3.3 向量数据库选择#
当我们载入文本并且进行分块以后就需要通过词嵌入模型来把这些分块好的文本统一都转换成一个固定维度的向量化表示,并存储到向量数据库中,以供后续进行语义检索。
3.3.1 Milvus 介绍#
对于向量数据库的选择有很多,例如 Chroma、Milvus、MongoDB、pgvector、Qdrant 等等,它们本质上分成两大类:
- 专门的向量数据库:Milvus、Qdrant、Chroma
- 通用数据库 + 向量扩展能力:MongoDB、PostgreSQL + pgvector
这里我们以使用最为广泛之一的 Milvus /ˈmɪl.vəs/(米尔沃斯)向量数据库。Milvus 这个词原意是鹰科中的一种猛禽,以飞行速度快、视力敏锐、适应性强而著称,而这也恰好能够凸显它作为向量数据库时的优秀性能 [1]。

Milvus 是一个开源的向量数据库,用于管理、索引和搜索高维向量数据。它在机器学习、推荐系统和生成式 AI 应用中广泛使用,以支持快速的相似度语义检索与嵌入数据存储。同时,Milvus 还提供了丰富的 SDK(Python、Java、Go 等),方便与 AI 框架(如 PyTorch、TensorFlow、OpenAI Embeddings API)快速集成。
3.3.2 Milvus 部署模式选择#
同时,Milvus 提供了三种部署模式,涵盖从 Jupyter Notebooks 中的本地原型到管理数百亿向量的大规模 Kubernetes 集群的各种数据规模 [2]。
- Milvus Lite 是一个 Python 库,可以轻松集成到您的应用程序中。作为 Milvus 的轻量级版本,它非常适合在 Jupyter Notebooks 中进行快速原型开发,或在资源有限的边缘设备上运行。
- Milvus Standalone 是单机服务器部署,所有组件都捆绑在一个 Docker 镜像中,方便部署。
- Milvus Distributed 可部署在 Kubernetes 集群上,采用云原生架构,专为十亿规模甚至更大的场景而设计。
对于 Milvus 部署模式的选择,可以取决于项目的阶段和规模。简单地,可以通过图3-4这张规模图来进行选择。
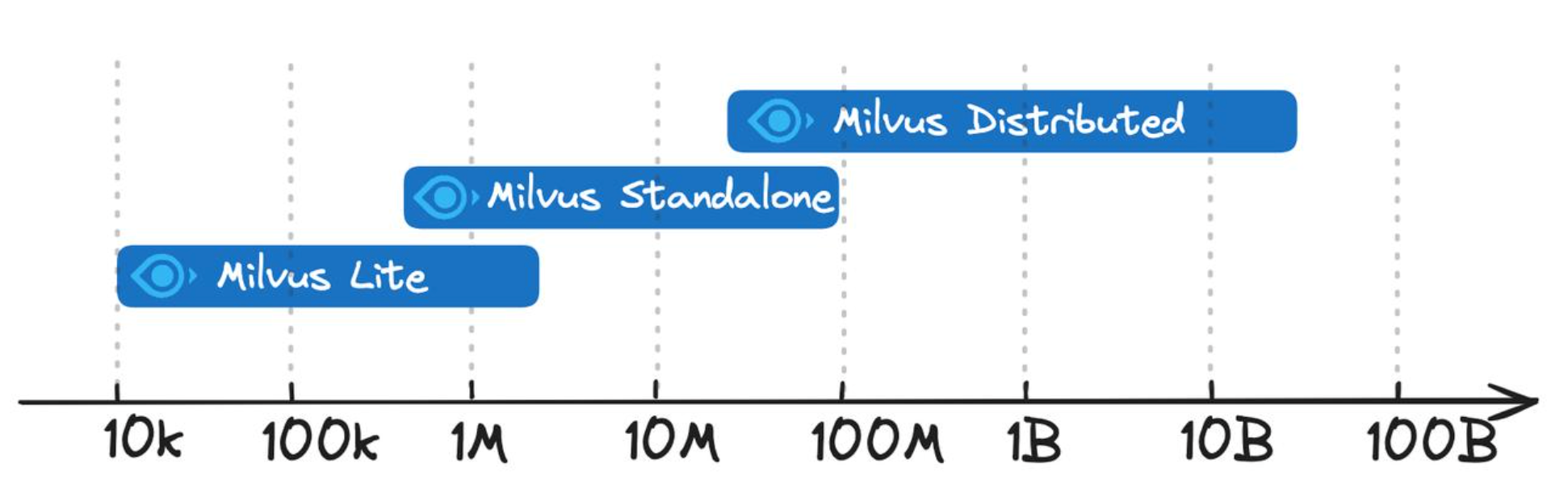
总结起来就是,Milvus Lite 建议用于较小的数据集,向量规模在百万级左右;Milvus Standalone 适用于中型数据集,向量规模可扩展至 一亿左右;Milvus Distributed 则是专为大规模部署而设计,能够处理从一亿到数百亿规模的向量。后续,我们将以 Milvus Lite 为例来进行介绍。
3.3.3 Milvus 安装与基本概念#
对于本门课程中所使用到的 RAG 环境,我们首先需要安装 milvus-lite,然后是对应的 Python SDK 包 pymilvus,以及为了使用 LangChain 框架对应的 langchain-milvus 包。
(1) Milvus-lite 安装
首先,我们通过如下两行命令来安装 Milvus-lite 及其对应的 Python SDK
pip install milvus-lite
pip install pymilvus在通过上述命令安装完成以后,我们可以通过如下方式来创建一个向量数据库:
1 from pymilvus import MilvusClient
2 client = MilvusClient("./milvus_demo.db")运行上述代码段后,将在当前文件夹下生成名为 milvus_demo.db 的数据库文件。
更多 Milvus-lite 的相关操作,可参见官网 [3]。
(2)Milvus 基本概念
在关系型数据库(如 MySQL、PostgreSQL)中,我们习惯用 CRUD(Create / Read / Update / Delete) 来描述数据的基本操作,其本质是基于字段条件的精确匹配查询;而在向量数据库领域,也可以映射到类似的“增删改查”逻辑,同时向量数据库的核心不同在于它的“查”不是等值匹配,而是“相似度搜索”。
为了便于理解,我们把 Milvus 中的相关概念与传统关系型数据库中的概念做一个映射,并依次做一个简单的介绍。
同传统关系型数据库一样,在 Milvus 中数据库是组织和管理数据的逻辑单元。为了提高数据安全性并实现多租户,我们可以创建多个数据库,为不同的应用程序或租户从逻辑上隔离数据。
不过值得注意的是,对于 Milvus Lite 来说它并不支持创建数据库,仅含有一个默认数据库。
(3)集合 Collections
在 Milvus 中,我们可以创建多个 Collections 来管理数据,并将数据作为实体(Entity)插入到 Collections 中。Collections 和实体类似于关系数据库中的表和记录,因此,Collection 是一个二维表,具有固定的列和变化的行,每列代表一个字段,每行代表一个实体。
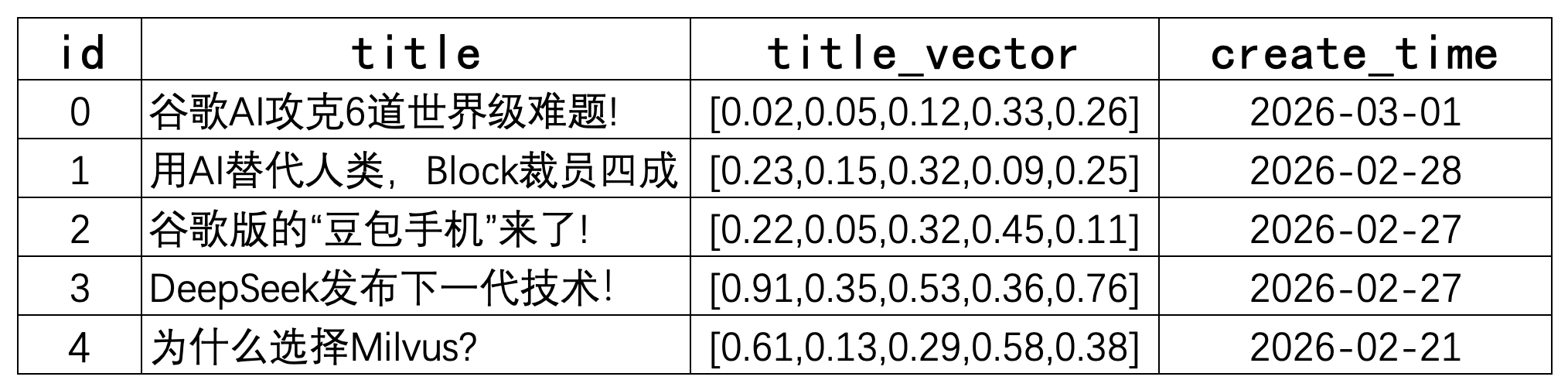
如表3-1所示,这个 Collection 一共有 4 列和 5 个实体的。
(4) Schema 和字段
在描述一个实体时,我们通常会提到它的属性,如大小、重量和位置,这也就是关系型数据库中的字段。在 Milvus 中,我们需要先创建一个 Schema,然后在 Schema 中定义相关字段信息,最后再基于这个 Schema 来创建我们的 Collection。也就是说我们可以把 Schema 理解为关系型数据库中的建表语句。
同时,与关系数据库中的主字段类似,Collection 也有一个主字段(主键,Primary Key)用于将实体与其他实体区分开来,如上图1所示,名为 id 的字段是主字段,并且通常会将主字段设置为自增。
(5)加载和释放
加载集合是在集合中进行相似性搜索和查询的前提,换句话说如果我们需要进行相似性搜索和查询,那么就需要将 Collection 加载到内存中。在加载 Collection 时,Milvus 会将所有索引文件和每个字段中的原始数据加载到内存中,以便快速响应搜索和查询。同时,Milvus 可以只加载搜索和查询所涉及的字段,从而减少内存使用并提高搜索性能 [7]。
在使用时,大多数情况下在服务启动时加载好,然后一直使用即可,不用频繁加载和释放。当然,如果有多个 Collection,且内存不够全部加载时,可以只加载热门 Collection,手动释放冷门的 Collection。
更多相关基本概念,可参见官方文档 [4] [5] 。
3.3.4 Milvus 使用示例#
在介绍完 Milvus 中的几个重要基本概念以后,我们再来看如何完成 Collection 的创建及基本使用。
(1)Schema 定义
我们以图1中示例为例,先定义一个 Schema,代码如下:
1 def define_schema():
2 schema = MilvusClient.create_schema(enable_dynamic_field=True)
3 schema.add_field(field_name="id", datatype=DataType.INT64,
4 auto_id=True, is_primary=True, description='主键')
5 schema.add_field(field_name="title", datatype=DataType.VARCHAR,
6 max_length=512, description="新闻标题")
7 schema.add_field(field_name="title_vector", datatype=DataType.FLOAT_VECTOR,
8 dim=5, description="标题向量")
9 schema.add_field(field_name="create_time", datatype=DataType.INT32, description="创建时间")
10 return schema
11
12 if __name__ == '__main__':
13 client = MilvusClient("./milvus_demo.db")
14 schema = define_schema()在上述代码中,第2行是创建一个 Schema 对象,并且指定 enable_dynamic_field = True,它的作用是当我们插入的字段未声明时Milvus 会自动创建一个隐藏字段 $meta ,所有未声明字段会被自动存入这个 JSON 结构中,否则就会报错 field extra_field not found in schema。
例如上面我们只声明了4个字段,当多插入两个字段 "author": "wang", "score": 98 时,实际上会被存储为
{
id: 10,
title: "xxxxxxxx",
title_vector: [....],
create_time: 2026-02-22,
$meta: {
"author": "wang",
"score": 98
}
}同时,第4~11行代码分别是定义自增主字段、标题字段、向量字段和日期字段,如果是时间戳的化可以设置为 DataType.INT64。
这里需要注意的是,这里的 schema只是一个包含结构定义的 Python 对象,并不会单独存在于数据库中,真正持久化的是创建后的 Collection。
(2)索引及Collection 创建
为了方便后续能够快速搜索到我们需要的向量,所以这里还需要声明构建的索引,示例代码如下:
1 index_params = client.prepare_index_params()
2 index_params.add_index(field_name="title_vector", index_type="AUTOINDEX",
metric_type="IP",)在上述代码中,第2行便是声明将要为 title_vector 构建一个索引, index_type="AUTOINDEX" 可以在建立索引的同时分析 Collection 中的数据分布,并根据分析结果设置最优化的索引参数,从而在搜索性能和正确性之间取得平衡。 metric_type="COSINE" 表示使用余弦距离进行索引构建,metric_type 的其它度量方式还有L2、IP (向量内积)等 [6],区别如下:
| 类型 | 是否考虑向量长度 | 适合场景 |
|---|---|---|
| L2 | 是 | 欧式距离 |
| IP | 是 | 推荐系统、embedding |
| COSINE | 否(只看方向) | 文本相似度 |
在完成 Schema 及索引定义以后,可以通过如下语句来创建 Collection:
1 client.create_collection(collection_name="my_collection", schema=schema, index_params=index_params)在完成 Collection 创建以后,可以通过如下代码来查看当前库中的所有存在的 Collection:
1 res = client.list_collections()
2 print(res) # ['my_collection']从输出结果可以看出,当前 milvus_demo.db 中仅存在一个 Collection。
同时,可以通过如下代码来查看 Collection 的结构信息:
1 res = client.describe_collection(collection_name="my_collection")
2 print(res)上述代码运行结束后的结果为:
{
'collection_name': 'my_collection',
'auto_id': True,
'num_shards': 0,
'description': '',
'fields': [{'field_id': 100, 'name': 'id','description': '主键',
'type': < DataType.INT64: 5 > , 'params': {}, 'auto_id': True, 'is_primary': True},
{'field_id': 101, 'name': 'title', 'description': '新闻标题',
'type': < DataType.VARCHAR: 21 > ,'params': {'max_length': 512}},
{'field_id': 102, 'name': 'title_vector', 'description': '标题向量',
'type': < DataType.FLOAT_VECTOR: 101 > , 'params': {'dim': 5}},
{'field_id': 103, 'name': 'create_time', 'description': '创建时间',
'type': < DataType.INT32: 4 > ,'params': {}}],
'functions': [], 'aliases': [], 'collection_id': 0, 'consistency_level': 0,
'properties': {}, 'num_partitions': 0, 'enable_dynamic_field': True,
'enable_namespace': False
}同时,我们可以分别通过 client.has_collection("my_collection") 来判断是否存在某个集合,client.drop_collection("my_collection") 来删除指定集合。
(3)插入数据
因为上面指定了 auto_id=True,所以不要在数据中包含主字段id列,Milvus 会自动生成,这一点也和传统关系型数据库一致。进一步,我们可以通过下面代码输入图1中的示例数据:
1 def insert_data(client):
2 dt0 = datetime.datetime.strptime("2026-03-01", "%Y-%m-%d")
3 dt1 = datetime.datetime.strptime("2026-02-28", "%Y-%m-%d")
4 dt2 = datetime.datetime.strptime("2026-02-27", "%Y-%m-%d")
5 dt3 = datetime.datetime.strptime("2026-02-27", "%Y-%m-%d")
6 dt4 = datetime.datetime.strptime("2026-02-21", "%Y-%m-%d")
7 data = [{"title": "谷歌AI攻克6道世界级难题!", "title_vector": [0.02, 0.05, 0.12, 0.33, 0.26],
8 "create_time": int(dt0.timestamp())},
9 {"title": "用AI替代人类,Block裁员四成", "title_vector": [0.23, 0.15, 0.32, 0.09, 0.25],
10 "create_time": int(dt1.timestamp())},
11 {"title": "谷歌版的“豆包手机”来了!", "title_vector": [0.22, 0.05, 0.32, 0.45, 0.11],
12 "create_time": int(dt2.timestamp())},
13 {"title": "DeepSeek发布下一代技术!", "title_vector": [0.91, 0.35, 0.53, 0.36, 0.76],
14 "create_time": int(dt3.timestamp())},
15 {"title": "为什么选择Milvus?", "title_vector": [0.61, 0.13, 0.29, 0.58, 0.38],
16 "create_time": int(dt4.timestamp()),"author":"wangcheng"}]
17 res = client.insert(collection_name="my_collection", data=data)
18 print("Generated IDs:", res)在上述代码运行结束以后,将会得到如下输出结果:
Generated IDs: {'insert_count': 5, 'ids': [464611230885871616, 464611230885871617, 464611230885871618, 464611230885871619, 464611230885871620]}其中 insert_count 表示插入的记录数,ids 表示自动生成的主键,对应上面的id字段。
这里尤其需要注意的是,在 Milvus 中自动主键不是简单自增整数,而是分布式的全局唯一 ID。如果强制依次递增,那么当节点 A 插入数据,节点 B 同时插入数据,那么两个节点都会生成 0 就冲突了。所以Milvus 的 ID 不是严格连续自增的。
(4) 查看数据
在插入数据以后,我们可以查看 Collection 中的数据,不过在这之前我们需要先将 Collection 加载到内存中,完整示例代码如下:
1 def select_data(client):
2 client.load_collection(collection_name="my_collection")
3 print(f"\n查看当前加载状态:{client.get_load_state(collection_name="my_collection")}")
4 res = client.query(collection_name="my_collection", filter="id >= 0", # 必须有条件
5 output_fields=["title", "create_time"])
6 print(f"\n当前 my_collection 中的数据: {res}")
7 res = client.query(collection_name="my_collection",filter="author == 'wangcheng'")
8 print(f"\n当前 my_collection 中的数据: {res}")
9 client.release_collection(collection_name="my_collection")
10 print(f"\n查看当前加载状态:{client.get_load_state(collection_name="my_collection")}")在上述代码中,第4~5行便是查询的语句,其中 filter 类似于传统数据库的 where 必须要有,同时输出字段为 ["title", "create_time"],不过主键也会被输出。第7行代码则是通过隐藏字段过滤,也可以写成如下形式:
1 res = client.query(collection_name="my_collection",filter="$meta['author'] == 'wangcheng'" )上述代码运行结束以后,将会看到类似如下结果:
查看当前加载状态:{'state': <LoadState: Loaded>}
当前 my_collection 中的数据: data: ["{'id': 464611230885871616, 'create_time': 1772294400, 'title': '谷歌AI攻克6道世界级难题!'}", "{'id': 464611230885871617, 'create_time': 1772208000, 'title': '用AI替代人类,Block裁员四成'}", "{'id': 464611230885871618, 'create_time': 1772121600, 'title': '谷歌版的“豆包手机”来了!'}", "{'id': 464611230885871619, 'create_time': 1772121600, 'title': 'DeepSeek发布下一代技术!'}", "{'id': 464611230885871620, 'create_time': 1771603200, 'title': '为什么选择Milvus?'}"], extra_info: {}
当前 my_collection 中的数据: data: ["{'id': 464611230885871620, 'create_time': 1771603200, 'title': '为什么选择Milvus?', 'title_vector': [0.6100000143051147, 0.12999999523162842, 0.28999999165534973, 0.5799999833106995, 0.3799999952316284], 'author': 'wangcheng'}"], extra_info: {}
查看当前加载状态:{'state': <LoadState: NotLoad>}这里需要说明一点,在 Milvus-lite 中,其实 load_collection 这个操作已经被框架给接管了,也就是说不要 load_collection 也行。但是为了保持代码的兼容性,建议还是手动加上。
(5) 搜索数据
这里所谓的搜索数据指的就是我们使用向量数据库的核心需求,能够快速返回与给定向量相似的前K个向量,使用示例如下:
1 def search_data(client):
2 client.load_collection(collection_name="my_collection")
3 print(f"\n查看当前加载状态:{client.get_load_state(collection_name="my_collection")}")
4 query_vector = [0.81, 0.45, 0.51, 0.26, 0.66]
5 res = client.search(collection_name="my_collection",
6 anns_field="title_vector",data=[query_vector],
7 limit=3, search_params={"metric_type": "IP"})
8 print(res)
9 client.release_collection(collection_name="my_collection")
10 print(f"\n查看当前加载状态:{client.get_load_state(collection_name="my_collection")}")上述代码是返回与给定向量 query_vector 最相似的前3个向量。这里注意,第8行代码在指定 metric_type 要与上面建立索引时使用的 metric_type 一致。
上述代码运行结束后可以得到类似如下结果:
查看当前加载状态:{'state': <LoadState: Loaded>}
data: [[{'id': 464611230885871619, 'distance': 1.76010000705719, 'entity': {}}, {'id': 464611230885871620, 'distance': 1.102099895477295, 'entity': {}}, {'id': 464611230885871617, 'distance': 0.6053999662399292, 'entity': {}}]]
查看当前加载状态:{'state': <LoadState: NotLoad>}以上完整示例代码可参加 Code/Chapter03/C09_milvus_usage.py 文件。
到此,我们就把 Milvus 的安装方法和基本使用方法介绍完了。对于其它用法,我们在后续课程中用到时再进行讲解。
引用#
[1] https://milvus.io/docs/zh/overview.md
[2] https://milvus.io/docs/zh/install-overview.md
[3] https://milvus.io/docs/zh/milvus_lite.md
[4] https://milvus.io/docs/zh/schema.md
[5] https://milvus.io/docs/zh/manage-collections.md