8.3 CNN-RNN网络#
在前面两节内容中,我们分别介绍了通过CNN和RNN来对文本数据进行特征提取的建模方法,前者是从序列局部的角度来捕捉文本序列前后之间的依赖关系,而后者则是利用了RNN固有的特性来对序列数据进行特征提取。总的来说两者各有优势,在提取特征方面有不同的侧重点,因此把CNN和RNN模型进行组合也成为了一种非常流行的做法[1] [2] [3] [4] [5] [6]。
在本节内容中我们将会详细介绍两种以CNN和RNN为基础模块的CNN-RNN模型,即:①以先CNN再RNN的顺序对时序数据进行特征提取[1] [2];②以先RNN再CNN的顺序进行[3] [4] [5]。
8.3.1 C-LSTM结构#
从名字也可以看出C-LSTM模型是以先CNN再RNN的顺序对时序数据进行特征提取。C-LSTM模型的核心思想在于先利用CNN局部特征提取的能力来抽取文本中短语粒度的特征表示,然后再利用LSTM对卷积后的特征图进行时序上的语义理解,最后得到整个文本的特征表示[1]。如图8-3所示便是C-LSTM模型对应的网络结构图。
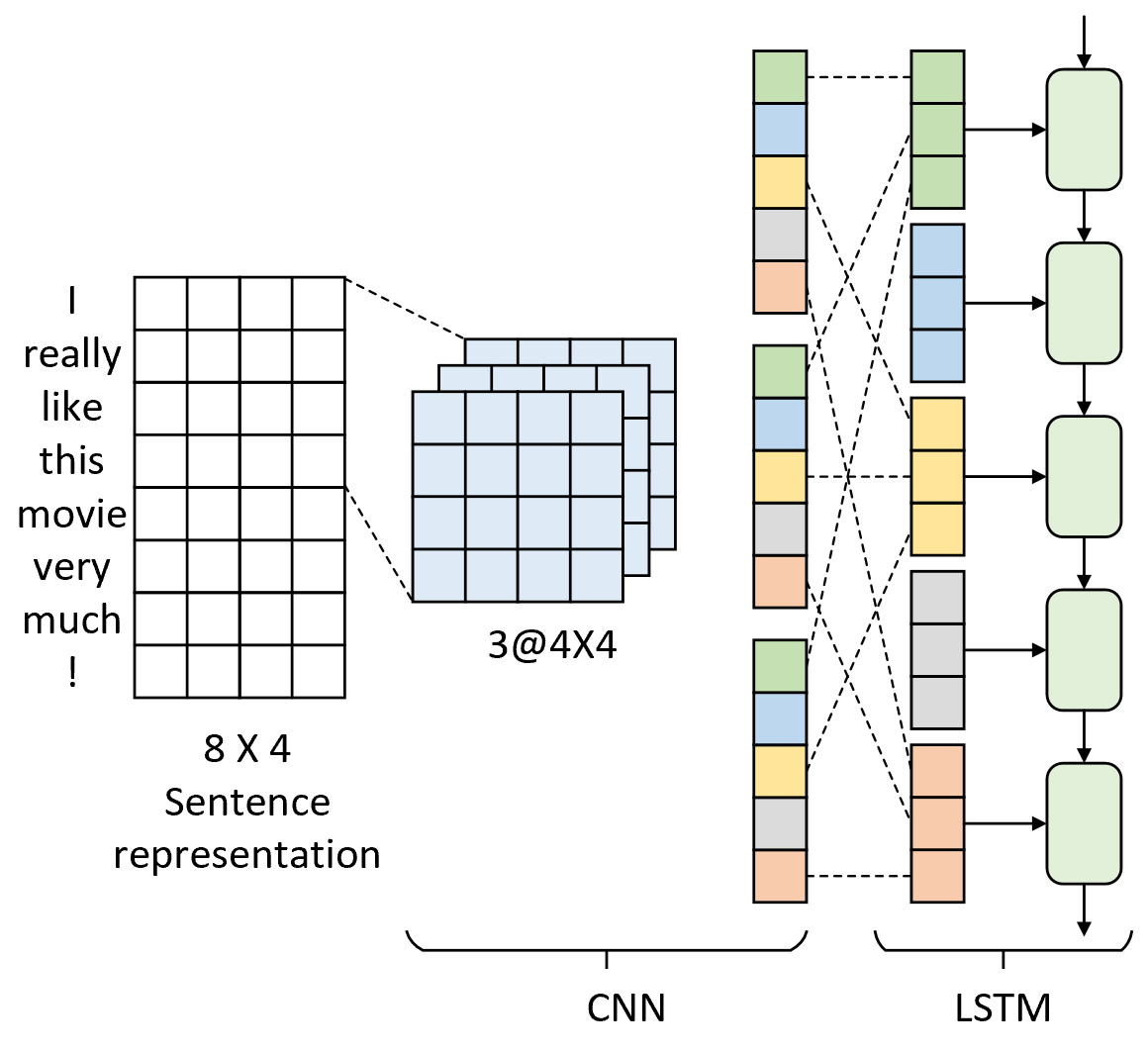
如图8-3所示,最左侧为一个$8\times4$的特征矩阵,其含义同8.1.1节中的一致,这里不再赘述。进一步,C-LSTM模型采用了多卷积核卷积对其进行局部特征提取,这可以看作是短语层面的语义信息。此时得到的特征图有两方面的含义:①对于特征图的每一行(即每次卷积窗口滑动后计算得到的结果)来说它表示的仍旧是具有前后时序关系的序列特征,只是获得的更大粒度的语义信息;②对于特征图的每个通道来说可以看作是同一时刻多个维度的语义信息。因此,C-LSTM模型最后会对卷积后的结果进行重构并作为LSTM的输入进行时序上的特征提取。
除此之外,类似的还有CNN-LSTM模型[2],其结构整体上与C-LSTM类似,仅仅只是在CNN处理后还加入了一个特定的池化层。
8.3.2 C-LSTM实现#
在清楚C-LSTM模型的相关原理后,我们再来看如何借助PyTorch实现该模型。 以下完整示例代码可以参见Code/Chapter08/C03_CLSTM/CLSTM.py文件。
1. 前向传播
首先实现模型的整个前向传播过程。从图8-3可知,整个模型整体分为4个大的部分,词嵌入层、卷积层和循环神经网络层以及后续的分类层,实现代码如下所示:
1 class CLSTM(nn.Module):
2 def __init__(self, config):
3 super(CLSTM, self).__init__()
4 if config.cell_type == 'RNN':
5 rnn_cell = nn.RNN
6 elif config.cell_type == 'LSTM':
7 rnn_cell = nn.LSTM
8 elif config.cell_type == 'GRU':
9 rnn_cell = nn.GRU
10 else:
11 raise ValueError("Unrecognized RNN cell type: " + config.cell_type)
12 out_hidden_size = config.hidden_size * (int(config.bidirectional) + 1)
13 self.config = config
14 self.token_embedding = nn.Embedding(config.vocab_size, config.embedding_size)
15 self.conv = nn.Conv2d(1, config.out_channels,
16 kernel_size=(config.window_size, config.embedding_size))
17 self.rnn = rnn_cell(config.out_channels, config.hidden_size, config.num_layers,
18 batch_first=True, bidirectional=config.bidirectional)
19 self.classifier = nn.Sequential(nn.Linear(out_hidden_size, config.num_classes))在上述代码中,第4~11行是根据对应的参数返回相应的循环记忆单元。第12行是计算循环神经网络输出结的维度,即在双向结构中该维度为单向结构的2倍,具体可参见7.5.3节内容。第14行是实例化得到一个词嵌入层。第15~16行是实例化得到一个卷积层。第17~18行是根据对应参数实例化得到循环记忆单元。第19行则是由一个全连接构成的分类层。
进一步,整个前向传播计算过程的示例代码如下所示:
1 def forward(self, x, labels=None):
2 x = self.token_embedding(x)
3 x = torch.unsqueeze(x, dim=1)
4 feature_maps = self.conv(x).squeeze(-1)
5 feature_maps = feature_maps.transpose(1, 2)
6 x, _ = self.rnn(feature_maps)
7 if self.config.cat_type == 'last':
8 x = x[:, -1]
9 elif self.config.cat_type == 'mean':
10 x = torch.mean(x, dim=1)
11 elif self.config.cat_type == 'sum':
12 x = torch.sum(x, dim=1)
13 else:
14 raise ValueError("Unrecognized cat_type: " + self.cat_type)
15 logits = self.classifier(x)
16 if labels is not None:
17 loss_fct = nn.CrossEntropyLoss(reduction='mean')
18 loss = loss_fct(logits, labels)
19 return loss, logits
20 else:
21 return logits