第 1 章 RAG 基础概念#
大型语言模型 (Large Langage Model, LLM))通过大量但固定的语料训练而来,这限制了它们对私有信息或最新信息进行推理的能力。微调是缓解这一问题的一种方法,但通常不适合事实性信息的处理而且成本相对高昂。在这样的背景下,检索增强生成 (Retrieval Augmented Generation, RAG) 便逐渐成为了一种主流且强大的机制。 RAG 利用从外部数据源检索到的文档作为知识库,通过上下文学习来增强 LLM 的生成能力。
1.1 RAG 提出背景#
1.1.1 大模型的局限#
很多人第一次把大模型接入业务时,都会有一种错觉:“模型这么强,只要把问题问清楚,它应该什么都能答对吧?”但现实往往是——模型回答得很自信,却经常都是错的,这就是大家常说的,一本正经地胡说八道。
例如你问大模型:某某公司 2026 年的差旅报销标准是多少?
这个时候模型便会根据自己固有的知识来进行回答,并且回答通常具备三个特点:①语言非常专业;②逻辑非常完整;③ 但内容完全不对。这时候很多人的第一反应是:是不是提示词写得不够好?是不是模型还不够大?要不要再多试几次?
但问题其实不在你,也不在模型,而是在于一个非常重要、但经常被忽略的事实是:大模型不是数据库,也不是搜索引擎。你可以把它理解为:一个读过大量书籍的人,但在回答问题时,不能临时翻书,只能依赖“记忆中最像的内容”来作答。
这会带来3个天然限制:
① 知识是静态的:模型一旦训练完成,它的知识就冻结了,它不知道你公司昨天刚更新了一版制度。
② 不知道你的私有数据:公司内部文档、业务规则、技术细节模型在训练时根本没见过,所以自然也就无法准确回答。
③ 会生成“听起来很合理的错误答案”:因为它的目标是“生成最可能的文本”,而不是“返回真实存在的资料”。
所以,这也是为什么大模型的幻觉不是缺陷,而是结构性问题。
1.1.2 RAG 出现的动机#
很多人此时会想到一个看似合理的方案:“那我把公司数据拿去模型微调不就行了?”听起来很对,但在大多数知识型场景下,并不合适。
原因很简单,微调并不能让模型“学会查文档”、它只是让模型更倾向于某种回答风格。并且更关键的是数据一变就要重新训练,不仅成本高、而且周期长,这并不适合制度、文档、FAQ 这类高频变动内容。一句话总结就是:微调解决的是“怎么回答”,但解决不了“基于什么资料回答”。
讲到到这里,其实我们的需求已经非常清晰了,我们不是想让模型“记住所有内容”,而是希望它——在回答之前,先去查一查真正的资料,这正是 RAG 检索增强生成的核心思想。
一句话,RAG 等于先检索相关资料,然后再让大模型生成答案。你可以把它理解为一个非常人类化的过程:例如新人客服回答问题前会先查知识库,技术支持工程师解决问题前会先翻文档,最后再用自己的语言把答案组织出来。如图1-1所示,便是最基础的一个 RAG 处理流程。
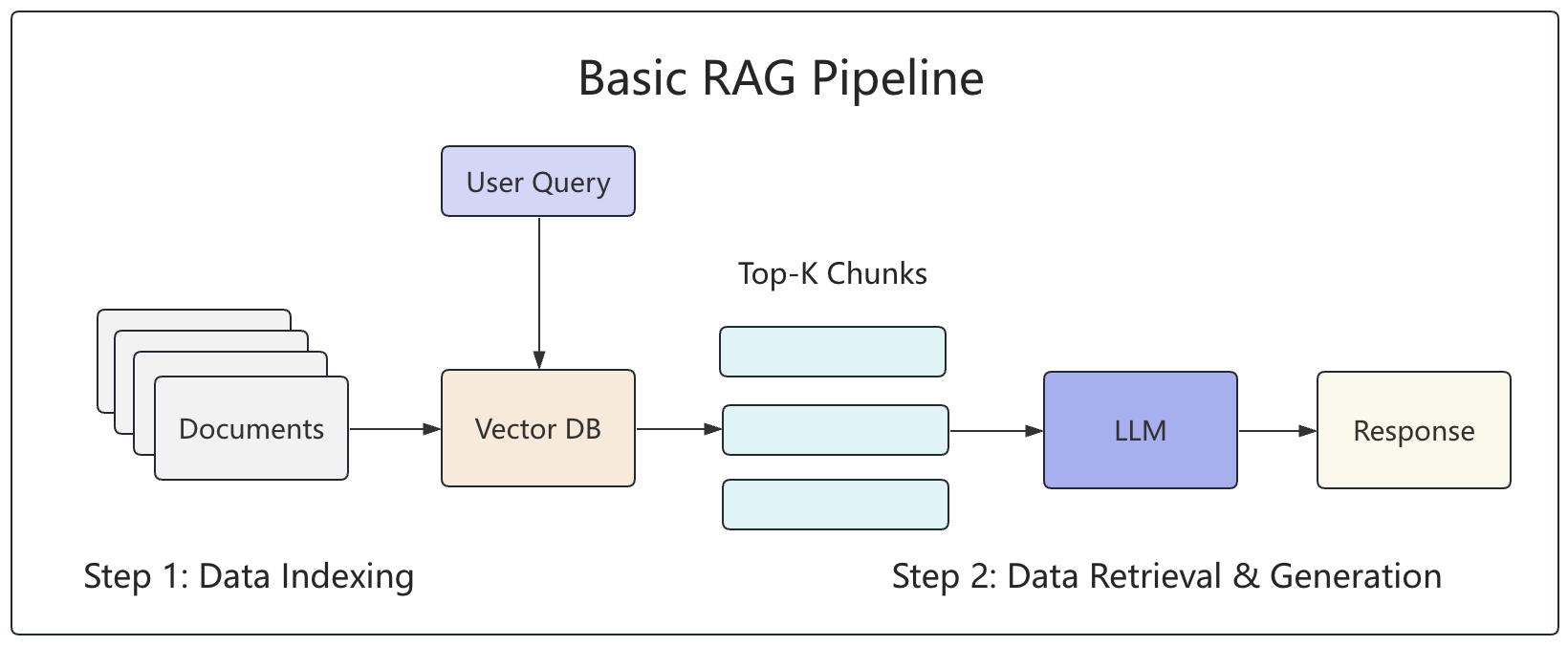
根据图1-1可以知道,大模型在回答用户之前都会向量库中检索与用户请求相关的文本资料,让后将其与用户请求一起喂给大模型,最后大模型再基于参考内容给出正确的回答。
1.1.3 RAG 的能力#
一旦引入 RAG大模型的角色就发生了变化,此时大模型不再凭“记忆”作答而是基于真实存在的文档进行回答。正因如此,这让它在很多场景中真正变得可用,例如:企业内部制度 、流程问答、技术文档、API 文档助手、私有知识库 、智能问答系统等。
当然,更重要的是回答内容可以追溯来源,错了能定位是哪份文档的问题,进而降低“模型胡说”的情况。所以可以用一句话概括 RAG 的价值,RAG 让大模型第一次真正站在你的数据上说话。