4.6 RAG 中的两阶段索引#
在第4.4节内容中,我们详细介绍了如何基于在第3章中构建的语义检索引擎来搭建一个完整的 RAG Agent,让它根据用户的提问自主分拆解、回答并总结得到完整的答案。尽管整个流程看似已经搭建完毕,但是依旧有很多地方需要继续优化,例如从向量库检索内容的精度、模型输出结果的后处理等。在本节内容中,我们将从检索精度这一角度来介绍如何让 RAG Agent 在回答问题时检索到的参考内容更精准,也就是重排序(Rerank)模型的使用。
很多人第一次搭建 RAG 系统时,都会有一个疑问,既然 Embedding 模型能把文本变成向量,为什么还要再加一个 Rerank 模型?刚开始你可能觉得有它没它区别应该不大,但真正用过之后你会发现加了 Rerank 模型后检索结果可能有质的飞跃,而这背后涉及到的就是 RAG 检索架构中一个非常核心的设计。
4.6.1 双塔结构思想原理#
双塔结构(Bi-Encoder)是 RAG 系统中最常用的检索架构,也是几乎所有向量数据库的底层基础。双塔的核心思想可以用一句话概括:Query 和 Doc 分开编码,最后在向量空间中计算相似度,如图4-8所示。
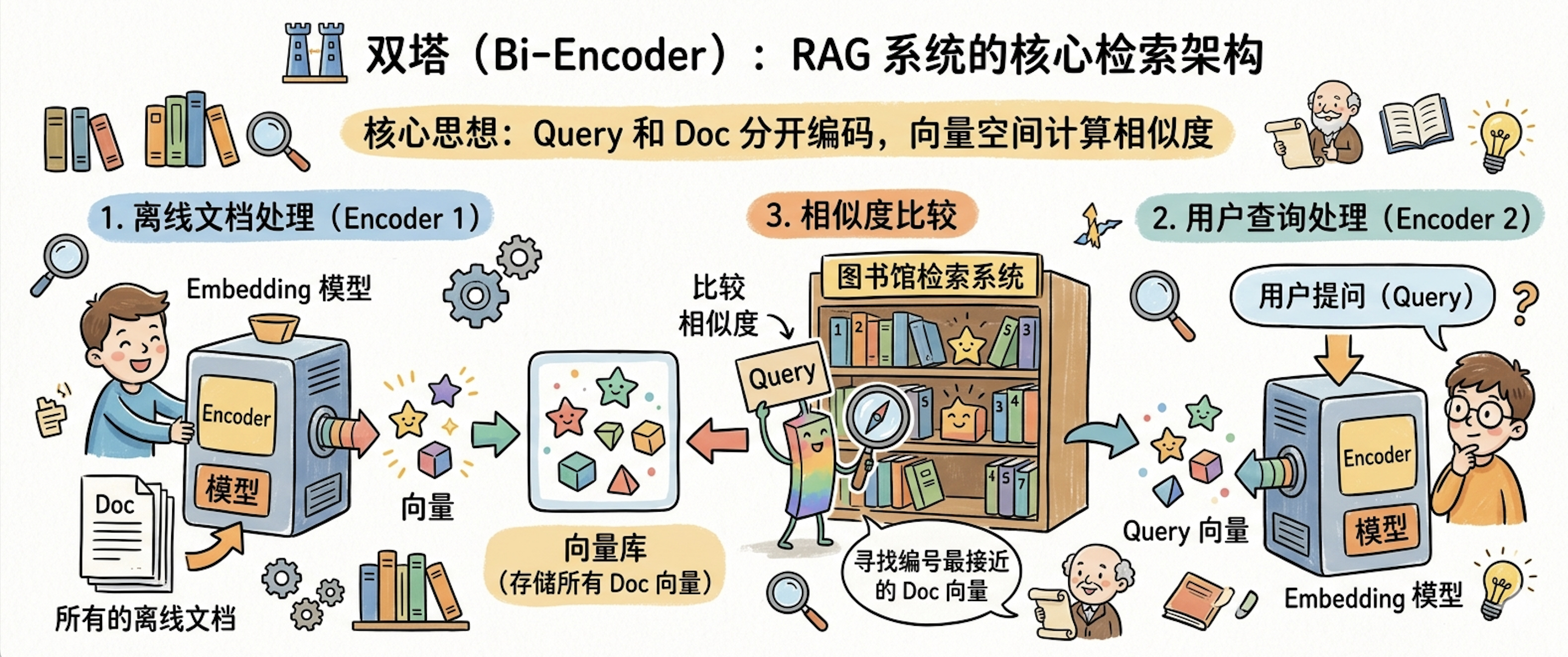
例如,在 RAG 应用开发中,我们会先通过 Embedding 模型(也就是 Encoder)将所有的离线文档都转换成向量存入到向量库中。当用户提问时,我们再将 Query 通过 Embedding 模型将其转换成向量,然后同向量库中的向量进行相似度比较,最后取向量库中前 K 个最相似的文本块作为参考源。你可以把整个过程想象成图书馆的图书检索系统,每本书都有一个编号(向量),读者查询时先拿到查询词的编号,然后在书架上找编号最接近的书。
4.6.2 双塔结构的优势与不足#
说完了工作原理,我们自然要问:为什么双塔结构能支撑百万级甚至更大规模的数据检索?
这得益于它的一个关键设计:文档向量可以提前离线计算好并存入向量数据库,查询时只需计算一次 Query 向量,然后在向量索引中做近似最近邻搜索(Approximate Nearest Neighbor, ANN)。这意味着时间复杂度可以从线性的 $O(N)$ 降低到接近 $O(log N)$,例如简单的倒排文件索引(Inverted File Index, IVF)。
举个例子,如果你有 100 万篇文档,使用双塔结构时系统可以在对数级别的时间内找到最相关的文档,而不用逐一比较 100 万次。这也是为什么 RAG 系统能够秒级响应,而不是等待几分钟。
不过,双塔结构也有明显的局限性,这也是为什么它不能单独使用的原因。
由于 Query 和 Doc 在编码时彼此不知道对方的存在,模型只能把整段文本压缩成一个固定长度的向量,然而,一旦压缩完成细粒度的匹配信息就会丢失。换句话说,我们希望在编码 Query 的时候它是能够看到 Doc 的,这样检索得到的参考内容也将更加准确。
举个例子,假设你的知识库中有一篇文档讲的是苹果公司 2024 年的财报数据,当用户搜索“苹果营收”时,双塔结构可能会把这篇文档排在后面,因为它在编码“苹果营收”时无法捕捉到“苹果”和“苹果公司”的细粒度对应关系,它只能基于整体语义的粗略匹配。
所以你会发现,只用双塔检索时,结果往往是看起来相关,但不够精准。
4.6.3 单塔结构思想原理#
说完了双塔结构,我们再来看单塔结构是怎么解决精度问题的。
单塔(Cross-Encoder)是另一种常见的架构,通常用于排序场景中,它的做法与双塔完全不同。双塔是分开编码,而单塔则是将 Query 和 Doc 拼接在一起输入模型进行联合编码。
具体来说,我们会把 Query 和 Doc 的文本拼接成一个序列,例如 [CLS] Query [SEP] Doc,然后再通过 Embedding 模型对整个序列进行编码并输出一个0 到1之间相关性分数,最后取相关性分数最高的前 K 的文本块作为参考源,整个过程如图4-9所示。
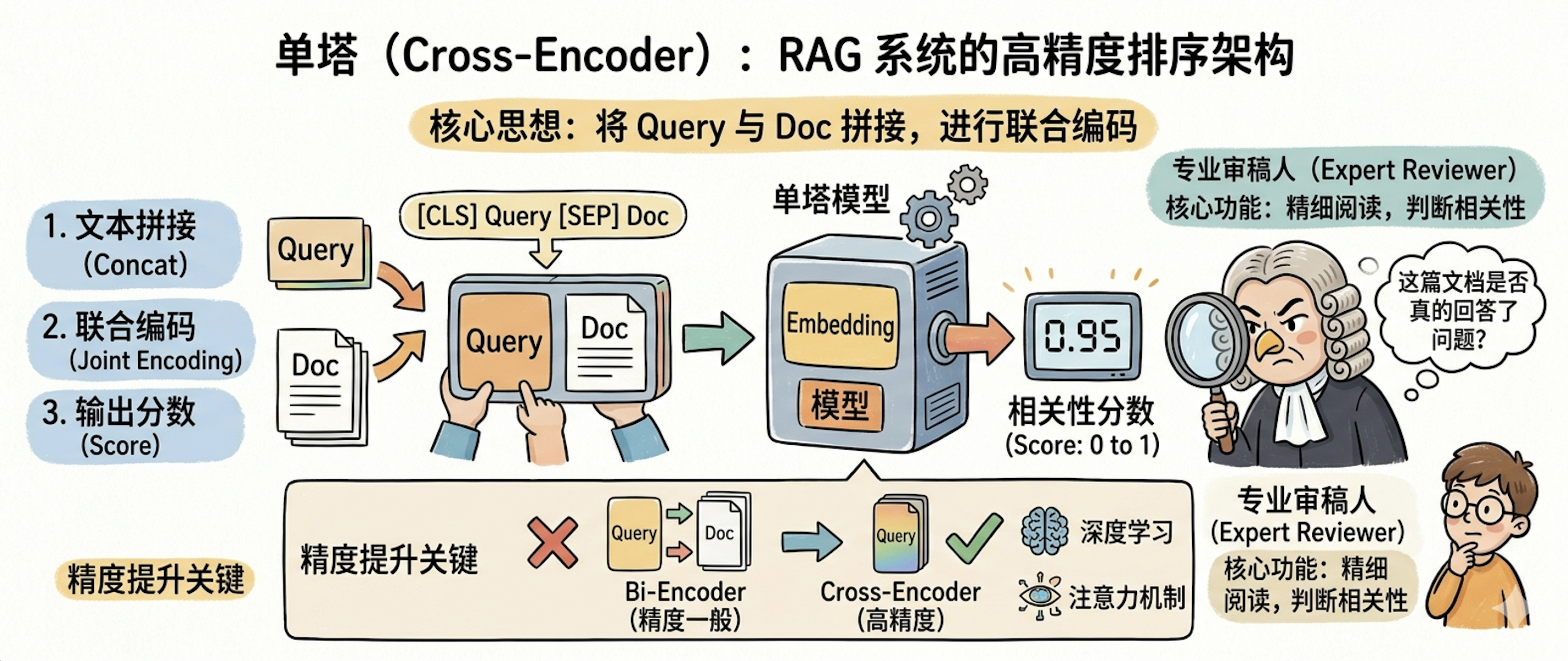
此时,我们可以把单塔理解成一个专业的审稿人,它会仔细阅读问题和文档的每一个字,然后判断这篇文档是否真的回答了问题。
4.6.4 单塔结构的优势与不足#
可以发现,单塔结构最大的优势在于表达能力强,能够捕捉细粒度的语义匹配。在 Cross-Encoder 中,Query 里的每个 token 都可以关注 Doc 的每个 token,也就是完整的交叉注意力机制。因此,这意味着模型可以进行精确的语义对齐以及上下文补全和逻辑关系的判断。
还是刚才的例子,当用户搜索“苹果营收”,文档中写的是“Apple Inc.的年收入”时,单塔模型则能够理解“苹果”和“Apple Inc.”是同一个实体,“营收”和“年收入”是同一个概念,从而给出更高的相关性分数。而双塔结构由于是分开编码,所以很难捕捉到这种细粒度的语义对应。
然而,单塔结构也有一个致命问题,这导致它无法单独用于大规模检索。
这个问题就是计算成本过高,不可扩展。
假设有 100 万文档,如果用 Cross-Encoder,必须对每一个文档都跑一次完整的 Transformer 前向传播,这意味着100 万次计算,在工程上几乎不可用。
想象一下,每次用户发起查询,你都要让模型跑 100 万次,即使用上最好的 GPU,响应时间也会达到秒级甚至分钟级,这在实际应用中是完全无法接受的。
4.6.5 双塔单塔两阶段索引#
说到这里,答案已经很明显了:双塔和单塔各有所长,也各有所短。那双塔能解决规模问题但精度不够,单塔能解决精度问题但规模不行,该怎么办?
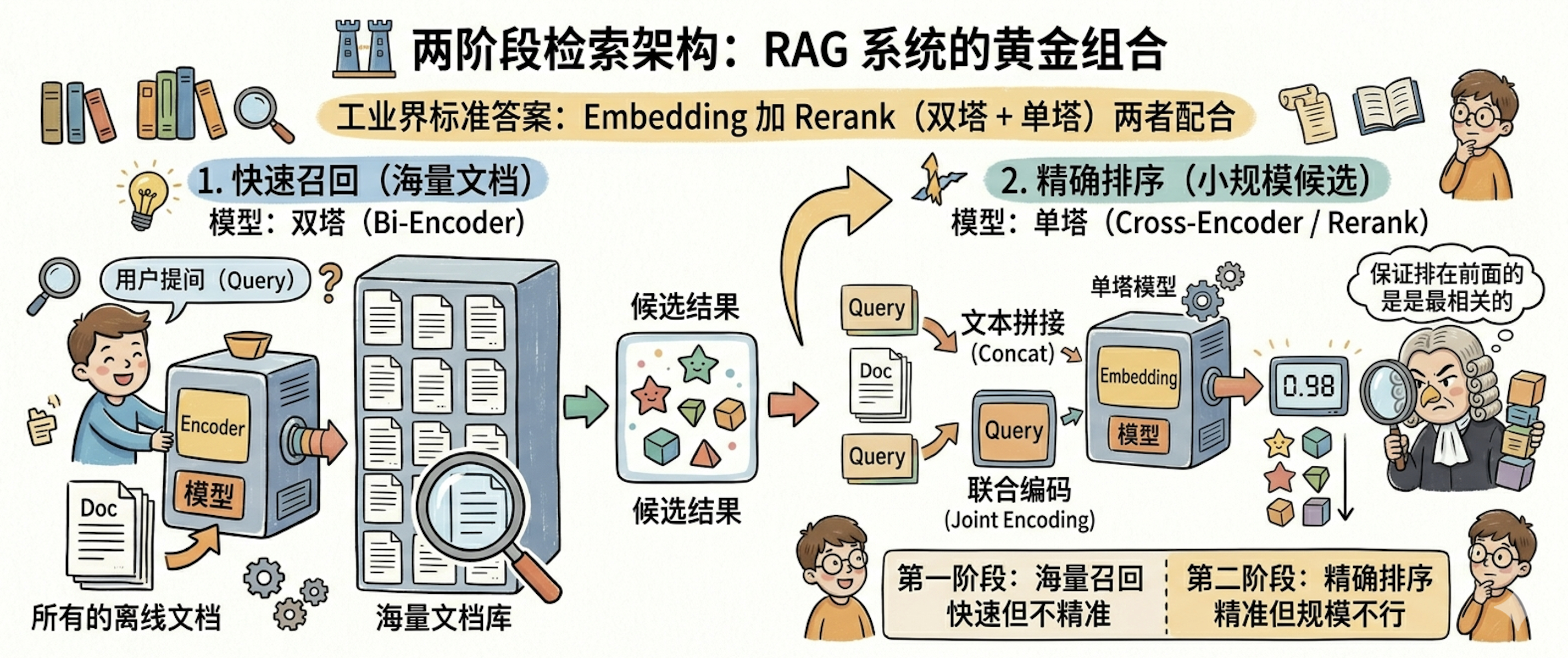
工业界的标准答案是:两者配合,采用两阶段检索架构。这就是为什么你总会看到 Embedding 加 Rerank的组合,本质就是双塔加单塔。
整体来看,第一阶段的 Embedding 模型(双塔)负责从海量文档中快速召回一批候选结果,保证不漏掉相关内容;第二阶段的 Rerank 模型(单塔)负责对这批候选进行精确排序,保证排在前面的真的是最相关的。
可以发现,这种设计思路和传统搜索引擎几乎一模一样:先用倒排索引快速召回一批候选网页,然后再用 PageRank 等算法进行精排,最后返回精排后靠前的结果。
例如,第一阶段双塔召回,从 100 万文档中快速筛选出 Top 50 候选,目标是保证召回率并控制计算成本;第二阶段,单塔精排,对 Top 50 候选进行精确排序,输出 Top 5 最终结果,目标是提升排序精度并修正语义偏差。
所以双塔-单塔这种架构既兼顾了效率又保证了精度,既能秒级响应,又能保证结果质量。 因此,高质量 RAG 系统几乎都包含 Embedding 模型和 Reranking 模型,两者缺一不可。
4.6.6 两阶段索引扩展#
除了上面“先粗排再精排”的两阶段索引以外,在知识库文档数量多、章节结构清晰(如教材、技术手册、法律法规)等场景中还有另外一种两阶段索的方式,其核心思想依旧是“先粗排再精排”只是考虑的角度不一样,整体概括就是先在章节层面做粗召回,然后在章节内容做精召回。
第1步:章节级粗召回。将用户的提问在章节级别做相似度搜索,找出与之最相关的前 N 个章节。这一步的目的不是为了找到最终答案,而是快速确定答案最可能藏在哪几个章节里,把搜索范围从全库收窄到若干个章节。
第2步:章节内精召回。在第1步选出的章节中,对向量块做相似度搜索,找出最终的前 K 个文本块。由于搜索范围已经被限定在语义相关的章节内,噪声大幅减少,检索结果的准确性也会随之提升。当然,如果有必要在这一步中还可以使用上面的双塔结构来做重排序。
此时可以看出,在构建上述两步的过程中一共需要建立两个向量库,并且在构建章节级向量库时可以只使用章节的标题和首段摘内容,在构建章节内向量库时使用之前介绍的方法即可。
4.6.7 总结#
到此,对于两阶段索引的基本原理就介绍完了。总结起来就是,双塔解决的是如何在海量数据中快速找到可能相关的内容,而单塔解决的是这些候选内容里哪一个真的回答了问题。一句话,双塔负责规模,单塔负责精度;双塔保证能找到,单塔保证找得对。
在下一小节中,我们将介绍如何使用 Qwen3 Reranking 模型的基本原理及用法示例。