在前面几章内容中,我们陆续介绍了无监督算法中几种常见的聚类算法,包括基于Kmeans、Kmeans++、WKmeans、DBSCAN和HCA聚类算法。在接下来的这篇文章中,我们将会继续介绍无监督算法中的另外一种经典算法——主成分分析(Principal Component Analysis, PCA)算法。那什么又是PCA算法呢?
12.1 主成分分析#
在机器学习的建模过程中我们通常会遇到这样两个问题:①对于高维数据来说如何对其进行可视化?②对于包含冗余特征的数据集来说如何进行特征筛选?尽管对于第②个问题来说可以通过决策树这样的树模型来进行特征筛选,但是此时却需要样本对应的真实标签,属于有监督的学习过程。此时,通过PCA算法这两个问题便可以迎刃而解。如图12-1所示便是主成分分析算法的学习路线图,我们将先介绍其对应的思想以及sklearn的建模过程,然后再来介绍其背后的原理与求解过程,最后一步步来实现主成分分析算法。
12.1.1 PCA算法思想#
主成分分析算法的核心思想在于“主成分”3个字,通俗点讲就是通过一种合适的方法将高维度的特征转换为低维度的特征,因此主成分分析算法实质上也是一种降维算法。这里值得注意的是,我们描述的是将高维特征“转换”为低维特征,而不是从高维特征中选择部分特征来作为数据集的特征表示,这与树模型的特征选择有所不同。
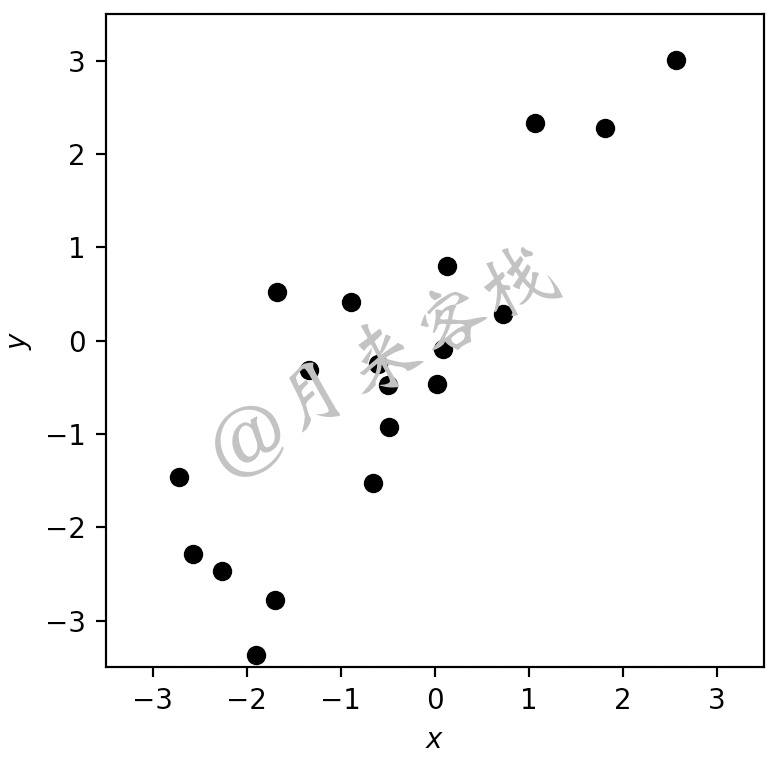
如图12-2所示,黑色原点为某数据集分布在二维平面中的场景。现在,假如只能让你用一个维度来对这些样本点进行表示,那应该是哪个维度呢?由于降维后仅剩下一个维度,因此我们可以尝试过原点做一条直线并旋转一周,然后从所有情况中选择最优的那条直线作为降维后的坐标轴,最后再将原始样本点投影到新坐标轴的投影点作为降维后的样本表示,如图12-3所示。
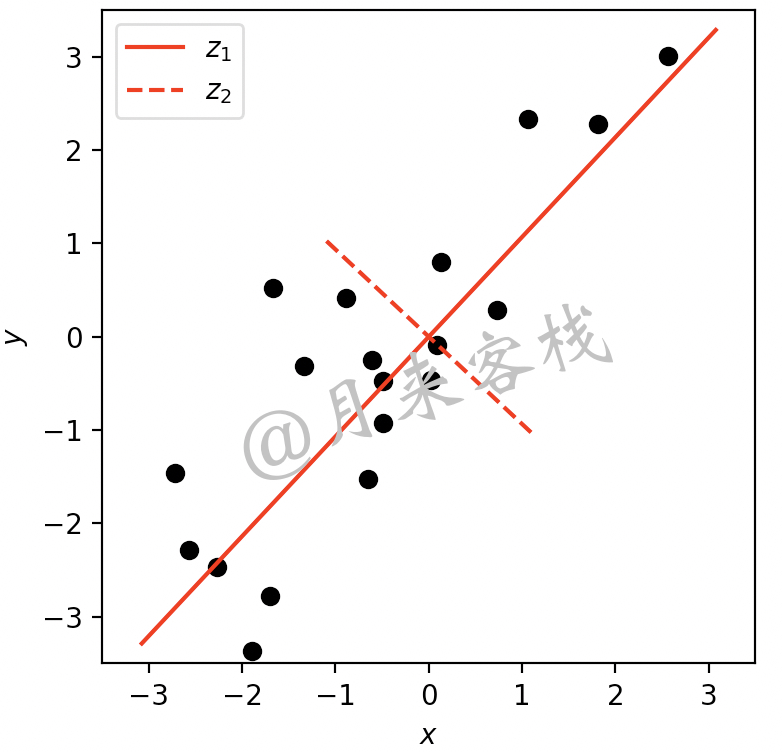
如图12-3所示,假设以$z_1$为起点顺时针旋转一周,我们便可以得到4条有代表性的投影方向,分别是$z_1,x,y,z_2$。对于这4种情况来说,相信绝大多数读者都会选择$z_1$所在的方向,不过这是为什么呢?很多读者可能会说感觉上是,我们只能说你的感觉没有错。不过真实的原因是在于降维算法的准则就是要使得降维后的特征表示能够尽可能多地保留原有数据的结构信息,直观上来看就是样本之间间距较大重叠部分较少。
例如对于图12-3所示的样本点来说,如果将其投影到$z_2$所在的方向,那么大多数样本点将会密集地聚在一起从而无法有效区分。但是,如果将这些样本点投影到$z_1$所在的方向,那么绝大多数样本在新的投影空间中依旧能够有效地进行区分。如图12-4所示便是在$z_1$方向投影后的结果。
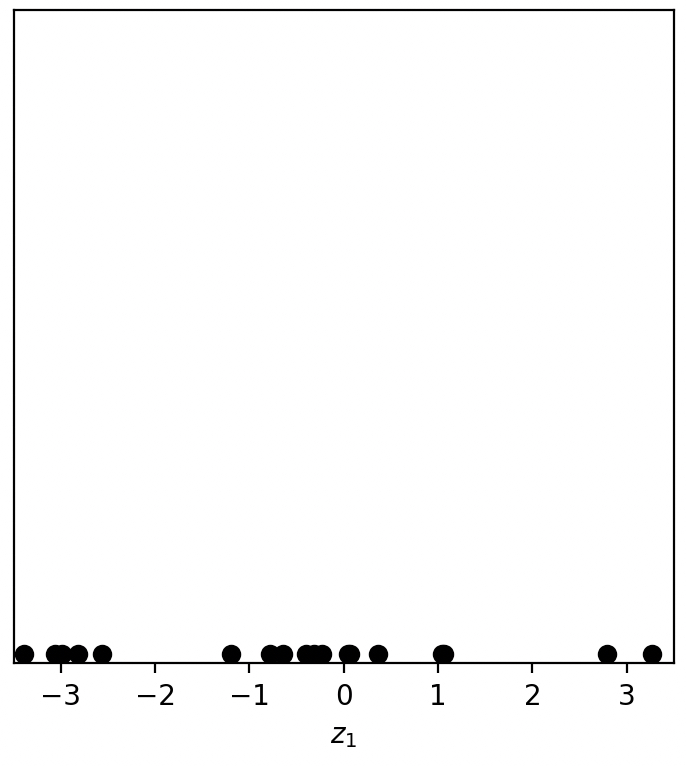
如图12-4所示,黑色圆点便是图12-3中各个样本在$z_1$方向投影后的结果。此时,我们便可以仅通过一个坐标轴来表示这些样本,从而实现了降维的目的。
进一步,如图12-5所示,如果想要对这些三维空间中的样本点进行降维处理,那么同样也要找到一个最优的投影平面然后进行投影处理。
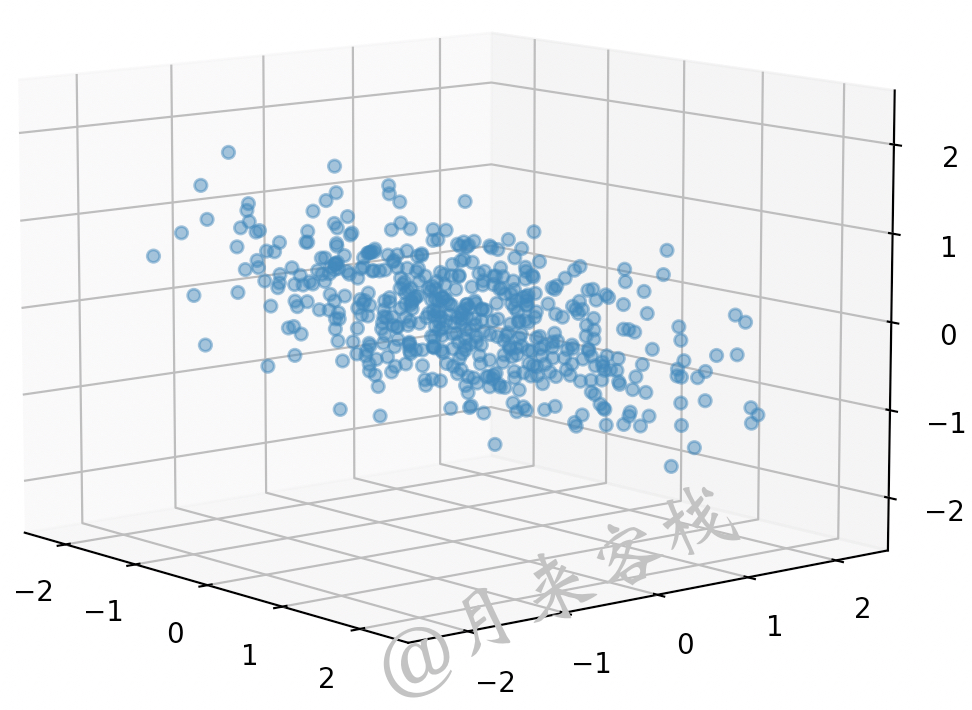
如图12-5所示,如果需要对于这些三维空间中的样本点进行降维,那么同样需要找到其对应的最优平面,如图12-6所示。
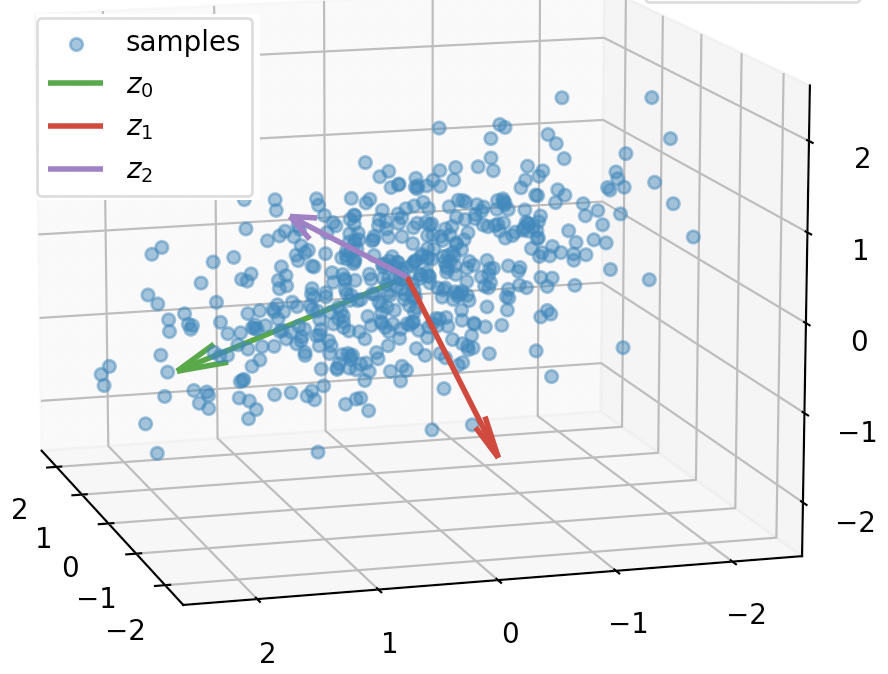
从图12-6中可以看出,只有将原始样本投影到$z_0$与$z_1$所构成的平面中才能最大程度上地保留原始样本点的结构信息,投影后的结果如图12-7所示。
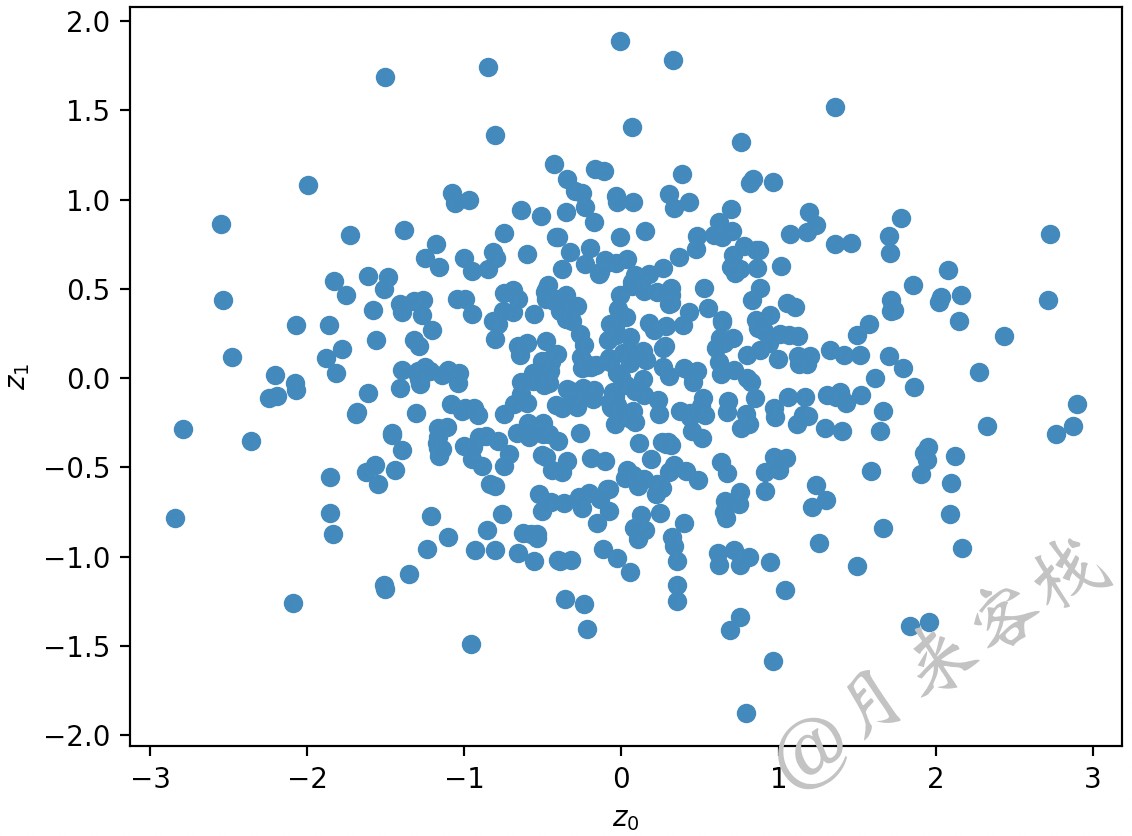
如图12-7所示便是上面三维样本点在二维平面上的投影结果。上述可视化代码可参见 AllBooKCode/Chapter12/C01_PCA_visualization.py 文件。
以上就是整个PCA降维算法的核心思想,总结起来就是对于$n$维特征数据来说,可以通过PCA算法找到其对应的$n$个主要成分,然后根据需要选择前$k$个最重要的成分,最后再将原始数据投影到由这$k$个主要成分所构成的$k$维空间中便达到了降维的目的。到此,PCA算法的核心思想就介绍完了,下面来看如何在sklearn中使用PCA模型。
12.1.2 PCA示例代码#
在sklearn中,可以通过sklearn.decomposition中的PCA模块来完成整个建模过程。下面我们以iris数据集在决策树上的分类为例,分别展示降维前和降维后分类模型的效果,完整示例代码可参见 AllBooKCode/Chapter12/C02_PCA_train.py 文件。
首先需要实现一个函数来载入数据集,并根据传入的参数来判断是否要进行降维处理,示例代码如下:
1 from sklearn.decomposition import PCA
2 from sklearn.datasets import load_iris
3 from sklearn.model_selection import train_test_split
4
5 def load_data(reduction=False, n_components=3):
6 x, y = load_iris(return_X_y=True)
7 x_train, x_test, y_train, y_test = \
8 train_test_split(x, y, test_size=0.3, random_state=2022)
9 if reduction:
10 pca = PCA(n_components)
11 x_train = pca.fit_transform(x_train)
12 x_test = pca.transform(x_test)
13 return x_train, x_test, y_train, y_test在上述代码中,第1行是导入PCA模块。第5行中n_components表示降维的维度。第6~8行是载入原始数据集,并分割成训练集和测试集。第9~12行是根据条件判断是否对数据进行降维,同时需要注意的是在训练集x_train上使用的是fit_trainsform方法(即先fit再transformer),而在测试集x_test上则是直接使用在训练集上得到的参数(投影平面)进行降维。第13行是返回训练集和测试集。
接着分别用降维前和降维后的数据集来进行分类和测试,示例代码如下:
1 def decision_tree():
2 x_train, x_test, y_train, y_test = load_data(reduction=False)
3 model = DecisionTreeClassifier()
4 model.fit(x_train, y_train)
5 acc = model.score(x_test, y_test)
6 print(f"降维前的准确率为:{acc},形状为{x_test.shape}")
7
8 x_train, x_test, y_train, y_test = load_data(reduction=True)
9 model = DecisionTreeClassifier()
10 model.fit(x_train, y_train)
11 acc = model.score(x_test, y_test)
12 print(f"降维后的准确率为:{acc},形状为{x_test.shape}")
13
14 if __name__ == '__main__':
15 decision_tree()上述代码运行后会出现类似如下的结果:
1 降维前的准确率为:0.956,形状为(45, 4)
2 降维后的准确率为:0.978,形状为(45, 3)在运行上述代码多次后可以发现,大多数情况下降维后的准确率都会好于没有降维时的准确率,这可能是因为在原始的4个特征中本来就有特征是冗余的,在决策树的建模过程中反而会影响节点的分裂方式。
12.1.3 PCA算法原理#
通过12.1.1小节内容的介绍相信各位读者对于PCA算法已经有了一个感性的认识,那么应该如何建模PCA算法并进行求解呢?根据PCA算法的思想可知,为了能使得降维后样本点之间的间距尽可能大,那么在降维时就应该选择前$k$个方差较大的维度作为主成分进行投影。同时,为了方便后续推导,需要先对原始特征维度进行去均值的标准化处理,使得每个维度的均值为0。
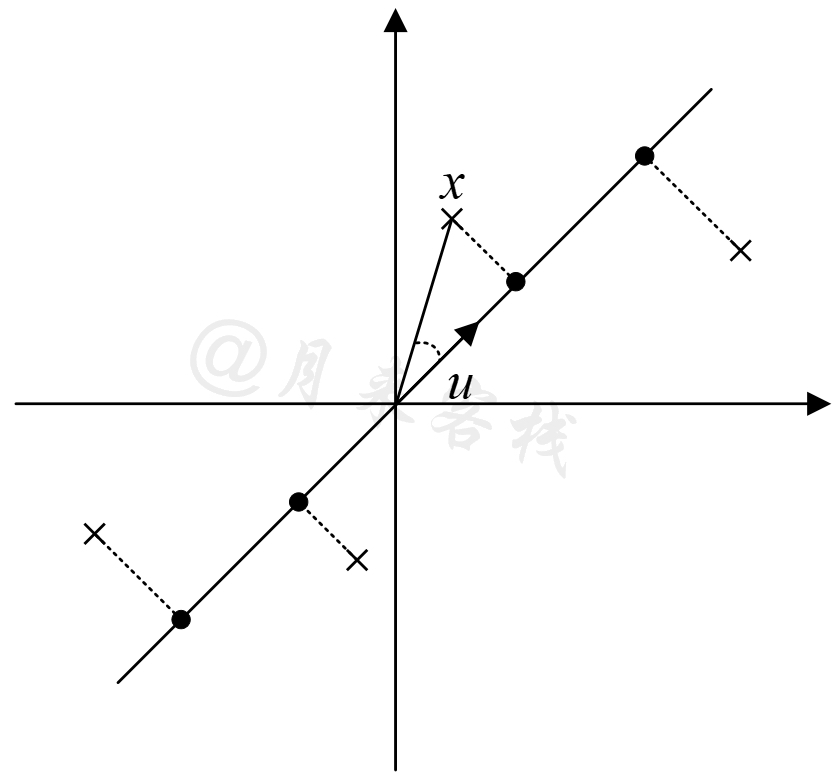
如图12-8所示,在二维平面上“十”字形为原始样本点,圆点为原始样本降维后的投影点,$u$为投影方向所在的单位方向向量,原始样本与投影方向的夹角为$\theta$。此时,对于任意原始样本点$x$来说,其投影点到原点的距离为
$$ d=cos\theta\cdot\|x\|=\frac{x^Tu}{\|x\|\cdot\|u\|}\|x\|=x^Tu\tag{12-1} $$注:$x$和$u$均为列向量。
进一步,为了使得降维后所有投影点的整体方差最大,则只需要最大化式(12-2)即可
$$ \begin{aligned} \frac{1}{m}\sum_{i=1}^m\left(x^{(i)^T}u\right)^2=\frac{1}{m}\sum_{i=1}^mu^Tx^{(i)}x^{(i)^T}u =u^T\left(\frac{1}{m}\sum_{i=1}^mx^{(i)}x^{(i)^T}\right)u \end{aligned} \tag{12-2} $$其中$x^{(i)}$表示第$i$个样本,$m$表示样本总数。
同理,对于三维空间中的样本点来说,其投影后的结果如图12-9所示。
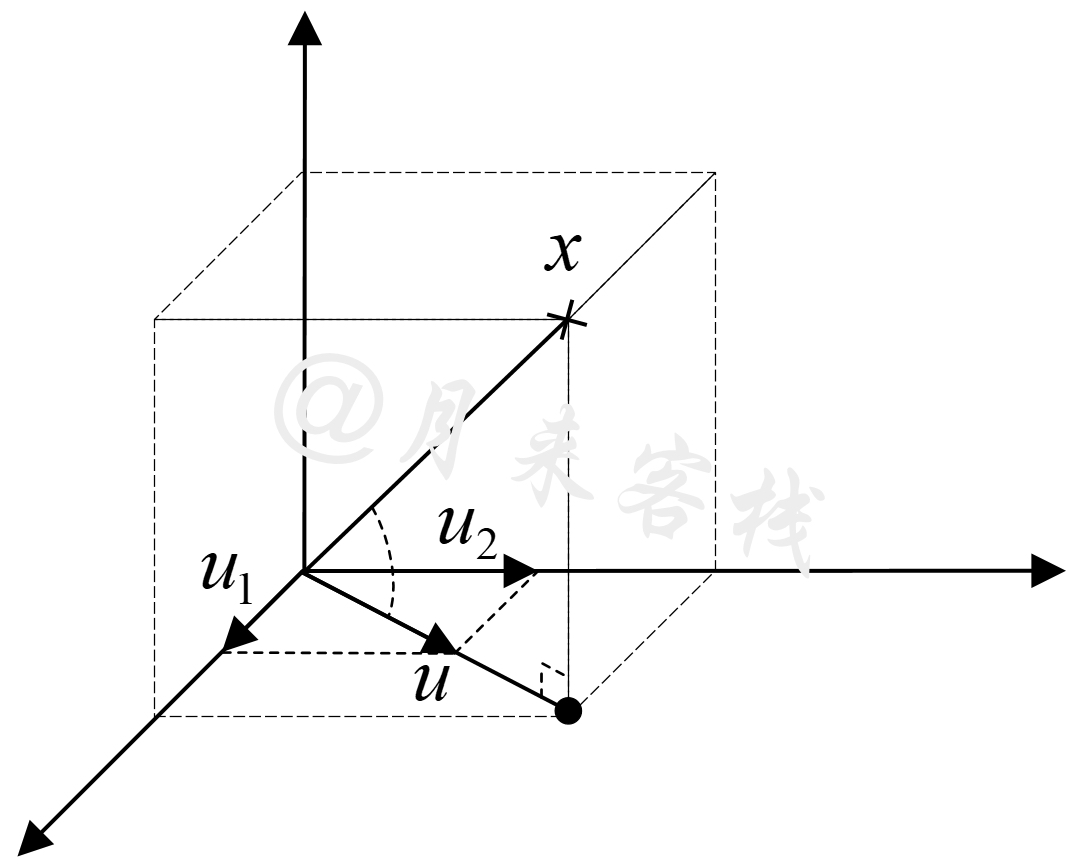
如图12-9所示,在三维空间空“十”字形表示原始样本点,黑色圆点表示降维后的投影点,$u_1,u_2$为构成投影平面的一组正交单位向量,$u$为原点指向投影点的方向向量,原始样本与投影面的夹角为$\theta$。此时,对于任意原始样本点$x$来说,其投影点到原点的距离为
$$ d=cos\theta\cdot\|x\|=\frac{x^Tu}{\|x\|\cdot\|u\|}\|x\|=x^T\frac{u}{\|u\|}\tag{12-3} $$因为$u=\beta_1u_1+\beta_2u_2$,所以有
$$ d=x^T\frac{(\beta_1u_1+\beta_2u_2)}{\|\beta_1u_1+\beta_2u_2\|}=\frac{\beta_1}{\|\beta_1u_1+\beta_2u_2\|}x^Tu_1+\frac{\beta_2}{\|\beta_1u_1+\beta_2u_2\|}x^Tu_2\tag{12-4} $$进一步,为了使得降维后所有投影点的整体方差最大,则只需要最大化式(12-5)即可
12.1.4 PCA算法投影示例#
假如,现在某数据集已经求解得到了对应的$k$个主要成分,那应该怎么完成降维呢?换句话说应该如何将原始的样本点投影到新的低维空间中呢?我们知道在平面直角坐标系中通常会选择$i=(1,0)^T,j=(0,1)^T$这两个正交单位向量作为基向量来对平面中的所有点进行表示,如图12-10所示。
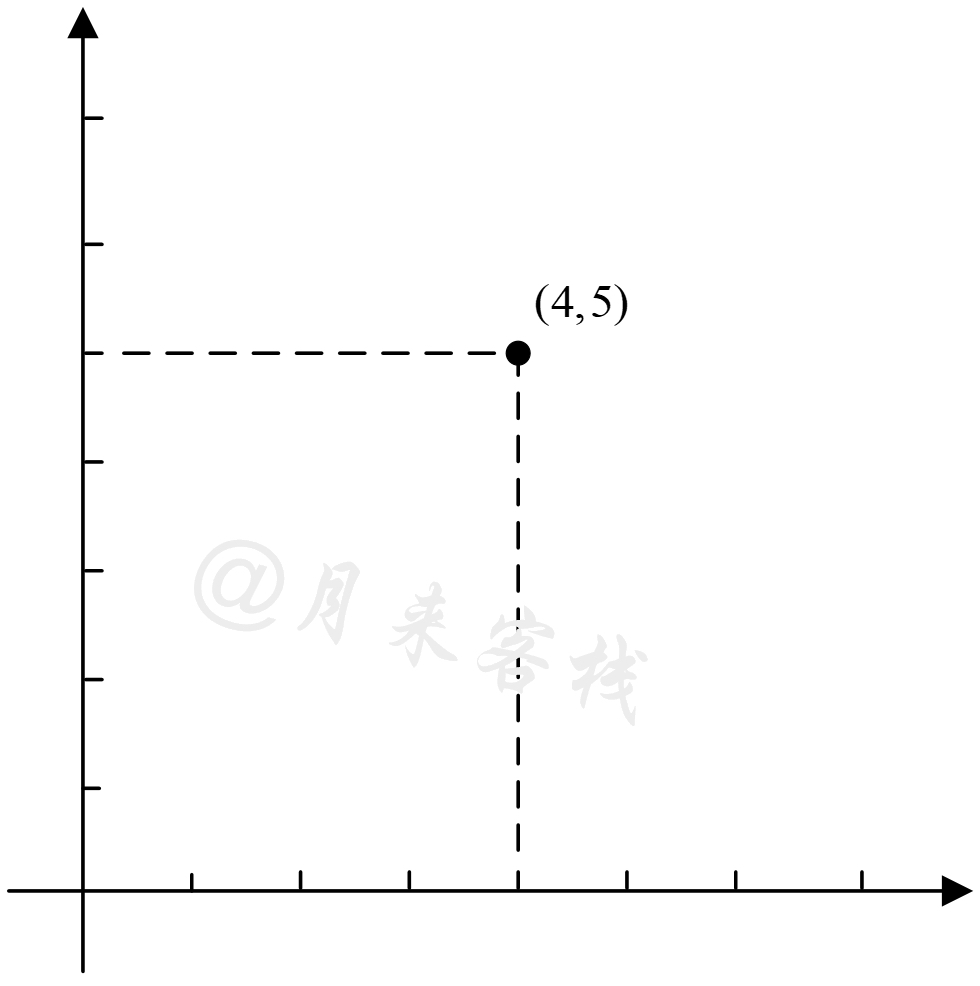
在图12-10中,向量$x=(5,6)^T$的含义便是在方向$i$上移动$i^T\cdot x=5$个单位,在方向$j$上移动$j^T\cdot x=6$个单位。不过这样可能感观并不明显,下面旋转一下坐标系。
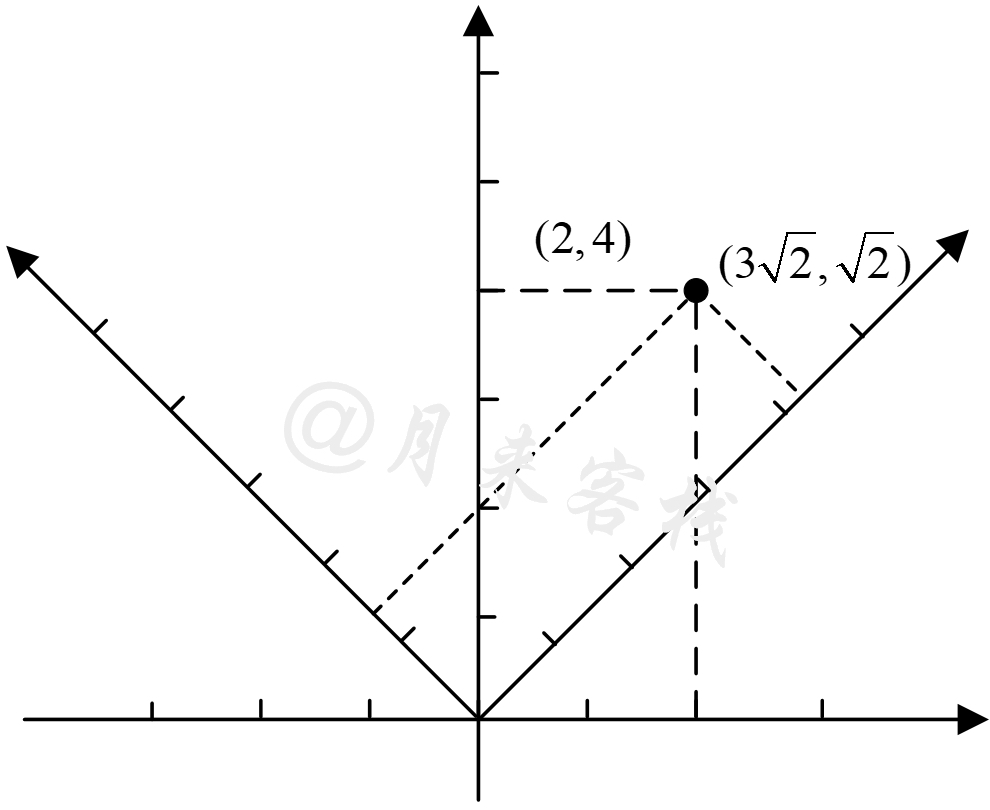
如图12-11所示,此时选取$\hat{i}=(\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})^T,\hat{j}=(-\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})^T$来作为基向量,那么$i,j$坐标系中的样本点$x=(2,4)^T$在$\hat{i},\hat{j}$所表示的坐标系中是多少呢?答案便是:先在$\hat{i}$方向移动$\hat{i}^T\cdot x=3\sqrt{2}$的长度;然后在$\hat{j}$方向移动$\hat{j}^T\cdot x=\sqrt{2}$的长度。所以,在新的坐标系下样本点$x$的坐标为
$$ \begin{bmatrix} \hat{i}^T\\\hat{j}^T \end{bmatrix}\cdot x=\begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ \end{bmatrix} \cdot\begin{bmatrix} 2\\4 \end{bmatrix}=\begin{bmatrix} 3\sqrt{2}\\\sqrt{2} \end{bmatrix}\tag{12-7} $$所以在PCA中,降维(更换坐标系)之后的新坐标计算公式为
$$ y^{(i)}=\begin{bmatrix} u^T_1x^{(i)}\\u^T_2x^{(i)}\\u^T_3x^{(i)}\\\vdots\\u^T_kx^{(i)}\end{bmatrix}\;\tag{12-8} $$其中$u_1,u_2,...,u_k$是表示前$k$个主要成分的列向量,$x^{(i)}$表示原始第$i$个样本的表示,$y^{(i)}$表示样本$i$降维后的表示。
12.1.5 PCA算法求解#
在介绍完PCA算法的思想及原理后接下来我们继续来看目标函数的求解过程。根据12.1.3节内容可知,在$n$维空间可以通过最大化投影点与原点的方差来求得最佳的投影维度,即
$$ \begin{aligned} \frac{1}{m}\sum_{i=1}^m\left(x^{(i)^T}u\right)^2=\frac{1}{m}\sum_{i=1}^mu^Tx^{(i)}x^{(i)^T}u =u^T\left(\frac{1}{m}\sum_{i=1}^mx^{(i)}x^{(i)^T}\right)u \end{aligned} \tag{12-9} $$其中$u$为单位向量。
进一步,根据式(12-9)可以构造得到如下拉格朗日函数
$$ \begin{aligned} \mathcal{L} &= u^T\left( \frac{1}{m}\sum_{i=1}^mx^{(i)}x^{(i)^T}\right)u-\lambda(u^Tu-1) \end{aligned}\tag{12-10} $$对$u$求偏导并令其为$0$有
$$ \begin{aligned} \frac{\partial\mathcal{L}}{\partial u}&=u^T\frac{1}{m}\sum_{i=1}^mx^{(i)}x^{(i)^T}-\lambda u^T=0\\[2ex] u^T \Sigma&=\lambda u^T \\[2ex] (u^T\Sigma)^T&=(\lambda u^T)^T\\[2ex] \Sigma u &= \lambda u \end{aligned}\tag{12-11} $$其中$\Sigma=\frac{1}{m}\sum_{i=1}^mx^{(i)}x^{(i)^T}$是一个对称矩阵,也称之为协方差矩阵(Covariance Matrix)。
最终,可以求得满足等式(12-11)的解为$\Sigma$对应的$m$个特征向量$(u_1,u_2,...,u_m)$和$\Sigma$对应的$m$个特征值$(\lambda_1,\lambda_2,...,\lambda_m)$,其中$(m\leq n)$。
进一步,又因为投影点到原点的距离为$u^T\Sigma u=u^T\lambda u=\lambda u^Tu=\lambda$,所以上述解中$\lambda_i$越大,其对应特征向量作为投影维度时投影点到原点的方差便越大。此时可以得出一个重要的结论便是,对于原始$n$维样本空间来说其必定存在$k$个相互正交(在实对称矩阵中不同特征值对应的特征向量正交)的特征向量,且特征值最大的特征向量便是使得投影点与原点方差最大的投影维度。
所以,对于高维空间中的样本点来说,根据上述步骤便可以求得最佳的投影维度。但是通常我们并不会将高维空间中的样本直接投影到一个维度上,而是寻找对应的低维空间进行投影。因此可以选择前$k$个最大的特征值对应的特征向量来作为投影平面进行投影,因为此时所有投影点与原点之间的方差最大。
假设某数据集有$n$个特征维度,$u_1,u_2,...,u_s$是根据上述步骤求得的$s(s\leq n)$个单位特征向量,$(\lambda_1,\lambda_2,...,\lambda_s)$为对应的特征值,现需要将其降维到 $k (k\leq s)$维空间中。根据式(12-1)可知,此时对于任意样本点$x$来说,其投影点到原点的距离为
$$ d=cos\theta\cdot\|x\|=\frac{x^Tu}{\|x\|\cdot\|u\|}|x|=x^T\frac{u}{\|u\|}\tag{12-12} $$其中$u$为原点指向投影点的方向向量,且 $u$ 可以表示为$u=\beta_1u_1+\beta_2u_2+...+\beta_ku_k$,因此式(12-12)可进一步写为
$$ d=x^T\frac{(\beta_1u_1+...+\beta_ku_k)}{\|\beta_1u_1+...+\beta_ku_k\|}=\frac{\beta_1}{\|\beta_1u_1+...+\beta_ku_k\|}x^Tu_1+...+\frac{\beta_k}{\|\beta_1u_1+...+\beta_ku_k\|}x^Tu_k\tag{12-13} $$