7.5 高斯朴素贝叶斯原理与实现#
在前面两节内容中,我们分别介绍了基于类别特征的Categorical朴素贝叶斯算法和基于特征权重的Multinomial朴素贝叶斯算法,而两者之间的唯一区别就体现在对条件概率的处理上。在接下来的这节内容中,我们将会介绍第3种基于朴素贝叶斯思想的极大化后验概率模型——高斯朴素贝叶斯(Gaussian Naive Bayes, GNB)。
7.5.1 算法思想#
根据Categorical贝叶斯和Multinomial贝叶斯算法的原理可知,前者只能用于处理类别型取值的特征变量,而后者的初衷也是为了处理包含词频的文本向量表示(尽管从结果上看也适用于类似TFIDF这样的连续型特征)。所谓高斯贝叶斯是指假定样本每个特征维度的条件概率均服从高斯分布,进而再根据贝叶斯公式来计算得到新样本在某个特征分布下其属于各个类别的后验概率,最后通过极大化后验概率来确定样本的所属类别。
7.5.2 算法原理#
高斯贝叶斯算法假定数据样本在各个类别下,每个特征变量$X^{(i)}$的条件概率均服从高斯分布,即
$$ P(X^{(i)}|Y=c_k)=\frac{1}{\sqrt{2\pi \sigma^2_{c_ki}}}\exp\left(-\frac{(X^{(i)}-\mu_{c_ki})^2}{2\sigma^2_{c_ki}}\right)\tag{7-36} $$其中$X^{(i)}$表示第$i$个特征维度,$\sigma_{c_ki}$和$\mu_{c_ki}$分别表示在类别$Y=c_k$下特征$X^{(i)}$对应的标准差和期望。
在计算得到每个特征维度的条件概率后,再进行极大化后验概率计算
$$ \begin{aligned} \hat{y} &= \arg\max_{c_k} \log{\left(P(Y=c_k) \prod_{i=0}^{n}P(X^{(i)} \mid P(Y=c_k)\right)}\\[2ex] &=\arg\max_{c_k} \log{\left[P(Y=c_k) \prod_{i=0}^{n}\frac{1}{\sqrt{2\pi \sigma^2_{c_ki}}}\exp\left(-\frac{(X^{(i)}-\mu_{c_ki})^2}{2\sigma^2_{c_ki}}\right)\right]}\\[2ex] &\Longrightarrow \arg\max_{c_k} \left[\log P(Y=c_k)+\sum_{i=0}^n\log{\left(\frac{1}{\sqrt{2\pi \sigma^2_{c_ki}}}\exp\left(-\frac{(X^{(i)}-\mu_{c_ki})^2}{2\sigma^2_{c_ki}}\right)\right)}\right]\\[2ex] &=\arg\max_{c_k}\left(\log P(Y=c_k)-\frac{1}{2}\sum_{i=0}^n\log{2\pi\sigma^2_{c_ki}-\frac{1}{2}\sum_{i=0}^n\frac{(X^{(i)}-\mu_{c_ki})^2}{\sigma^2_{c_ki}}}\right) \end{aligned}\tag{7-37} $$这里需要注意的是,同上一节介绍的多项式朴素贝叶斯一样,在后验概率计算过程中同样进行取对数操作。
7.5.3 计算示例#
假设现在有一个基于TFIDF方法表示文本数据,其一共包含有$X^{(1)},X^{(2)},X^{(3)}$ 这3个特征维度,每个维度表示词表中相应词的TFIDF权重,$Y$表示样本对应的所属类别,如表7-3所示。现需要预测$x=[0.5,0.12,0.218]$这个样本的所属类别。
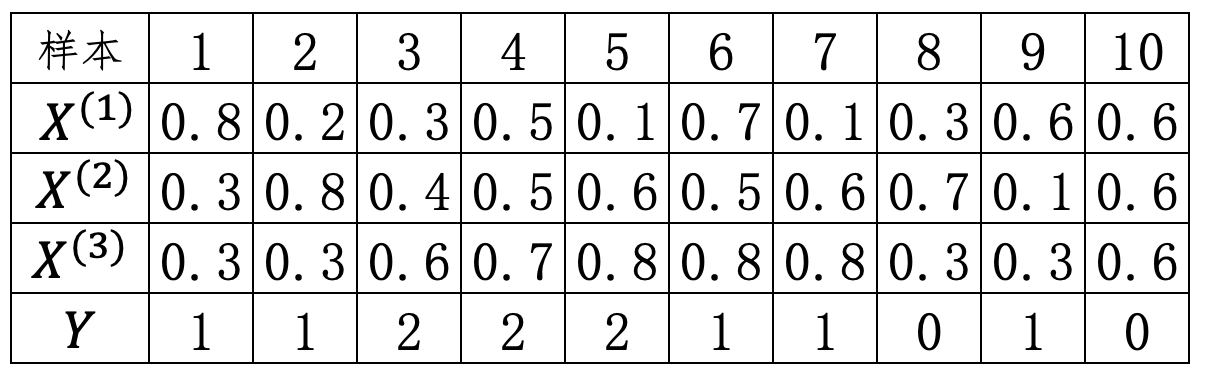
由表7-3易知,各个类别的先验概率为
$$ \begin{aligned} \log P(Y=0)&=\log(\frac{2}{10})\approx-1.609\\[1ex] \log P(Y=1)&=\log(\frac{5}{10})\approx -0.693\\[1ex] \log P(Y=2)&=\log(\frac{3}{10})\approx-1.204 \end{aligned}\tag{7-38} $$根据表7-3可知,当$Y=0$时特征$X^{(1)}$对应的参数期望和方差为
$$ \begin{aligned} \mu_{00} & = \frac{0.3+0.6}{2}=0.45\\[2ex] \sigma^2_{00}&=\frac{(0.3-0.45)^2+(0.6-0.45)^2}{2}=0.0225 \end{aligned}\tag{7-39} $$同理可得
$$ \mu= \begin{bmatrix} 0.45 & 0.65 & 0.45\\ 0.48 & 0.46 & 0.5 \\ 0.3&0.5&0.7\\ \end{bmatrix}\;\;\;\; \sigma^2= \begin{bmatrix} 0.0225 & 0.0025 & 0.0225\\ 0.0776 & 0.0584 & 0.06 \\ 0.0267&0.0067&0.0067\\ \end{bmatrix}\tag{7-40} $$其中$\mu_{c_ki}$表示类别$c_k$下的第$i$个特征对应的期望,$\sigma ^2_{c_ki}$表示类别$c_k$下第$i$个特征对应的方差。