2.6 正态分布#
2.6.1 一个问题的出现#
17、18世纪曾是科学发展的黄金年代,微积分的发展和牛顿万有引力定律的建立,直接推动了天文学和测地学的迅猛发展。这些天文学和测地学的问题,无不涉及数据的多次测量、分析与计算。很多年以前,学者们就已经经验性地认为,对于有误差的测量数据多次测量取算术平均是比较好的处理方法,并且这种做法现在我们依旧在使用。虽然当时缺乏理论上的论证,并且也不断地受到一些人的质疑,但取算术平均作为一种直观的方式,仍被使用了千百年。同时,算术平均在多年积累的数据处理经验中也得到相当程度的验证,被认为是一种良好的数据处理方法,但是在当时却没人能给出为什么。
1805年,勒让德提出了一种方法来解决这个问题,其基本思想认为测量中存在误差,并且让所有的误差累积为$\sum{{{(\hat{y}-y)}^{2}}}$,其中$\hat{y}$为观测值,$y$为理论值,然后通过最小化累积误差来计算得到理论值,即设真实值为$\theta$,${{x}_{1}},{{x}_{2}},...,{{x}_{n}}$分别为$n$次独立观测后的测量值,每次测量的误差为$e_{i}={x}_{i}-\theta $,按照勒让德提出的方法,累计误差为
$$ E(\theta )=\sum\limits_{i=1}^{n}{e_{i}^{2}}=\sum\limits_{i=1}^{n}{{{({{x}_{i}}-\theta )}^{2}}}\tag{2-18} $$可以看出勒让德给出的方法其实就是最小二乘法(Least Square)。通过对$E(\theta)$求导后令其为$0$,求解得到的结果正是算术平均$\bar{x}=1/n\sum x_{i}$。也就是说,取所有观测结果的平均值来近似地代替真实值最终所产生的误差是最小的。由于算术平均是一个历经考验的方法,而以上的推理从另一个角度也说明了最小二乘法的优良性。这使当时的人们对于最小二乘法有了更强的信心。
从这里可以看出,这种做法的逻辑是,首先认为算术平均这种做法好但不知道为什么,然后有人提出了一种衡量误差的方法(最小二乘法),接着对误差最小化求解后发现其解正是算术平均,所以肯定了最小二乘的有用性,但事实上却没有说清楚算术平均为什么好,反而用算术平均的结果来肯定了最小二乘法的作用。
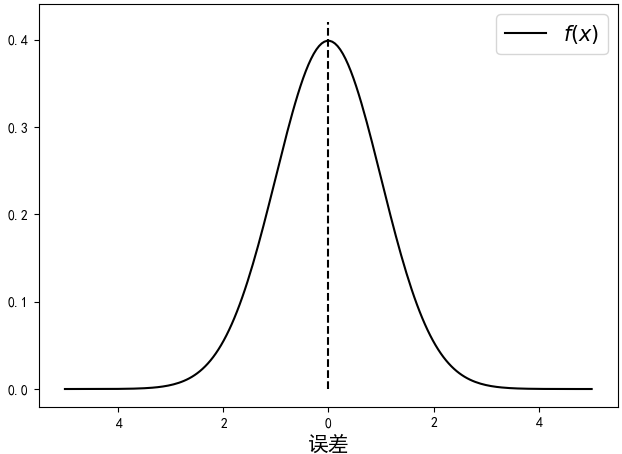
与此同时,伽利略在他著名的《关于两个主要世界系统的对话》中也对误差的分布做过一些定性的描述。这主要包括①误差是对称分布的;②大的误差出现频率低,小的误差出现频率高而这也很符合人们的认知常识。用数学的语言描述,也就是说误差分布函数$f(x)$关于$x=0$对称分布,概率密度函数$f(x)$随$x$增大而减小,如图2-15所示。于是许多天文学家和数学家开始了寻找误差分布曲线的尝试,但最终都没能给出有用的结果。
2.6.2 正态分布#
1801年1月,天文学家朱塞普·皮亚齐发现了一颗从未见过的光度为8等的星在移动,这颗现在被称作谷神星(Ceres)的小行星在夜空中出现了6个星期,扫过八度角后就在太阳的光芒下没了踪影而无法观测。由于留下的观测数据有限难以计算出它的轨迹,所以天文学家们也因此无法确定这颗新星是彗星还是行星。不过这个问题很快成了学术界关注的焦点。高斯当时已经是很有名望的年轻数学家了,这个问题引起了他的兴趣。高斯以其卓越的数学才能创立了一种崭新的行星轨道的计算方法,一个小时之内就计算出了谷神星的轨道,并预言了它在夜空中出现的时间和位置。1801年12月31日夜,德国天文爱好者奥伯斯,在高斯预言的时间里,用望远镜对准了这片天空,果然不出所料,谷神星出现了。
高斯为此名声大震,但是高斯当时拒绝透露计算轨道的方法,原因可能是高斯认为自己的方法理论基础还不够成熟。直到1809年高斯系统地完善了相关的数学理论后,才将他的方法公布于众,而其中使用的数据分析方法,就是以正态误差分布为基础的最小二乘法。那么高斯是如何推导出误差分布为正态分布的呢?
设真实值为$\theta$,${{x}_{1}},{{x}_{2}},...,{{x}_{n}}$分别为$n$次独立观测后的测量值 [2],并且每次测量的误差$e_i$的密度函数为$f(x)$,并直接把$n$个误差同时出现的概率记为
$$ L(\theta )=L(\theta ;x_{1},x_{2},...,x_{n})=f(e_{1})f(e_{2})\cdots f(e_{n})\tag{2-19} $$接着取使$L(\theta)$达到最大值时的$\hat{\theta}$作为$\theta$的估计值,即使式(2-20)成立时的$\hat{\theta}$值。
$$ L(\hat{\theta })=\arg \underset{\theta }{\mathop{\max }}\,L(\theta )\tag{2-20} $$现在我们把$L(\theta)$称为样本的似然函数,而得到的估计值$\hat{\theta}$称为$\theta$的极大似然估计(Maximum Likelihood Estimate,MLE)。在这里高斯首次给出了极大似然的思想,这个思想后来被统计学家费希尔系统地发展成为参数估计中的极大似然估计理论。同时,所谓极大似然估计是指在已知样本结果的情况下,推断出最有可能使该结果出现的参数的过程。也就是说极大似然估计一个过程,它用来估计出某个模型的参数,而这些参数能使已知样本的结果最可能发生。
接下来高斯把整个问题的思考模式倒了过来,既然千百年来大家都认为算术平均是一个好的估计,那就认为极大似然估计导出的就应该是算术平均,所以高斯猜测误差分布导出的极大似然估计就是算术平均值。然后高斯就开始去寻找满足这样条件的误差密度函数$f(x)$,即寻找这样的概率密度函数$f(x)$,使极大似然估计的结果正好是算术平均$\hat{\theta}=\overline{x}$。最后高斯应用数学技巧求解得到了这个函数$f(x)$,并证明在所有的概率密度函数中,唯一满足这个性质的就是
$$ f(x)=\frac{1}{\sqrt{2\pi }\sigma }{{e}^{-\frac{{{x}^{2}}}{2{{\sigma }^{2}}}}}\tag{2-21} $$其中$\sigma>0$为常数,而这也就是正态分布。
进一步,高斯基于这个误差密度函数对最小二乘法给出了一个漂亮的解释。对于最小二乘公式中涉及的每个误差$e_i$,由式(2-19)可知其对应的似然估计为
$$ L(\theta )=\prod\limits_{i=1}^{n}{f}({{e}_{i}})=\frac{1}{{{(\sqrt{2\pi }\sigma )}^{n}}}\exp \left\{ -\frac{1}{2{{\sigma }^{2}}}\sum\limits_{i=1}^{n}{e_{i}^{2}} \right\}\tag{2-22} $$而要使$L(\theta)$ 最大化,则必须使$\sum\nolimits_{i=1}^{n}{e_{i}^{2}}$取值最小,显然这正好就是最小二乘法的要求。可以看出,高斯这种做法的初始动机仍旧是以算术平均作为一种“公理”,然后以此为基础做出假设并找到一种符合人们常识的误差密度函数,即正态分布。最后通过极大似然估计来印证了最小二乘法。