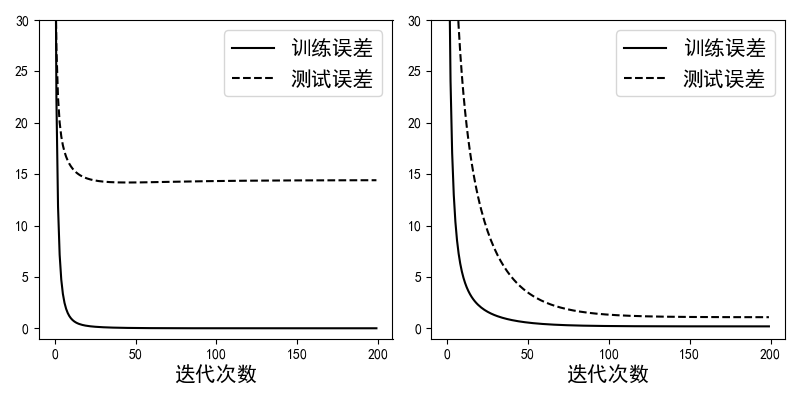
在定义完上述各个函数后,便可以用来训练带正则化项和不带正则化项(lam参数设为0)的线性回归模型。如图4-20所示,左边为未添加正则化项时训练误差和测试误差的走势。可以明显看出模型在测试集上的误差远大于在训练集上的误差,这就是典型的过拟合现象。右图为使用正则化后模型的训练误差和测试误差,可以看出虽然训练误差有些许增加,但是测试误差得到了很大程度上的降低[10]。这就说明正则化能够很好地缓解模型的过拟合现象。
4.4.6 $\mathcal{l}_1$正则化原理#
在介绍完$\mathcal{l}_2$正则化后我们再来简单地看一下$\mathcal{l}_1$正则化背后的思想原理。如式(4-17)所示便是加入$\mathcal{l}_1$正则化后的线性回归目标函数:
$$ J=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {{y}^{(i)}}-(\sum\limits_{j=1}^{n}{{w}_{j}}{x_{j}^{(i)}}+b) \right)}^{2}}}+\frac{\lambda }{2n}\sum\limits_{j=1}^{n}{{{|{{w}_{j}}|}}};\ \ (\lambda >0)\tag{4-17} $$在式(4-17)中的第2项便是新加入的$\mathcal{l}_1$正则化项,同时我们也称包含$\mathcal{l}_1$正则化项的线性回归成为套索回归(Lasso Regression)。
从式(4-17)可以看出$\mathcal{l}_1$正则化与$\mathcal{l}_2$正则化的差别在于前者是各个参数的绝对值之和,而后者是各个参数的平方之和。那$\mathcal{l}_1$正则化又是如何解决模型过拟合现象的呢?
以单变量线性回归为例,且假设此时只有一个样本,在对其施加$\mathcal{l}_1$正则化之前和之后的目标函数如式(4-18)所示
$$ \begin{aligned} J_1&=\frac{1}{2}(wx+b-y)^2\\[2ex] J_2&=J_1+\lambda|w| \end{aligned}\tag{4-18} $$由式(4-18)可知,目标函数$J_1$和$J_2$关于权重$w$的梯度分别为
$$ \begin{aligned} \frac{\partial J_1}{\partial w} &= x(wx+b-y)\\[2ex] \frac{\partial J_2}{\partial w}& = \begin{cases}x(wx+b-y)+\lambda,\;\;w\geq0\\[2ex]x(wx+b-y)-\lambda,\;\;w<0 \end{cases} \end{aligned}\tag{4-19} $$进一步由梯度下降算法可得两者的参数更新公式为
$$ \begin{aligned} w&=w-\alpha\frac{\partial J_1}{\partial w} =w-\alpha\cdot x(wx+b-y)\\[2ex] w&=w-\alpha\frac{\partial J_2}{\partial w} = \begin{cases}w-\alpha\cdot[x(wx+b-y)+\lambda],\;\;w\geq0\\[2ex] w-\alpha\cdot[x(wx+b-y)-\lambda],\;\;w<0 \end{cases} \end{aligned}\tag{4-20} $$为了更好的观察式(4-20)中两者的差异,令$\phi=x(wx+b-y)$,$\alpha=1$,此时有
$$ \begin{aligned} w&=w-\alpha\frac{\partial J_1}{\partial w} =w-\phi\\[2ex] w&=w-\alpha\frac{\partial J_2}{\partial w} = \begin{cases}(w-\lambda)-\phi,\;\;w\geq0\\[2ex] (w+\lambda)-\phi,\;\;w<0 \end{cases} \end{aligned}\tag{4-21} $$此时根据式(4-21)中两者对比可知,对于施加$\mathcal{l}_1$正则化后的目标函数来说,当$w\geq0$时,$w$会先减去$\lambda$;当$w<0$时,$w$会先加上$\lambda$;所以在这两种情况下更新后的$w$都会更加的趋向于0,而这也就是$\mathcal{l}_1$正则化同样能缓解模型过拟合的原因。
同时,这里值得一提的是因为偏差项是对模型的全局偏移或平移,它不影响样本中各个特征之间的相对关系,所以并不会导致过拟合因此不需要进行正则化 [13]。
4.4.7 $\mathcal{l}_1$与$\mathcal{l}_2$正则化差异#
根据前面的几节内容的介绍可知,$\mathcal{l}_1$和$\mathcal{l}_2$正则化均能够使得求解得到的参数趋向于0(即接近于0),但是对于$\mathcal{l}_1$正则化来说它却更容易使得模型参数变稀疏,即直接使得模型对应的参数变为0(不仅仅是接近)。那$\mathcal{l}_1$正则化是如何产生这一结果的呢?
以单变量线性回归为例,对其分别施加$\mathcal{l}_1$和$\mathcal{l}_2$正则化后,目标函数关于参数$w$的梯度分别为
$$ \begin{aligned} \mathcal{l}_1:\;\;\;\;\;&\begin{cases} x(wx+b-y)+\lambda,\;\;w\geq0\\[2ex] x(wx+b-y)-\lambda,\;\;w<0 \end{cases}\\[2ex] \mathcal{l}_2:\;\;\;\;\;& x(wx+b-y)+\lambda w \end{aligned}\tag{4-22} $$
根据式(4-22)可知,对于$\mathcal{l}_1$正则化来说,只要满足条件$|x(wx+b-y)|<\lambda$,那么带有$\mathcal{l}_1$正则化的目标函数总能保持,当$w<0$时单调递减,当$w\geq0$时单调递增,即此时一定能在$w=0$产生最小值。对于$\mathcal{l}_2$正则化来说,当$w=0$时,只要$x(wx+b-y)\neq 0$,那么带有$\mathcal{l}_2$正则化的目标函数便不可能在$w=0$出产生最小值。也就是说,对于$\mathcal{l}_1$正则化来说只需要满足条件$-\lambda 当然,我们还可以从另外一个比较直观的角度来解释为什么$\mathcal{l}_1$正则化更容易产生稀疏解。从本质上看,带正则项的目标函数实际上就等价于带约束条件的原始目标函数,即为了缓解模型的过拟合现象可以对原始目标函数的解空间施加一个约束条件,而这个约束便可以是$\mathcal{l}_1$或者是$\mathcal{l}_2$正则化。例如对于带$\mathcal{l}_1$约束条件的目标函数有
从式(4-23)可以看出,这是一个典型的带有不等式约束条件的极值求解问题。根据第10.6节介绍的内容可以得到对应的如下拉格朗日函数
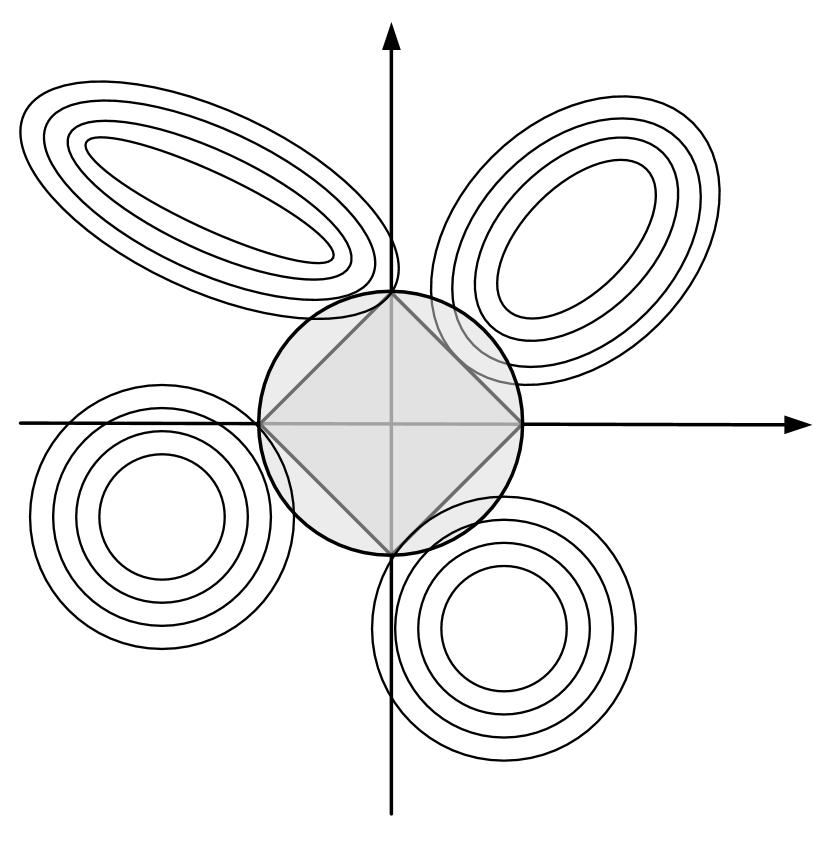
其中$\mu$被称为拉格朗日乘子,可以看出本质上它就等同于式(4-17)中的惩罚系数$\lambda$,同时由于$t$为常数,所以式(4-24)与目标函数(4-17)等价。 进一步,根据式(4-24)可以画出在二维特征条件下原始目标函数与$\mathcal{l}_1$约束条件下解的分布情况(同理还可以画出$\mathcal{l}_2$约束条件下的解空间),如图4-21所示。 在图4-21中,椭圆曲线表示目标函数对应的等高线,菱形和圆形分别表示$\mathcal{l}_1$和$\mathcal{l}_2$约束条件下对应的解空间。从图中可以看出,目标函数在$\mathcal{l}_1$约束条件下于p处取得最小值,在$\mathcal{l}_2$约束条件下于q处取得最小值。此时可以发现,由于$\mathcal{l}_1$约束条件下的解空间为菱形,因此相较于$\mathcal{l}_2$约束,$\mathcal{l}_1$更容易在顶点处产生极值,这就导致$\mathcal{l}_1$约束更能够使得模型产生稀疏解。同时,我们还可以通过一张更明显的图示来进行说明,如图4-22所示。 最后,在实际运用过程中,还可以将两种正则化方式结合到一起,即弹性网络惩罚(Elastic-Net)[3],如式(4-25)所示
其中$\beta$是用来控制$\mathcal{l}_1$和$\mathcal{l}_2$惩罚项各自所占的比重,可以看出当$\beta=0$时式(4-25)便等价于$\mathcal{l}_2$正则化,当$\beta=1$时则等价于$\mathcal{l}_1$正则化。 在sklearn中可以分别通过导入 1. 线性回归 首先需要导入 在上述代码中,第1行是导入 上述代码运行结束后将会看到类似如下结果: 2. 逻辑回归 同上面线性回归使用方法类似,先导入 上述代码含义整体上同线性回归中的类似,这里就不再赘述。代码运行结束后将会看到类似如下结果: 在这节内容中,我们首先通过示例详细介绍了如何通过$\mathcal{l}_2$正则化方法来缓解模型的过拟合现象,以及介绍了为什么$\mathcal{l}_2$正则能够使模型变得更简单;其次介绍了加入正则化后原有梯度更新公式的变化之处,其仅仅加上了正则化项对应的梯度;然后通过一个示例来展示了$\mathcal{l}_2$正则化的效果,与此同时,还介绍了另外一种常见的$\mathcal{l}_1$正则化方法;最后还详细对比了$\mathcal{l}_1$正则化和$\mathcal{l}_2$正则化的差异之处,并就两者在sklearn中的使用示例进行了介绍。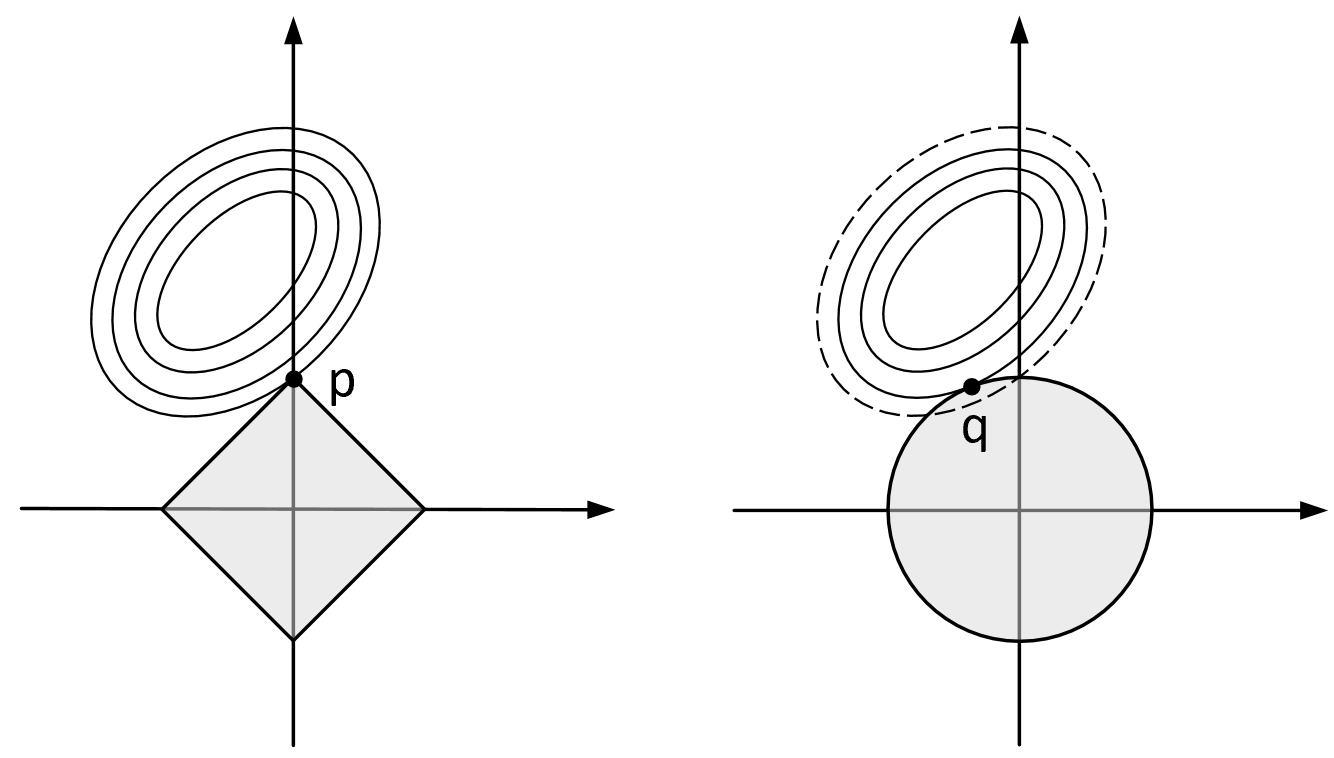
4.4.8 $\mathcal{l}_1$与$\mathcal{l}_2$正则化示例代码#
sklearn.linear_model中的SGDRegressor模块和SGDClassifier来使用支持弹性网络惩罚的线性回归和逻辑回归,下面逐一进行示例。以下完整示例代码可参见AllBooKCode/Chapter04/C17_regularized_l1_l2.pySGDRegressor并将数据集划分成训练集和测试集两个部分,进一步训练模型并预测,示例代码如下: 1 from sklearn.linear_model import SGDRegressor
2 def regression_penalty():
3 x, y = fetch_california_housing(return_X_y=True)
4 x_train, x_test, y_train, y_test = \
5 train_test_split(x, y, test_size=0.3, random_state=2020)
6 ss = StandardScaler()
7 x_train = ss.fit_transform(x_train)
8 x_test = ss.transform(x_test)
9 model = SGDRegressor(loss="squared_error",l1_ratio=0.4,
penalty='elasticnet', alpha=0.001)
10 model.fit(x_train, y_train)
11 print(model.predict(x_test)[:5])SGDRegressor模块。第3~5行是导入原始否房价预测数据,并将其划分成训练集和测试集两个部分。第6~8行是先实例化一个去均值标准化方法的实例化对象,然后对训练集进行特征标准化,最后再利用在训练集上计算得到每一列的均值、标准差对测试集进行标准化。这里需要注意的是,在对特征进行标准化时的一个重要准则就是需要将训练集和测试集分开进行标准化,且对测试集进行标准化时需要使用在训练集上计算得到的相关参数而不是重新在测试集上又计算一遍,这样做也是为了增强模型的泛化能力。第9行是实例化一个基于梯度下降算法进行优化的线性回归类对象,其中的l1_ratio便是式(4-25)中对应的$\beta$参数,penalty表示同时使用 $\mathcal{l}_1$与$\mathcal{l}_2$正则化,alpha表示整,正则化中的惩罚系数。第10~11行是先在训练集上进行训练,然后再在测试集上进行预测。1 [2.3179482 3.68416386 2.40400408 1.0202564 1.84871969]
2 [2.35 3.868 2.864 1.201 1.142]SGDClassifier模块,再训练模型并预测,示例代码如下: 1 def classification_penalty():
2 x, y = load_breast_cancer(return_X_y=True)
3 x_train, x_test, y_train, y_test = \
4 train_test_split(x, y, test_size=0.3, random_state=2020)
5 ss = StandardScaler()
6 x_train = ss.fit_transform(x_train)
7 x_test = ss.transform(x_test)
8 model = SGDClassifier(loss="log_loss",l1_ratio=0.4,
penalty='elasticnet', alpha=0.001)
9 model.fit(x_train, y_train)
10 print(model.score(x_test, y_test)) # 0.9707602339181286
11 print(model.predict(x_test)[:5])
12 print(y_test[:5])1 0.9766081871345029
2 [0 1 1 0 1]
3 [0 1 1 0 1]4.4.9 小结#