7.6 CharRNN网络#
经过前面几节内容的介绍,我们已经清楚了RNN模型及其变体的相关原理,并且在7.2节内容中我们也通过两个实例详细介绍了RNN中多对一任务的构建流程。在本节内容中,我们将会以古诗词生成为例来介绍了RNN中的多对多任务类型,即图7-3中的第3种情况。
7.6.1 任务构造原理#
对于接下来要介绍的古诗生成模型其本质上就是一个简单的RNN模型,也被称为字符级循环神经网络CharRNN[1]。CharRNN通过将序列$t_1,t_2,...,t_{n-1},t_n$作为模型输入,将$t_2,t_3,...,t_n,t_{n+1}$作为标签来训练模型,整个网络结构如图7-14所示。
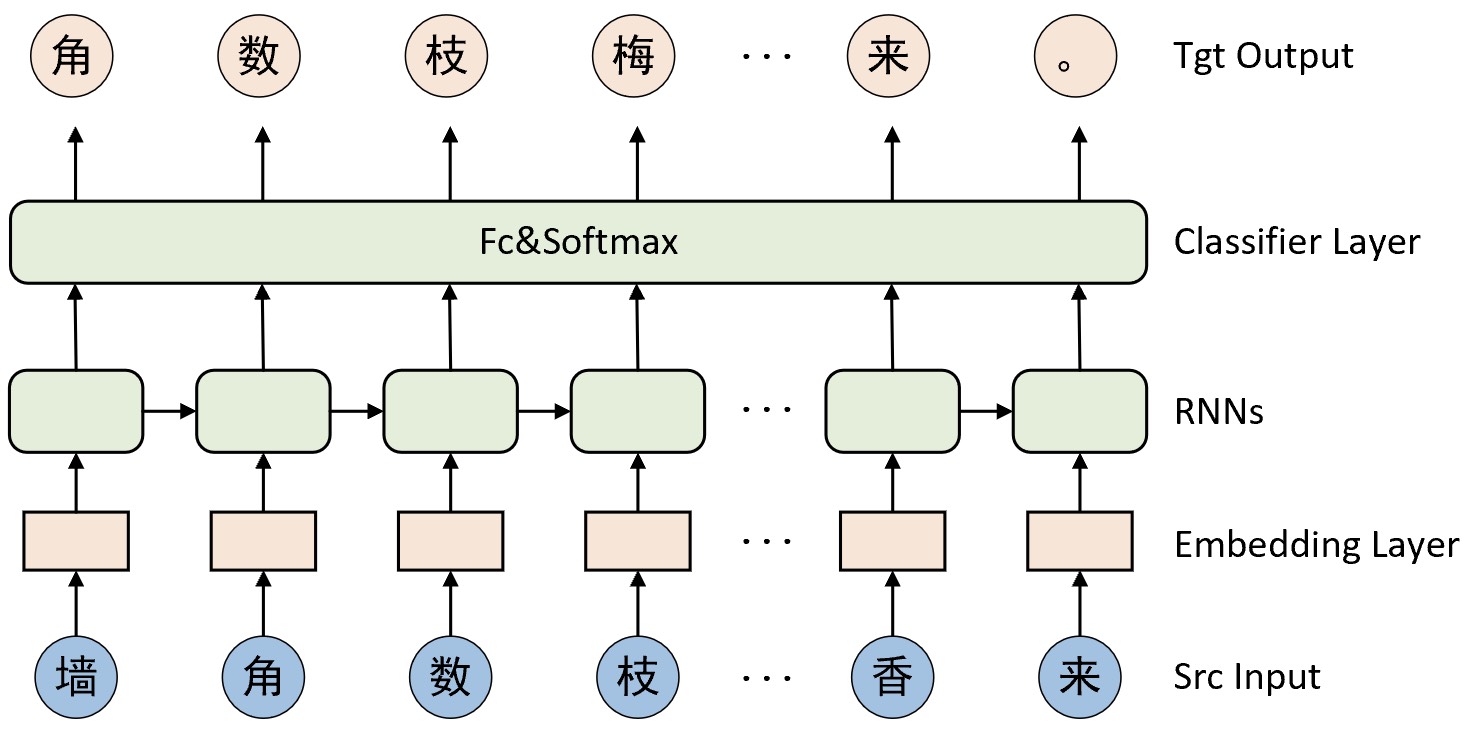
如图7-14所示,最下面为原始输入(Src Input),在转换为词表中的索引后便输入到词嵌入层(Embedding Layer)中。简单来讲,词嵌入层是一个包含有$m$行$n$列的网络层,其中$m$表示词表中词的数量,$n$表示向量的维度,即词嵌入层的作用是将词表中的每个词通过一个$n$维向量来进行表示。更多关于词嵌入层的内容将在9.5节中进行介绍。
在经过词嵌入层的处理之后再将该结果输入到循环神经网络中;然后再将循环神经网络输出结果中的每个时刻进行分类处理,并且因为这里的预测结果是词表中的其中一个词,所以其分类类别数便是词表的长度;最后将模型的预测结果同正确标签进行损失计算并完成整个模型的训练。
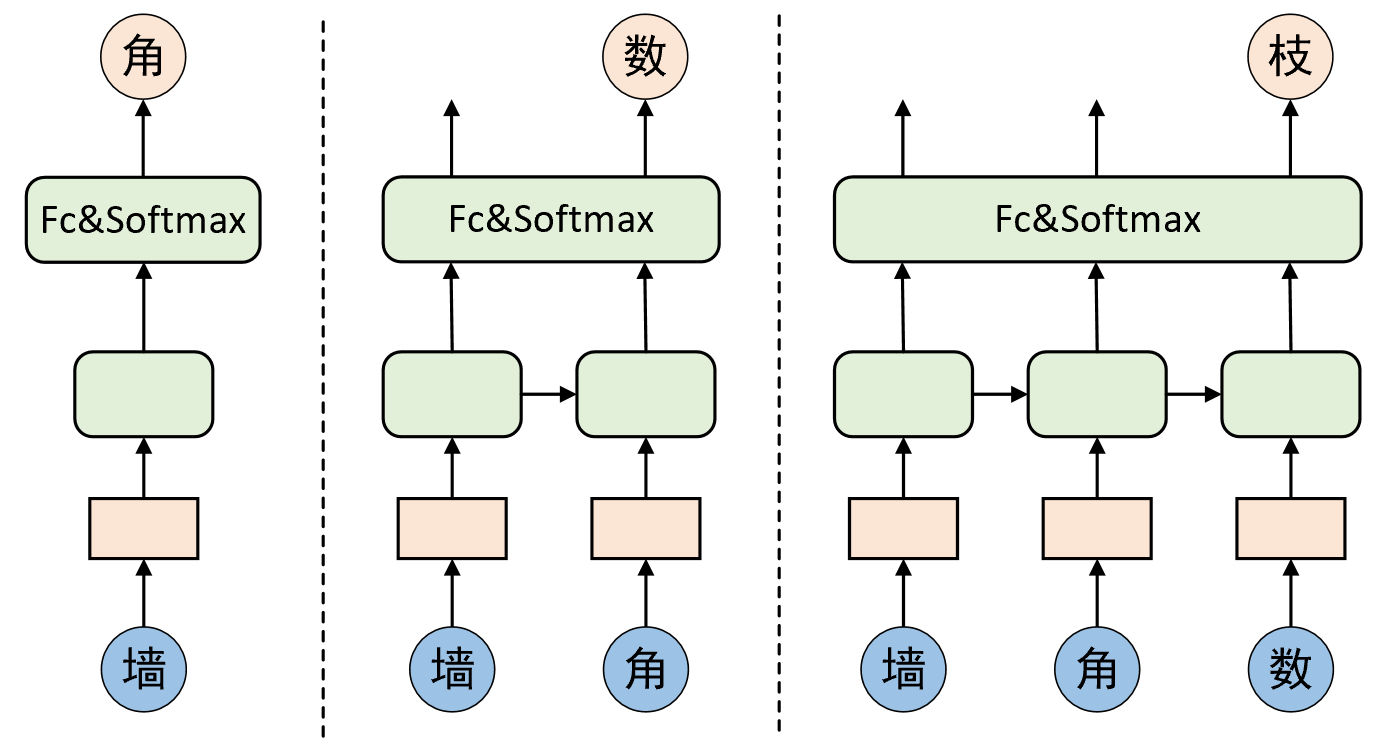
当模型训练完成之后,可以通过给模型输入一个序列片段来循环完成固定长度序列的生成任务,整个预测过程原理如图7-15所示。
7.6.2 数据预处理#
1. 数据集介绍
在清楚整个模型的训练和预测过程后,我们再来如何从零构建模型训练所需要的数据集。这里我们所使用到的是一个全唐诗[2]的数据集,一共有58个json文件共计大约5.8万余首古诗。在每个json文件中,文本内容的存储形式如下所示。
1 [{"author": "王安石",
2 "paragraphs": ["墙角数枝梅,凌寒独自开。","遥知不是雪,为有暗香来。"],
3 "title": "梅花",
4 "id": "ae7391fc-aef5-4f59-ae25-a7e7a9ee0858"},
5 {"author": "佚名",
6 "paragraphs": ["自伯东去,首如飞蓬。","岂无膏沐,谁适为容。"],
7 "title": "诗经·国风·卫风",
8 "id": "0f0b345d-c074-4ec7-bde1-e28438712b7b"}]从上述结果可以看出,整个json文件的最外层是一个列表,列表中的每个元素便是一个包含有一首古诗的字段,后续我们将只取每首古诗中的paragraphs来构建数据集。
2. 预处理流程
在正式介绍如何构建数据集之前我们先通过一张图了解一下整体的构建流程。假如现在有两个样本构成了一个小批量,那么其整个数据的处理流程如图7-16所示。
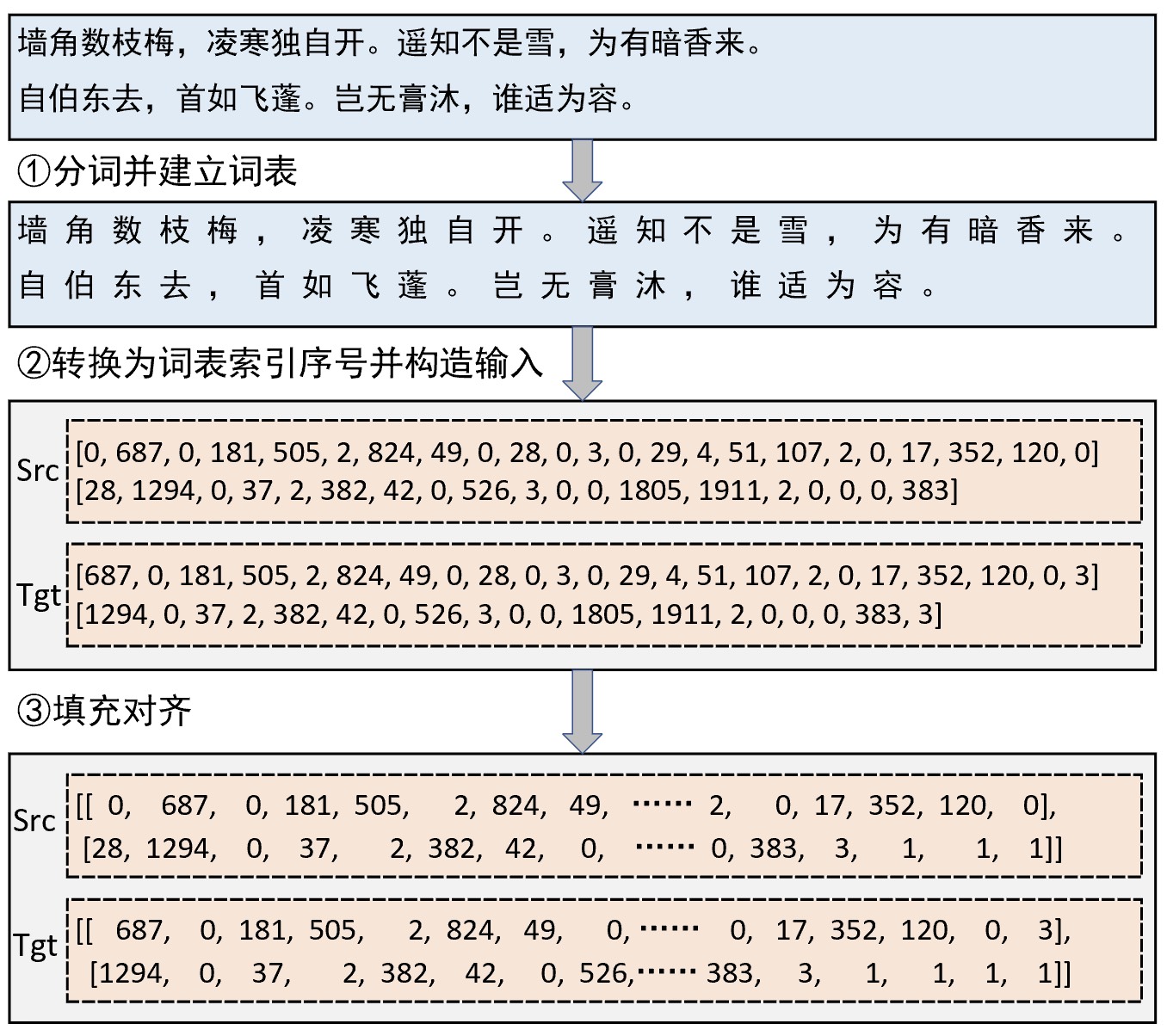
注:图7-16中的词表是以整个训练集为语料构建而成,并非只由上述两个样本构建,其中0表示['UNK'],1表示['PAD']。
如图7-16所示,首先我们需要将原始json格式的语料抽取出出来;然后再以此为基础对句子进行分词(字)并构建词表;接着再将样本句子中的每个词转换为词表中对应的索引序号得到原始输入Src,并同时将原始输入向左平移一位得到真实标签Tgt;最后在输入模型之前再对其进行填充处理以使得每个小批量中所有样本的长度一致。
3. 格式化样本和 Tokenize
首先,我们定义一个类TangShi并继承自在7.2.4节中介绍的TouTiaoNews类以复用其中的部分方法,同时初始化原始数据的相关存储路径,示例代码如下所示:
1 class TangShi(TouTiaoNews):
2 DATA_DIR = os.path.join(DATA_HOME, 'peotry_tang')
3 FILE_PATH = [os.path.join(DATA_DIR, 'poet.tang.0-55.json'),
4 os.path.join(DATA_DIR, 'poet.tang.56-56.json'),
5 os.path.join(DATA_DIR, 'poet.tang.57-57.json')]
6 def __init__(self, *args, **kwargs):
7 super(TangShi, self).__init__(*args, **kwargs)
8 self.ends = [self.vocab.stoi["。"], self.vocab.stoi["?"]]在上述代码中,第2行用来指定原始数据存储路径。第3~5行用来指定文件名并同时划分了训练集(poet.tang.0.json~poet.tang.55000.json)、验证集(poet.tang.56000.json~poet.tang.56000.json)和测试集(poet.tang.57000.json~poet.tang.57000.json),后续将解析其中的序号来读取相应的原始文件。第8行用来指定可能的结束符,用于生成序列时的停止条件之一。
进一步,定义load_raw_data方法来完成原始所有数据的载入,示例代码如下所示:
1 def load_raw_data(self, file_path=None):
2
3 def read_json_data(file_path):
4 samples, labels = [], []
5 with open(file_path, encoding='utf-8') as f:
6 data = json.loads(f.read())
7 for item in data:
8 content = "".join(item['paragraphs'])
9 if not skip(content):
10 samples.append(content[:-1])
11 labels.append(content[1:]) # 向左平移
12 return samples, labels
13
14 file_name = file_path.split(os.path.sep)[-1]
15 start, end = file_name.split('.')[2].split('-')
16 all_samples, all_labels = [], []
17 for i in range(int(start), int(end) + 1):
18 file_path = os.path.join(self.DATA_DIR, f'poet.tang.{i * 1000}.json')
19 samples, labels = read_json_data(file_path)
20 all_samples += samples
21 all_labels += labels
22 return all_samples, all_labels在上述代码中,第3~12行是定义一个辅助函数来读取单个的原始json文件,其中第9行为根据相应条件来判断是否将部分内容过滤,第10~11行是构造对应的输入和标签。第14~16行为根据传入的参数提取文件对应序号。第17~21行为根据拼接的文件名循环读取原始json文件。第22行为返回所有格式化后的结果。
在完成上述load_raw_data方法的实现之后,在实例化类TangShi时便可同时根据训练集完成词表的构建,详见7.2.4节中类TouTiaoNews的初始化方法。
4. 转换为索引
在完成词表构建之后,下一步则是需要将原始古诗进行分词处理,并将其转换为词表中对应的索引,示例代码如下所示:
1 def data_process(self, file_path):
2 samples, labels = self.load_raw_data(file_path)
3 data = []
4 for i in tqdm(range(len(samples)), ncols=80):
5 x_tokens = tokenize(samples[i])
6 x_token_ids = [self.vocab[token] for token in x_tokens]
7 y_tokens = tokenize(labels[i])
8 y_token_ids = [self.vocab[token] for token in y_tokens]
9 x_token_ids_tensor = torch.tensor(x_token_ids, dtype=torch.long)
10 y_token_ids_tensor = torch.tensor(y_token_ids, dtype=torch.long)
11 data.append((x_token_ids_tensor, y_token_ids_tensor))
12 return data在上述代码中,第2行便是得到分词后的原始古诗句子和对应的标签。第5行是对输入部分的句子进行分词处理。第6行是将分词后的输入转换为词表中对应的索引。第9行则是将索引ID转换为张量类型。第11~12行是保存处理好的每个样本并返回最后的结果。
到此,对于前面两个样本来说,经过data_process方法处理后便会得到如下所示结果:
1 ## 原始样本为:
2 ## 输入为: 墙角数枝梅,凌寒独自开。遥知不是雪,为有暗香来
3 ## 分割后为: ['墙', '角', '数', '枝', '梅', ',', '凌', '寒', '独', '自', '开', '。',
4 ## '遥', '知', '不', '是', '雪', ',', '为', '有', '暗', '香', '来']
5 ## 向量化后为: [0, 687, 0, 181, 505, 2, 824, 49, 0, 28, 0, 3, 0, 29, 4, 2, 0, 17, 352, 120, 0]
6 ## 标签为: 角数枝梅,凌寒独自开。遥知不是雪,为有暗香来。
7 ## 分割后为: ['角', '数', '枝', '梅', ',', '凌', '寒', '独', '自', '开', '。',
8 ## '遥', '知', '不', '是', '雪', ',', '为', '有', '暗', '香', '来', '。']
9 ## 向量化后为: [687, 0, 181, 505, 2, 824, 49, 0, 28, 0, 3, 0, 29, 4, 2, 0, 17, 352, 120, 0, 3]
10 ... 5. 填充对齐