5.2 K近邻原理#
5.2.1 算法原理#
如图5-2所示,黑色样本点为原始的训练数据,并且包含了0、1、2这3个类别(分别为图中不同形状的样本点)。现在得到一个新的样本点(图中黑色倒三角),需要对其所属类别进行分类,那K近邻是如何对其进行分类的呢?
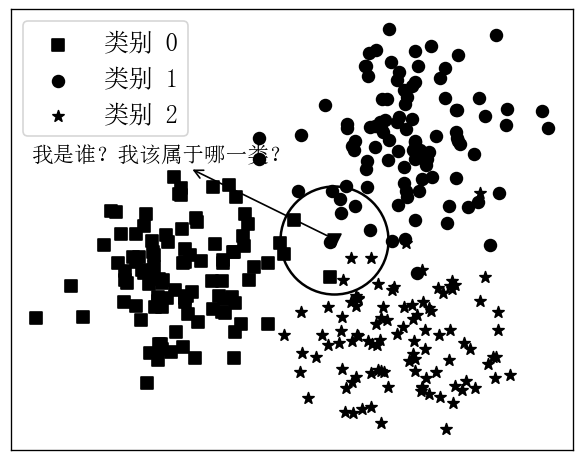
首先K近邻会确定一个K值,然后选择离自己(黑色倒三角样本点)最近的K个样本点,最后根据投票的规则(Majority Voting Rule)确定新样本所属的类别。如图5-2所示,示例中选择了离三角形样本点最近的14个样本点(正方形4个、圆形7个、星形3个),并且在图中离三角形样本点最近的14个样本中最多的为圆形样本,所以K近邻算法将把新样本归类为类别1。因此,对于K近邻算法的原理可以总结为如下3个步骤:
1. 确定一个K值
用于选择离自己(三角形样本点)最近的样本数。
2. 选择一种度量距离
用来计算并得到离自己最近的K个样本,示例中采用了应用最为广泛的欧氏距离。
3. 确定一种决策规则
用来判定新样本所属类别,示例中采用了基于投票的分类规则。
可以看出,K近邻分类的3个步骤其实对应了3个超参数的选择,但是,通常来讲,对于决策规则的选择基本上都采用了基于投票的决策规则,因此下面对于这个问题也就不再进行额外讨论。
5.2.2 K值选择#
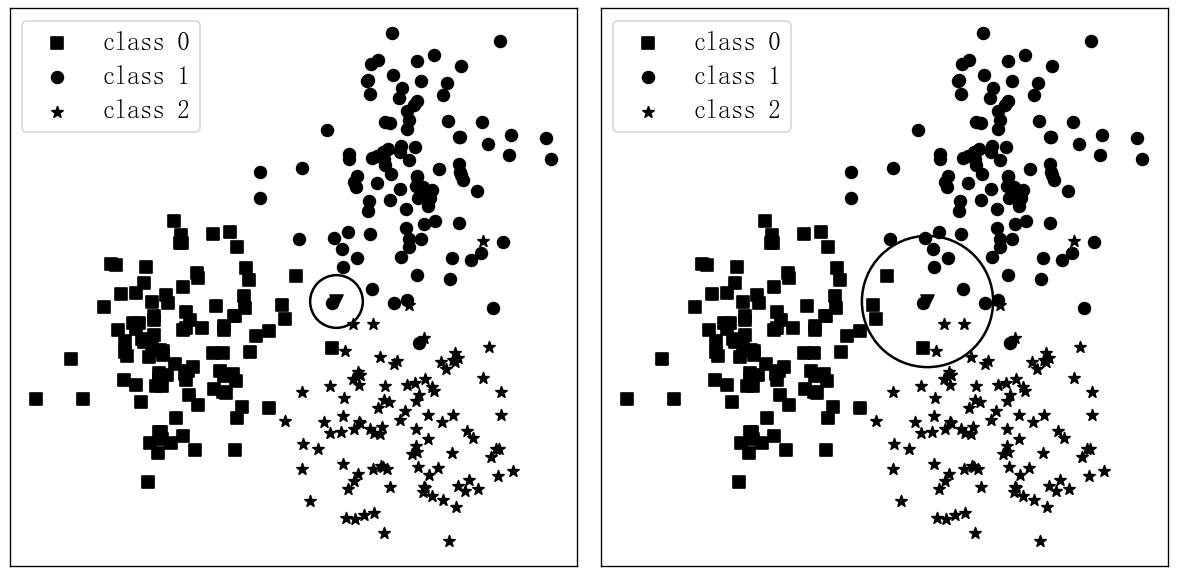
K值的选择会极大程度上影响K近邻的分类结果。如图5-3所示,可以想象,如果在分类过程中选择较小的K值,则会使模型的训练误差减小从而使模型的泛化误差增大,也就是模型过于复杂而产生了过拟合现象。当选择较大的K值时,将使模型趋于简单,容易发生欠拟合的情况。极端情况下,如果直接将K值设置为样本总数,则无论新输入的样本点位于什么地方,模型都会简单地将它预测为训练样本最多的类别,并且恒定不变,因此,对于K值的选择,依然建议使用第4章所介绍的交叉验证方法进行选择。
5.2.3 距离度量#
在样本空间中,任意两个样本点之间的距离都可以看作两个样本点之间的相似性度量。两个样本点之间的距离越近,也就意味着这两个样本点越相似。在第11章介绍聚类算法时,同样也会用到样本点间相似性的度量。同时,不同的距离度量方式将会产生不同的距离,进而最后产生不同的分类结果。虽然一般情况下K近邻使用的是欧氏距离,但也可以是其他距离,例如更一般的$L_P$距离或者Minkowski距离[1]。
设训练样本$X=\{{{x}^{(1)}},{{x}^{(2)}},...,{{x}^{(n)}}\}$其中${{x}^{(i)}}=\{x_{1}^{(i)},x_{2}^{(i)},...,x_{m}^{(i)}\}\in {{R}^{m}}$,即每个样本包含$m$个特征维度,则$L_p$距离定义为
$$ {{L}_{p}}({{x}^{(i)}},{{x}^{(j)}})={{\left( \sum\limits_{k=1}^{m}{|}x_{k}^{(i)}-x_{k}^{(j)}{{|}^{p}} \right)}^{\frac{1}{p}}};\quad p\ge 1\tag{5-1} $$(1) 当$p=1$时称为曼哈顿(Manhattan Distance),即
$$ {{L}_{1}}({{x}^{(i)}},{{x}^{(j)}})=\sum\limits_{k=1}^{m}{|}x_{k}^{(i)}-x_{k}^{(j)}|\tag{5-2} $$从式(5-2)可以看出,曼哈顿距离计算的是各个维度之间距离的绝对值累加和。
(2) 当$p=2$时称为欧氏距离(Euclidean Distance),即
$$ {{L}_{2}}({{x}^{(i)}},{{x}^{(j)}})={{\left( \sum\limits_{k=1}^{m}{|}x_{k}^{(i)}-x_{k}^{(j)}{{|}^{2}} \right)}^{\frac{1}{2}}}\tag{5-3} $$(3) 当$p=\infty$时,它是各个坐标距离中的最大值,即
$$ {{L}_{\infty }}({{x}^{(i)}},{{x}^{(j)}})=\underset{k}{\mathop{\max }}\,|x_{k}^{(i)}-x_{k}^{(j)}|\tag{5-4} $$当然,$p$同样能取其他任意的正整数,然后按照式(5-1)进行计算即可。
例如现有二维空间的3个样本点${{x}^{(1)}}=(0,0),{{x}^{(2)}}=(4,0),{{x}^{(3)}}=(3,3)$,则其在不同取值$p$下,距离样本点${{x}^{(1)}}$最近邻的点为
$$ \begin{aligned} & {{L}_{1}}({{x}^{(1)}},{{x}^{(2)}})=|0-4|+|0-0|=4 \\[1ex] & {{L}_{1}}({{x}^{(1)}},{{x}^{(3)}})=|0-3|+|0-3|=6 \\[1ex] & {{L}_{2}}({{x}^{(1)}},{{x}^{(2)}})=\sqrt{{{(0-4)}^{2}}+{{(0-0)}^{2}}}=4 \\[1ex] & {{L}_{2}}({{x}^{(1)}},{{x}^{(3)}})=\sqrt{{{(0-3)}^{2}}+{{(0-3)}^{2}}}\approx 4.2 \\[1ex] & {{L}_{\infty }}({{x}^{(1)}},{{x}^{(2)}})=\max \{|0-4|,|0-0|\}=4 \\[1ex] & {{L}_{\infty }}({{x}^{(1)}},{{x}^{(3)}})=\max \{|0-3|,|0-3|\}=3 \\ \end{aligned}\tag{5-5} $$由式(5-5)可知,当$p=1,2,\infty$时,离样本点${{x}^{(1)}}$最近的样本点分别是 ${{x}^{(2)}},{{x}^{(2)}},{{x}^{(3)}}$。
5.2.4 小结#
在本节内容中,我们首先介绍了K近邻算法的核心原理;然后介绍了K值选取对于K近邻算法的影响;最后介绍了在K近邻中计算各样本间距离时的不同度量方式,即$L_P$距离。