4.9 LangGraph 基本概念介绍#
在第4.4节内容中,我们通过 LangChain 中的 create_agent 函数快速完成了 Agent 的创建,并借助 agent.stream() 方法构建了整个处理流程——包括判断用户问题是否需要拆解、当前检索到的信息是否足以回答问题,以及最终整合所有内容生成用户回答。但整个过程中,这些分支与循环都是由框架在背后隐式处理的,我们并没有对其进行显式的定义和控制。当业务逻辑更加复杂、需要精细掌控每一步执行路径时,这种方式就显得力不从心了。
事实上,上述整个流程本质上是一个图结构,而 create_agent 的背后正是基于 LangGraph 的图机制来实现的,它让我们能够以图结构显式地定义工作流中的节点、分支和循环,从而对 Agent 的执行过程有完整的掌控力。
4.9.1 LangGraph 的核心思想#
LangGraph 的核心思想其实可以用一句话来概括,它把 Agent 的工作流程抽象成了一张可以被精确控制的图(Graph)。 与传统的链式调用(Chain)不同,LangGraph 不再只是简单地让模型一步接一步执行任务,而是像搭建一个智能工作流系统一样,让每一个步骤都具备明确的状态管理、逻辑控制以及路径选择能力。
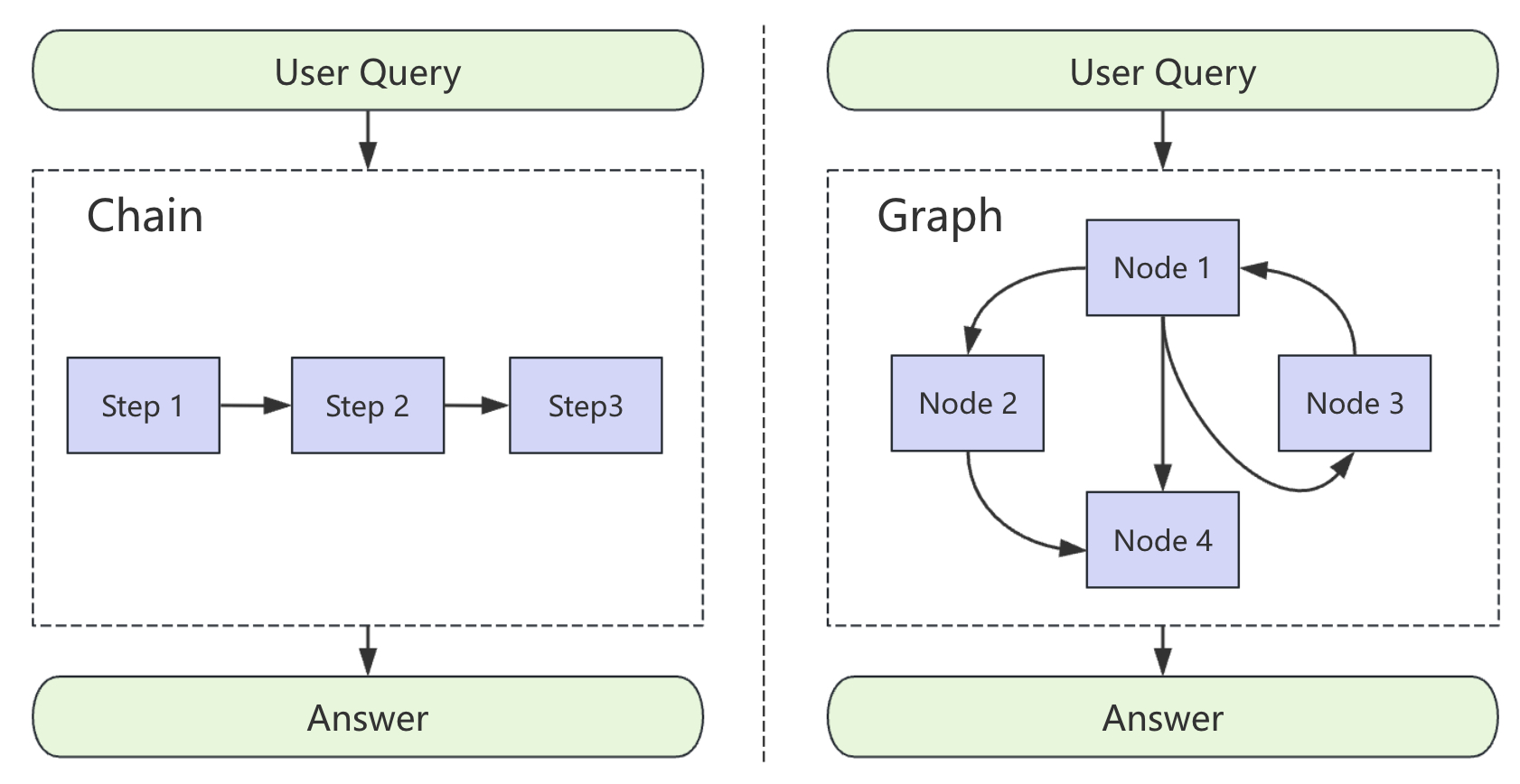
如图4-12所示便是 LangChain 与 LangGraph 执行流程对比图。从图中可以看出,与 LangChain 最大的区别在于 LangGraph 中的整个流程可以根据不同的条件进行不同的流转。
整体来看,LangGraph 将 Agent 的工作流建模为一张有向图,它由三个核心组件构成:
- State(状态):整个图的共享数据结构,代表应用在某一时刻的完整快照;
- Node(节点):图中的节点,每个节点是一个 Python 函数,接收当前 State 作为输入,执行计算后返回更新后的 State;
- Edge(边):图中的边,决定下一步应该执行哪个节点。
用一句话概括,节点负责做事,边负责决定下一步做什么(Nodes do the work,Edges tell what to do next.)。
因此,这就意味着 Agent 将会拥有清晰的执行路径、可回溯的状态记录,以及可控的决策机制,这也是为什么越来越多复杂场景,比如多轮对话、复杂任务拆解、工具调用编排等,都会选择使用 LangChain 的原因。
同时,LangGraph 的底层采用了消息传递(Message Passing)机制,整体执行过程按"超步"(Superstep)推进,即同一超步内的节点并行执行,不同超步之间顺序执行,当所有节点都处于空闲状态且没有消息在传递时图执行结束。
举个例子,例如某一天中有3场资格考试,不同的学生参加不同的考试。此时,每一场考试都可以看做是一个超步,而在一个超步中每个学生可以看做是一个节点,这些节点同时答题(并行),当本场考试结束后才能进入到下一场考试(串行)。
4.9.2 图中的共享状态#
(1) 状态的定义
状态是整个图中所有节点和边共享的数据结构,可以理解为整个图在某一时刻的"快照",它记录了系统此刻知道的全部信息,比如用户输入、历史消息、工具返回结果、模型中间推理过程等,本质上它就是 Agent 的“记忆中枢”,会在整个工作流中不断被更新。
在 LangGraph 中通常使用 TypedDict 来定义状态:
1 from typing_extensions import TypedDict
2 class State(TypedDict):
3 foo: int
4 bar: list[str]这里值得注意的是,每个节点并不需要返回完整的状态,只需要返回它修改了哪些字段即可,LangGraph 会自动将更新合并到当前的状态中。
这里稍微提一下,TypedDict 是 Python 类型注解(Type Hints)中的一种工具,用来给字典定义固定的键和值类型。它的作用是让字典像结构化对象一样有明确字段定义,方便类型检查、代码提示和大型工程维护。
例如:
1 class InputState(TypedDict):
2 user_input: str
3 user_id: str
4 if __name__ == '__main__':
5 input_stat: InputState = {"user_input": "郭靖是谁?","user_id":"00001"}
6 print(input_stat) # {'user_input': '郭靖是谁?', 'user_id': '00001'}可以看出,TypedDict 本质上也是一个字典,只是相当于给了这个对象固定的键和值类型。
(2)状态的更新方式
此时可以发现这里存在一个问题,如果多个节点都对同一个字段进行了更新,LangGraph 该如何处理?
答案是通过归约函数(Reducer )——多个值"归并"成一个结果的过程——来决定。
对于上面定义的 State类它并没有指定归约函数,所以默认行为是新值直接覆盖旧值。
例如,初始状态为 {"foo": 1, "bar": ["hi"]},第1个节点返回 {"foo": 2},则状态变为 {"foo": 2, "bar": ["hi"]};第2个节点返回 {"bar": ["bye"]},则状态变为 {"foo": 2, "bar": ["bye"]}——注意 bar 被整个替换了。
如果希望对某个字段进行追加而不是覆盖,可以通过 Annotated 来指定归约函数,代码如下:
1 from typing import Annotated
2 from operator import add
3
4 class State(TypedDict):
5 foo: int
6 bar: Annotated[list[str], add] # 使用 add 作为 Reducer,追加而非覆盖此时,同样的初始状态和节点输出,这次第2个节点返回 {"bar": ["bye"]} 后,bar 的结果会变成 ["hi", "bye"],而不是被替换。
(3)多 Schema 设计
在实际项目中,并不是所有字段都需要暴露给外部。LangGraph 支持为图定义独立的输入/输出字段结构(Schema),同时允许节点之间通过私有字段传递内部数据。
1 class InputState(TypedDict):
2 user_input: str # 只暴露给外部的输入字段
3
4 class OutputState(TypedDict):
5 graph_output: str # 只暴露给外部的输出字段
6
7 class OverallState(TypedDict):
8 foo: str # 图内部流转的字段
9 user_input: str
10 graph_output: str
11
12 class PrivateState(TypedDict):
13 bar: str # 仅在特定节点间传递,不对外暴露在上述代码中,我们定义了4种不同的状态字段结构。
(4)消息状态
在 RAG 和对话型 Agent 中,状态里最常见的一个字段就是历史消息列表。为此,LangGraph 提供了一个预置的 MessagesState,内置了 messages 字段以及对应的 add_messages 归约函数。
1 from langgraph.graph import MessagesState
2
3 class MessagesState(TypedDict):
4 messages: Annotated[list[AnyMessage], add_messages]
5
6 class State(MessagesState):
7 documents: list[str] # 在 MessagesState 基础上追加自定义字段add_messages 这个归约函数比简单的 operator.add 更智能,它不仅能追加新消息,还能根据消息 ID 对已有消息进行更新,这在"Human-in-the-loop"场景中(即需要手动修改某条历史消息时)非常有用。
例如,以下内容便是第4.4节中介绍的 RAG Agent 在回答用户问题时的中间各类 Messages 状态。
[HumanMessage(content='郭靖这个人物在这部小说当中是谁?它的出生背景是什么?'),
AIMessage(content='', tool_calls=[{'name': 'retrieve_context', 'args': {'query': '郭靖 出生背景 人物介绍'}, 'id': 'call_f64d2d51a57643449f8615', 'type': 'tool_call'}]),
ToolMessage(content="Source: {'level_1': '第七回 比武招亲', 'source': '~/RAGWithMe/data/jinyong/金庸-射雕英雄传精校版.txt', 'start_index': 5796}\nContent: 郭靖之母是浙江临安人,...Source: {'level_1': '第七回 比武招亲', 'source': '~/RAGWithMe/data/jinyong/金庸-射雕英雄传精校版.txt', 'start_index': 7025}\nContent: 那少年挥挥手,又跟郭靖谈论起来,...Source: {'level_1': '第五回 弯弓射雕', 'source': '~/RAGWithMe/data/jinyong/金庸-射雕英雄传精校版.txt', 'start_index': 6652}\nContent: 华筝幼时由父亲许配给王罕的孙子都史...", name='retrieve_context'),
AIMessage(content='郭靖是《射雕英雄传》中的核心主人公。他的母亲是浙江临安人,他从小在江南六怪的故乡嘉兴左近听惯江南口音;他一生长于蒙古大漠,与拖雷、华筝自幼交好。')]4.9.3 图中的节点#
节点是执行具体任务的函数,每一个节点都代表一个独立能力模块,比如调用大模型回答问题、执行数据库查询、调用搜索工具、更新记忆等等,它接收当前状态,完成计算后再返回更新后的状态。
(1)节点的基本写法
LangGraph 中的节点就是普通的 Python 函数,它接收当前状态并返回更新后的结果,代码如下:
1 from langgraph.graph import StateGraph
2 from typing_extensions import TypedDict
3
4 class State(TypedDict):
5 input: str
6 results: str
7
8 def my_node(state: State):
9 return {"results": f"Hello, {state['input']}!"}
10
11 if __name__ == '__main__':
12 builder = StateGraph(State)
13 builder.add_node("my_node", my_node) # 显式命名
14 # builder.add_node(my_node) # 也可以省略名称,默认使用函数名 "my_node"
15 graph = builder.compile()
16 r = graph.invoke({"input": "Everyone"})
17 print(r) # {'input': 'Everyone', 'results': 'Hello, Everyone!'}在上述代码中第8~9行便是定义了一个节点,并对输入进行了相关操作。第12行是创建一个 LangGraph 图构建器,并指定整个工作流共享的状态结构 State。因为 LangGraph 是基于状态驱动的工作流框架,所有节点都通过读取和更新同一个状态来协作,因此必须先定义 State 的字段,再基于它创建 StateGraph。第13~14是以两种不同的方式往图中添加节点。以上完整示例代码可参见 Code/Chapter04/C09_langgraph_usage.py 文件。
(2)节点缓存
对于耗时较长的节点,LangGraph 支持节点级缓存,以避免对于同样的输入再次计算,代码如下:
1 def expensive_node(state: State) -> State:
2 time.sleep(2) # 模拟耗时计算
3 return {"input": state["input"], "results": state["input"] * 2}
4
5 if __name__ == '__main__':
6 builder = StateGraph(State)
7 builder.add_node("expensive_node", expensive_node,
8 cache_policy=CachePolicy(ttl=3)) # 缓存3秒
9 graph = builder.compile(cache=InMemoryCache())
10 s1 = time.time()
11 r = graph.invoke({"input": 5}) # 第一次:耗时约2秒
12 s2 = time.time()
13 print(r, s2 - s1) # # {'input': 5, 'results': 10} 2.0084080696105957
14 r = graph.invoke({"input": 5}) # 第二次:直接命中缓存,瞬间返回
15 print(r, time.time() - s2) # # {'input': 5, 'results': 10} 0.0018870830535888672在上述代码中,第8行便是指定节点缓存,ttl 参数控制缓存的有效时长(秒),过期后会重新计算,完整示例可参见 Code/Chapter04/C10_langgraph_usage.py 文件。
4.9.4 图中的边#
边负责决定“下一步该走向哪里”,是整个工作流"往哪走"的关键所在。边定义了节点之间的连接关系,可以是固定跳转,也可以是条件判断。例如,在 Prompt 里面写明“如果需要联网搜索,就进入 Search Node;否则直接进入 Answer Node”。正是状态、节点和边这三者的协同配合,让 LangGraph 从简单的 Prompt 编排工具,真正进化成了一个可以构建复杂 AI Agent 系统的底层框架。
(1)普通边
最简单的情况是节点 A 执行完毕后无条件进入节点 B,便可以通过如下方式添加这条边:
1 builder.add_edge("node_a", "node_b")(2)条件边
如果需要根据当前状态的内容来决定下一步走哪条分支,可以使用条件边,也称为路由:
1 def node_a(state: State) -> State:
2 return { "results": f"我是节点 a,你输入的数字 {state["input"]} 是一个奇数!"}
3
4 def node_b(state: State) -> State:
5 return { "results": f"我是节点 b,你输入的数字 {state["input"]} 是一个偶数!"}
6
7 def routing_function(state: State) -> str:
8 num = int(state["input"])
9 if num % 2 == 0:
10 return 'my_node_b'
11 else:
12 return 'my_node_a'
13
14 if __name__ == '__main__':
15 builder = StateGraph(State)
16 builder.add_node('my_node_a', node_a)
17 builder.add_node('my_node_b', node_b)
18 builder.add_conditional_edges(START, routing_function)
19 builder.add_edge('my_node_a', END)
20 builder.add_edge('my_node_b', END)
21 graph = builder.compile()
22 print(graph.invoke({"input": 5}))
23 print(graph.invoke({"input": 6}))在上述代码中,第1~5行定义了两个节点分别执行不同的内容。第7~13行定义一个路由函数,接收当前 state 并返回下一个要执行的节点名称(或节点名称列表)。第18行则是添加条件边。同时,这里START 和 END 是两个特殊节点,用于标记图的入口和出口。第21行是定义好所有节点和边之后调用 .compile() 来完成图的编译,这一步会对图结构做基本检查(例如是否有孤立节点)。
上述代码运行结束以后将会输出如下结果:
{'input': 5, 'results': '我是节点 a,你输入的数字 5 是一个奇数!'}
{'input': 6, 'results': '我是节点 b,你输入的数字 6 是一个偶数!'}这里值得注意的是,图执行完毕以后的输出结果中将包含状态的所有信息。以上完整示例代码可参见 Code/Chapter04/C11_langgraph_usage.py 文件。
(3)状态更新与路由一体化
如果在某个场景中,在条件边跳转的同时还需要修改状态,一种做法是把两件事分开写,不过还可以借助 LangGraph 中一个更灵活的控制原语 Command ,它允许在节点函数中同时完成状态更新和路由跳转。
1 def routing_node(state: State) -> Command[Literal["my_node_a", "my_node_b"]]:
2 num = state["input"]
3 if num % 2 == 0:
4 return Command(update={"desc": "判断是否为偶数"}, goto="my_node_b")
5 else:
6 return Command(update={"desc": "判断是否为奇数"}, goto="my_node_a")
7
8 if __name__ == '__main__':
9 builder = StateGraph(State)
10 builder.add_node('my_node_a', node_a)
11 builder.add_node('my_node_b', node_b)
12 builder.add_node('my_routing_node', routing_node)
13 builder.add_edge(START,'my_routing_node')
14 builder.add_edge('my_node_a', END)
15 builder.add_edge('my_node_b', END)
16 graph = builder.compile()
17 print(graph.invoke({"input": 5}))
18 print(graph.invoke({"input": 6}))在上述代码中,第1~6行便是根据前面的 routing_function 修改而来,从边改造成了一个节点,其中 update={"desc": "判断是否为偶数"} 便是在修改 state 中的 desc 字段信息,goto 参数则是下一步将要路由的节点。同时,第12~13行也做出了对应的修改。
上述代码运行结束以后将会得到如下结果:
{'input': 5, 'results': '我是节点 a,你输入的数字 5 是一个奇数!', 'desc': '判断是否为奇数'}
{'input': 6, 'results': '我是节点 b,你输入的数字 6 是一个偶数!', 'desc': '判断是否为偶数'}以上完整示例代码可参见 Code/Chapter04/C12_langgraph_usage.py 文件。
4.9.5 可视化图结构#
在构建完整个工作流图以后,我们还可以对其进行可视化。首先,通过代码 print(graph.get_graph().draw_mermaid()) 输出元数据,类似如下:
---
config:
flowchart:
curve: linear
---
graph TD;
__start__([<p>__start__</p>]):::first
my_node_a(my_node_a)
my_node_b(my_node_b)
my_routing_node(my_routing_node)
__end__([<p>__end__</p>]):::last
__start__ --> my_routing_node;
my_routing_node -.-> my_node_a;
my_routing_node -.-> my_node_b;
my_node_a --> __end__;
my_node_b --> __end__;
classDef default fill:#f2f0ff,line-height:1.2
classDef first fill-opacity:0
classDef last fill:#bfb6fc然后打开网站 https://mermaid.ink ,将上面的内容粘贴到网站左侧的输入框中即可看到渲染后的结果,如图4-13所示。
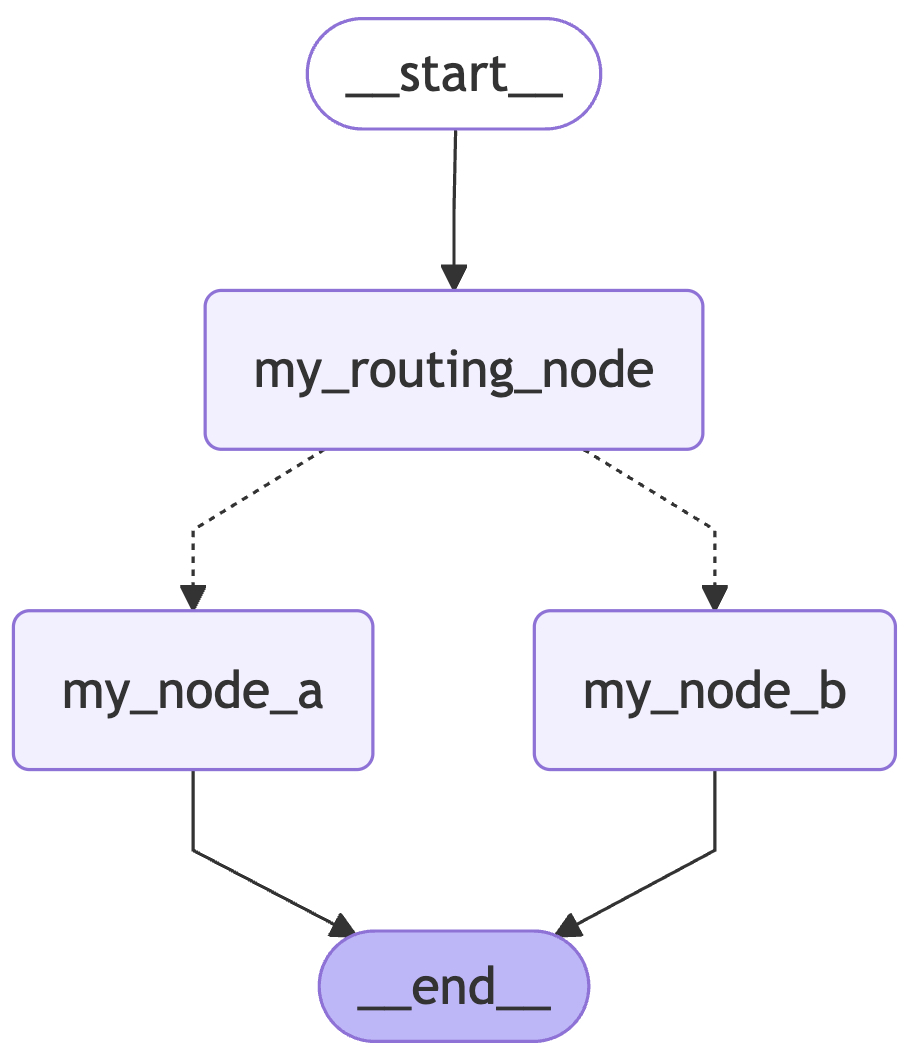
如图4-13所示便是上面介绍 Command 时所构建的工作流图,其中虚线连接部分表示条件边。根据可视化后的结果,便能够一眼看清楚整个工作流,这对弄清复杂的 Agent 流程编排是非常有用的。
以上就是对 LangGraph 的一个基本介绍,相信此时大家已经对 LangGraph 有了一个基本的了解。更多特性及功能我们在后续的学习过程中还会持续进行介绍。
引用#
[1] https://docs.langchain.com/oss/python/langgraph/use-graph-api#visualize-your-graph