8.6 STResNet网络#
在前面几节内容中, 我们陆续介绍了多种通过结合CNN和RNN的模型来对时序数据进行建模,并且从第8.4节内容开始还首次引入了基于时空数据相关任务。不管是8.4节中介绍的ConvLSTM模型还是8.5节中引入的3DCNN模型,为了能同时提取时空数据在时间和空间两个维度的特征信息均从模型本身进行了改进。在本节内容中,我们将会介绍一种通过改进任务建模方式而仅依靠2DCNN来进行时空数据特征提取的模型,并同时介绍如何对多个子模块的输出结果进行融合。
8.6.1 STResNet动机#
尽管已有的时序模型例如3DCNN或者是ConvLSTM也能够用于提取时空数据在时间和空间两个维度上的特征信息,但是在流量预测这个场景中却不能有效得捕捉到在时间维度上的周期或者是趋势信息。例如在交通流量这一场景中,传统的时序模型只能提取到时空数据在紧邻若干时间内容的时序信息,但显然在这个场景中交通流量还具有周期规律或者趋势性。
通常来说,交通流量数据在相邻时刻间、连续多天的同一时间段以及在长期趋势上都具有一定的规律性。同时,在这一场景中当天是否为节假日也会对交通流量的预测结果产生极大的影响。
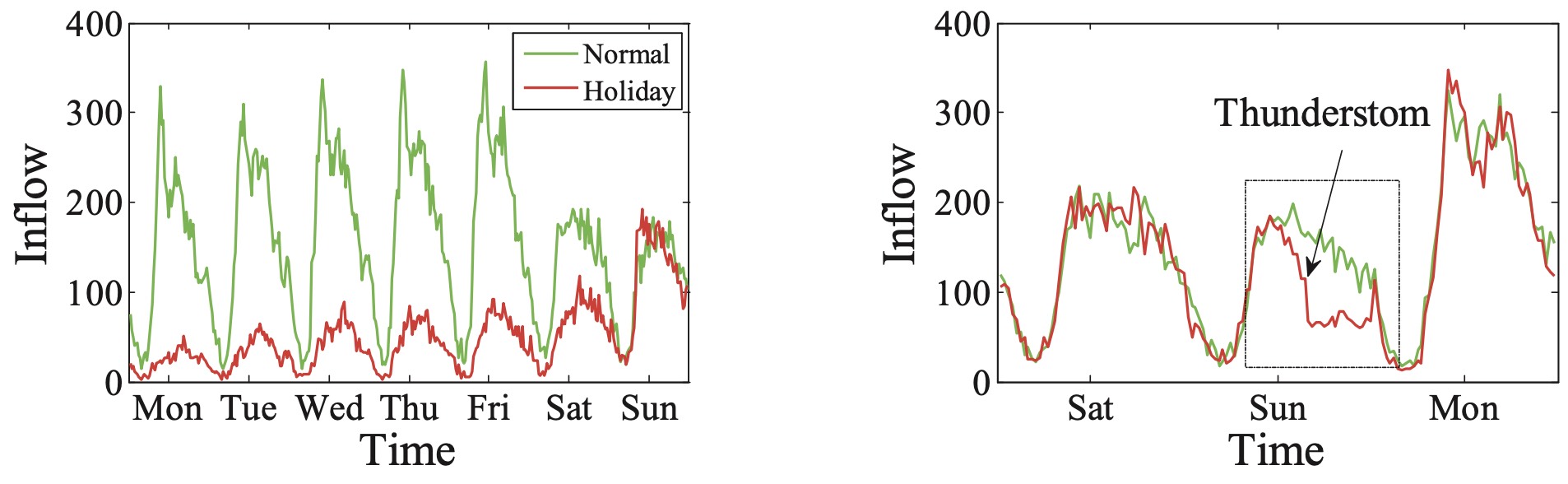
如图8-13所示,左图展示了以周为单位节假日和非节假日的流量变化图;右图展示了以周为单位不同时间段的流量变化趋势。从图8-13中的结果可以看出,不管在哪种情况下流量数据都具有一定的周期或者规律性。
基于这样的动机,郑宇[1]等人在2017年提出了一种能够同时提取时空数据在邻近性(Closeness )、周期性(Period)和趋势性(Trend)上的时序特征,并同时考虑到节假日及天气状况等额外信息的时空模型(Spatio Temporal ResNet, STResNet)。该模型以残差模块为基础,通过构建不同的子模块来对不同的采样数据进行特征提取,然后再将各个模块的结果进行融合以实现上述目的。
8.6.2 任务背景#
1. 任务介绍
交通流量(Traffic Flow)预测任务是指使用历史数据和其他相关信息来预测特定区域或道路上未来的交通流量情况。它的目标是估计未来某一时间段内的车辆数量、速度和拥堵状况等交通指标,并且通常可以通过交通传感器、视频监控、GPS设备、移动应用程序等方式获取交通流量原始数据。在论文[1]中,作者使用了GPS原始数据来构建对应的数据集并用于模型训练。
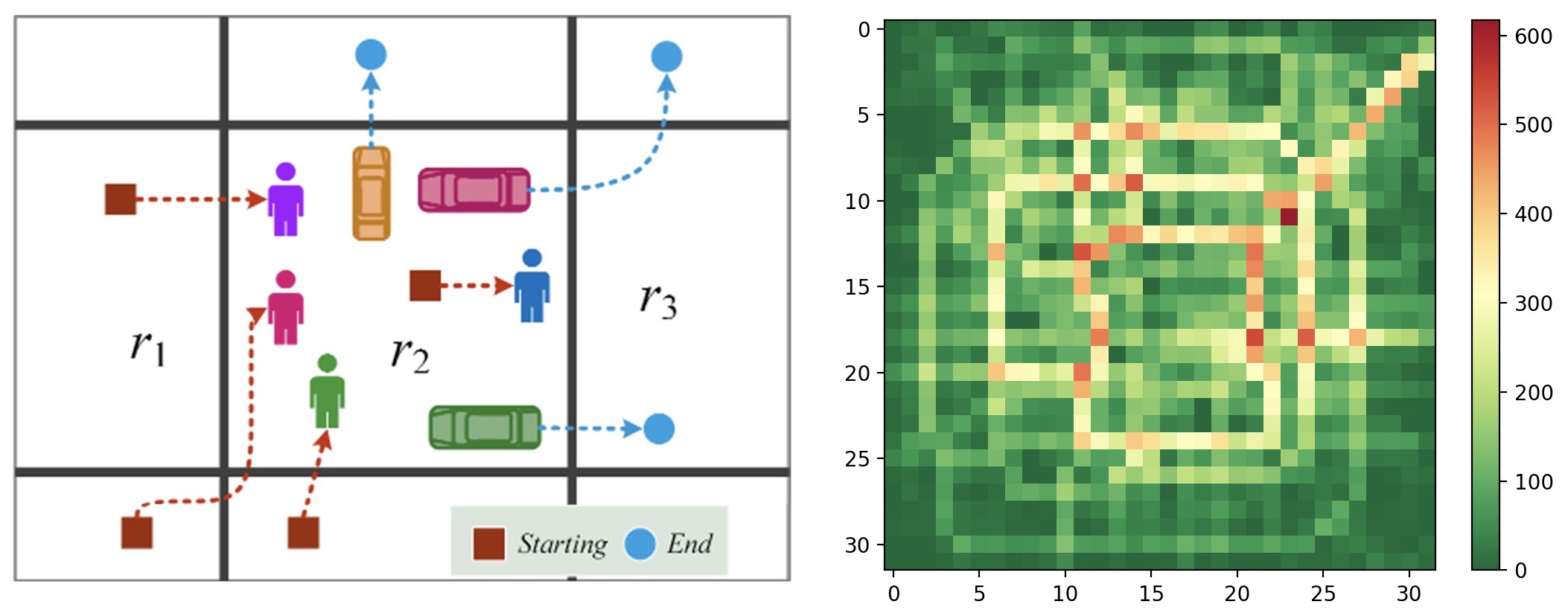
如图8-14(左)所示,将整个城市以经纬度划分为大小为$32\times32$的方格,然后再根据GPS轨迹以半小时为间隔统计得到每个格子中的流入流出量并看做是两个通道,这样便得到了整个城市各个区域在每个时刻的流量分布情况。进一步,图8-14(右)便是某一时刻的流入交通流量分布情况。经过这样的处理,我们便得到了一系列具有时序关系的图片数据,而任务的目的便是将前$T$个时间片(时刻)的流量作为输入,然后预测第$T+1$时刻的流入流出流量。
2. 样本采样
为了使得STResNet模型具备提取时空数据在时间维度上的近邻性、周期性和趋势性,作者以不同的时间间隔对原始数据进行了采样,然后再将这3部分采样得到的数据输入到3个由残差网络构建的子模型中进行空间上的特征提取,并将三部分的输出融合作为整体的特征表示。具体采样方式如图8-15所示。
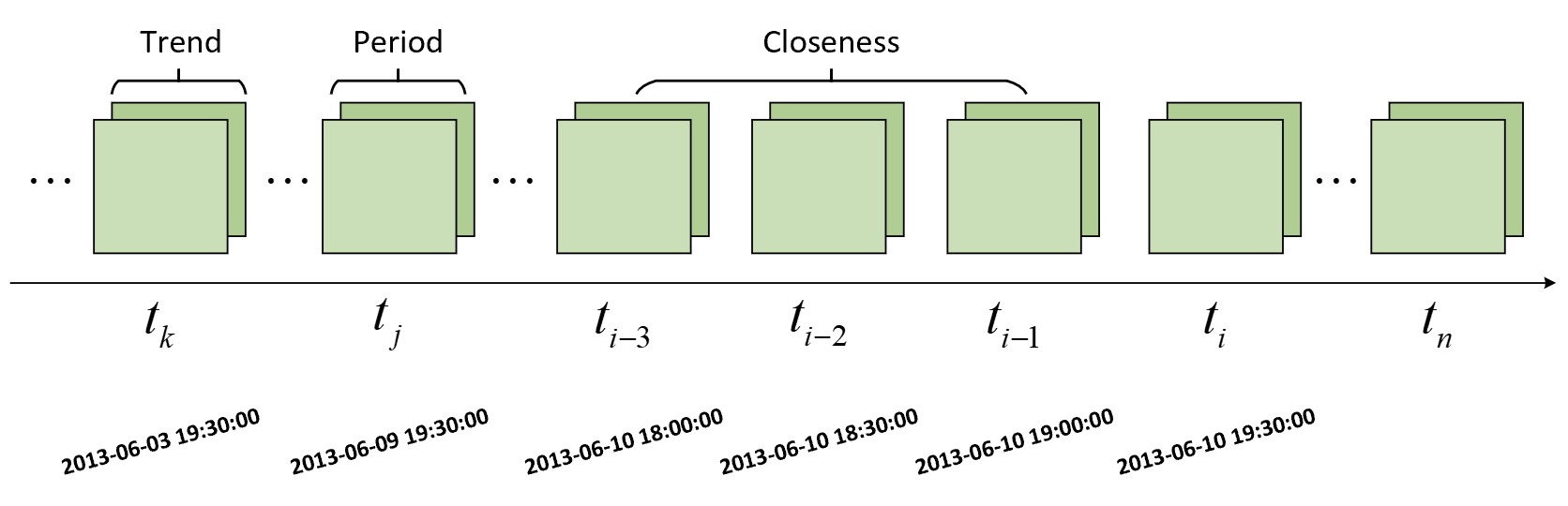
如图8-15所示便是原始构建完成的流量数据,每个时间片的流量情况用一个形状为[2,32,32]的矩阵来进行表示。例如以预测时刻片$t_i$的流量为例,可以取$t_i$的前3个时间片$t_{i-1},t_{i-2},t_{i-3}$来模拟邻近性、取$t_{i}$前一天同时刻的时间片$t_j$来模拟周期性、取$t_i$前一周同时刻的时间片$t_k$来模拟趋势性,并将这3部分作为一个样本同时输入到3个子模块中。最后,再将窗口向右滑动一个时间片来构建下一个样,即$t_i,t_{i-1},t_{i-2}$作为近邻性的输入、$t_{j+1}$作为周期性的输入、$t_{k+1}$作为趋势性的输入,然后预测第$t_{i+1}$时刻的交通流量。当然,这3部分的采样方法以及连续时间片的长度都可以作为超参数进行调整,详见第8.6.4节代码实现。
同时,为了考虑到其它额外因素对最终预测结果的影响,因此作者:①使用了一个8维向量来表示当天是否为工作日,其中前7个维度为独热编码表示当天是星期几,第8个维度表示当天是否为工作日;②使用了一个维度来表示当天是否为节假日;③使用了一个19维向量来表示天气状况,其中前17个维度同样也为独热编码用于表示其中一种天气情况,最后两个维度则表示风速和温度。最终,用这个28维向量来表示除了流量数据之外的额外因素。
8.6.3 STResNet结构#
1. 整体结构
在介绍完任务背景之后接下来开始介绍STResNet模型的原理。STResNet模型整体上可以分为4个部分,其中前3个部分以不同间隔采样的流量数据作为输入通过3个深度残差网络子模块来提取时空数据在时间维度和空间维度上的特征信息,第4个部分则是一个浅层的全连接网络用于考虑节假日和天气等因素对预测结果的影响。整体结构如图8-16所示。
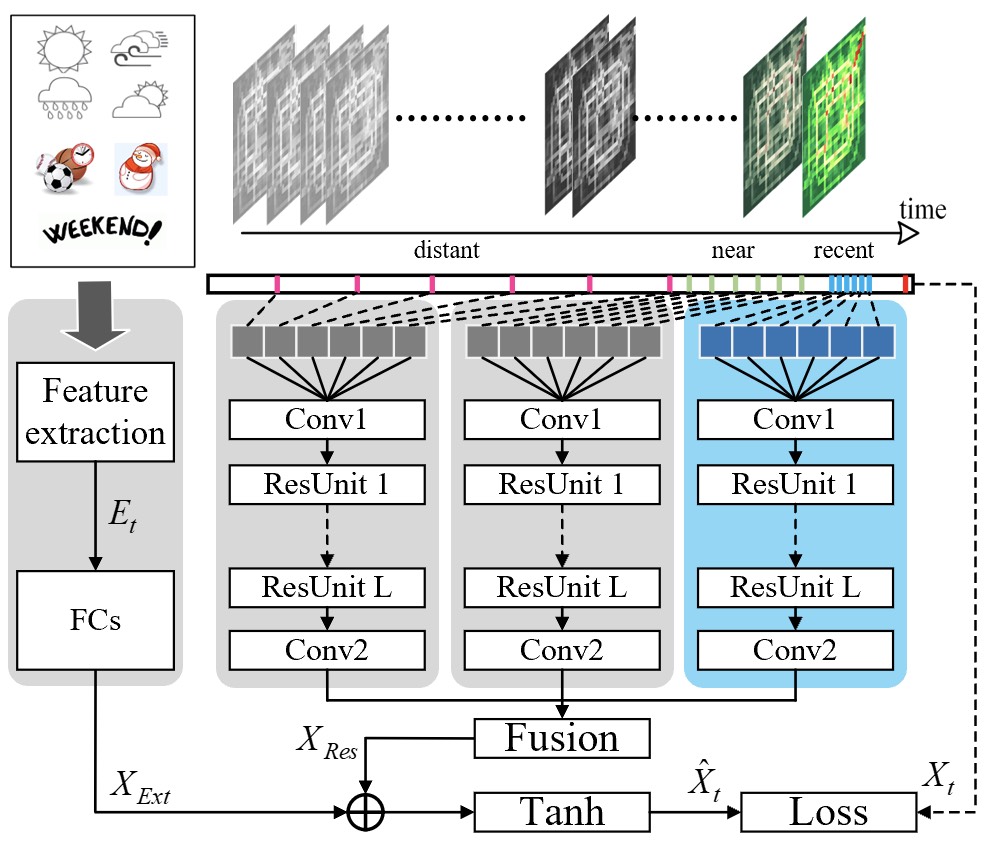
如图8-16所示,右侧部分3个相同的结构便是用于提取时刻数据特征的深度残差网络模块,从右至左依次用于对邻近性、周期性和趋势性采样数据在空间上特征提取,然后再将这3部分的结果融合得到流量数据在时间上的特征信息,从而得到$X_{\text{Res}}$来表征整体流量数据的时空特征信息。左侧部分则是用于处理天气等额外信息对预测结果的影响。最终,将两部分的结果相加经过$\tanh$非线性变换后便得到了整个模型的预测输出。
2. 残差模块
深度残差模块主要由多个残差单元所构成,并且首尾各插入了一个单独的卷积层来调整特征图的通道数。对于每一个残差单元来说,其由两个卷积层所构成并且还加入了批归一化层,如图8-17所示。
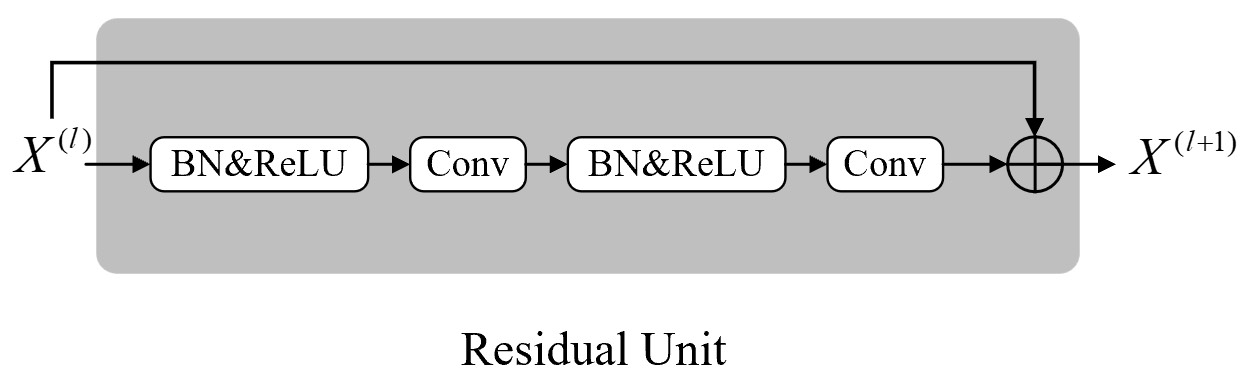
如图8-17所示便是STResNet模型中的残差单元。在整个残差模块中,卷积核的大小均是$3\times3$,且除了Conv2之外所有卷积层的卷积核个数均为64,Conv2的卷积核个数则为2,因为预测输出包含两个通道。
3. 模型融合
对于每个残差模块来说,其输出的结果均为一个形状为[2,32,32]的特征图,因此作者采用了式(8-4)所示的方式进行融合
其中$X_c$、$X_p$和$X_q$分别为3个残差模块的输出结果,$W_c$、$W_p$和$W_q$为3个可学习的权重矩阵形状均为[2,32,32],$\odot$表示按位乘。
在对外部因素进行处理时使用了两个全连接层,由于这部分原始输入整体上是由独热编码构成,所以第1个全连接层还可以近似看成一个嵌入层。为了匹配最后的输出形状,在第2个全连接层中权重参数的维度则必须为$2\times32\times32$,然后再将输出$X_{\text{Ext}}$变形为[2,32,32]并直接与$X_{\text{Res}}$按位相加得到融合后的结果。最后,为了使得模型能够快速收敛作者还使用了$\tanh$非线性变换,这也就意味着输入模型的交通流量数据需要先做$[-1,1]$的标准化,然后在实际推理过程中再将预测结果还原,计算过程如式(8-6)所示。
对于不同模块间输出结果的融合一般常见的有:①在某个维度进行拼接;②直接以按位加的方式进行处理;③先以按位乘的方式作用一个可学习的权重参数再进行按位加处理;④先以矩阵乘法的方式将不同模块的输出变换到同一个维度再按位加处理。通常来说,先作用一个可学习参数再进行按位加是一个比较好的选择。
最后,由于STResNet模型完成的是一个回归任务,因此选择了均方误差作为整体的目标函数,如式(8-7)所示。
$$ \begin{aligned} \mathcal{L}(\theta) &= \|X_t-\hat{X}_t\|^2_2,\\[2ex]\hat{X}_t&=\tanh(X_{\text{Res}}+X_{\text{Ext}}) \end{aligned}\tag{8-7} $$其中$X_t$和$\hat{X}_t$分别表示第$t$时刻的真实值和预测值。
8.6.4 数据集构建#
在原始数据集中一共包含有6个文件,分别是BJ_Holiday.txt、BJ_Meteorology.h5、BJ13_M32x32_T30_InOut.h5、BJ14_M32x32_T30_InOut.h5、BJ15_M32x32_T30_InOut.h5和BJ16_M32x32_T30_InOut.h5,其中第1个是节假日信息,第2个是气象信息,最后4个则是交通流量数据。下面我们开始简单介绍一下整个数据集的构建流程,以下完整示例代码及注释可以参见[Code/utils/data_helper.py`文件。
1. 读取原始数据
在清楚数据集的相关信息后进一步便可以编码读取并进行相关的预处理工作。首先我们需要先定义一个类并完成其初始化函数的构造,示例代码如下所示:
1 class TaxiBJ(object):
2 DATA_DIR = os.path.join(DATA_HOME, 'TaxiBJ')
3 FILE_PATH_FLOW = [os.path.join(DATA_DIR, 'BJ13_M32x32_T30_InOut.h5'),
4 os.path.join(DATA_DIR, 'BJ14_M32x32_T30_InOut.h5'),
5 os.path.join(DATA_DIR, 'BJ15_M32x32_T30_InOut.h5'),
6 os.path.join(DATA_DIR, 'BJ16_M32x32_T30_InOut.h5')]
7 FILE_PATH_HOLIDAY = os.path.join(DATA_DIR, 'BJ_Holiday.txt')
8 FILE_PATH_METEORO = os.path.join(DATA_DIR, 'BJ_Meteorology.h5')
9 CATH_FILE_PATH = os.path.join(DATA_DIR, 'TaxiBJ.pt')
10
11 def __init__(self, T=48, nb_flow=2, len_test=None, len_closeness=None,
12 len_period=None, len_trend=None, meta_data=True,meteorol_data=True,
13 holiday_data=True, batch_size=4, is_sample_shuffle=True):
14 self.T = T
15 self.nb_flow = nb_flow
16 self.len_test = len_test
17 self.len_closeness = len_closeness
18 self.len_period = len_period
19 self.len_trend = len_trend
20 self.meta_data = meta_data
21 self.meteorology_data = meteorol_data
22 self.holiday_data = holiday_data在上述代码中,第2~9行用于定义数据集的目录和文件名以及缓存文件的文件名。第11~22行则是定义相关构造数据集时的超参数。
接着,分别定义3个类方法来载入节假日数据、气象数据和流量数据。对于节假日数据来说,其载入方法如下所示:
1 def load_holiday(self, timeslots=None):
2 filepath = self.FILE_PATH_HOLIDAY
3 with open(filepath, 'r') as f:
4 holidays = f.readlines()
5 holidays = set([h.strip() for h in holidays])
6 H = np.zeros(len(timeslots))
7 for i, slot in enumerate(timeslots):
8 if slot[:8] in holidays:
9 H[i] = 1
10 return H[:, None] 在上述代码中,第1行timeslots是表示日期的时间戳,如['2014120106','2014120206']。第3~5行是读取原始节假日信息文件并进行去重,最终将得到一个假期列表,形如:['20130101','20130102','20130103','20130209', ...]。第6~9行则是遍历timeslots中的每个时间戳并取前8位为日期,判断其是否为节假日。最后,第10行将会返回得到一个形状为[n,1]且仅包含0和1取值的列向量。
例如对于时间戳来说:
1 load_holiday(timeslots=['2014120106','2014120206','2014010106','2014120706'])