3.2 多分类任务#
3.2.1多分类逻辑回归#
在3.1节中对于逻辑回归的介绍都仅仅局限在二分类任务中,但是在实际任务里,更多则是多分类的任务场景,也就是说最终的分类结果中类别数会大于2。对于这样的问题该如何解决呢?
通常情况下在用逻辑回归处理多分类任务时,都会采用一种称为One-vs-all(也叫作 One-vs-rest)的方法,两者的缩写分别为ova与ovr。这种策略的核心思想就是每次将其中一个类和剩余的其他类看作一个二分类任务进行训练,最后在预测过程中选择输出概率值最大那个类作为该样本点所属的类别。
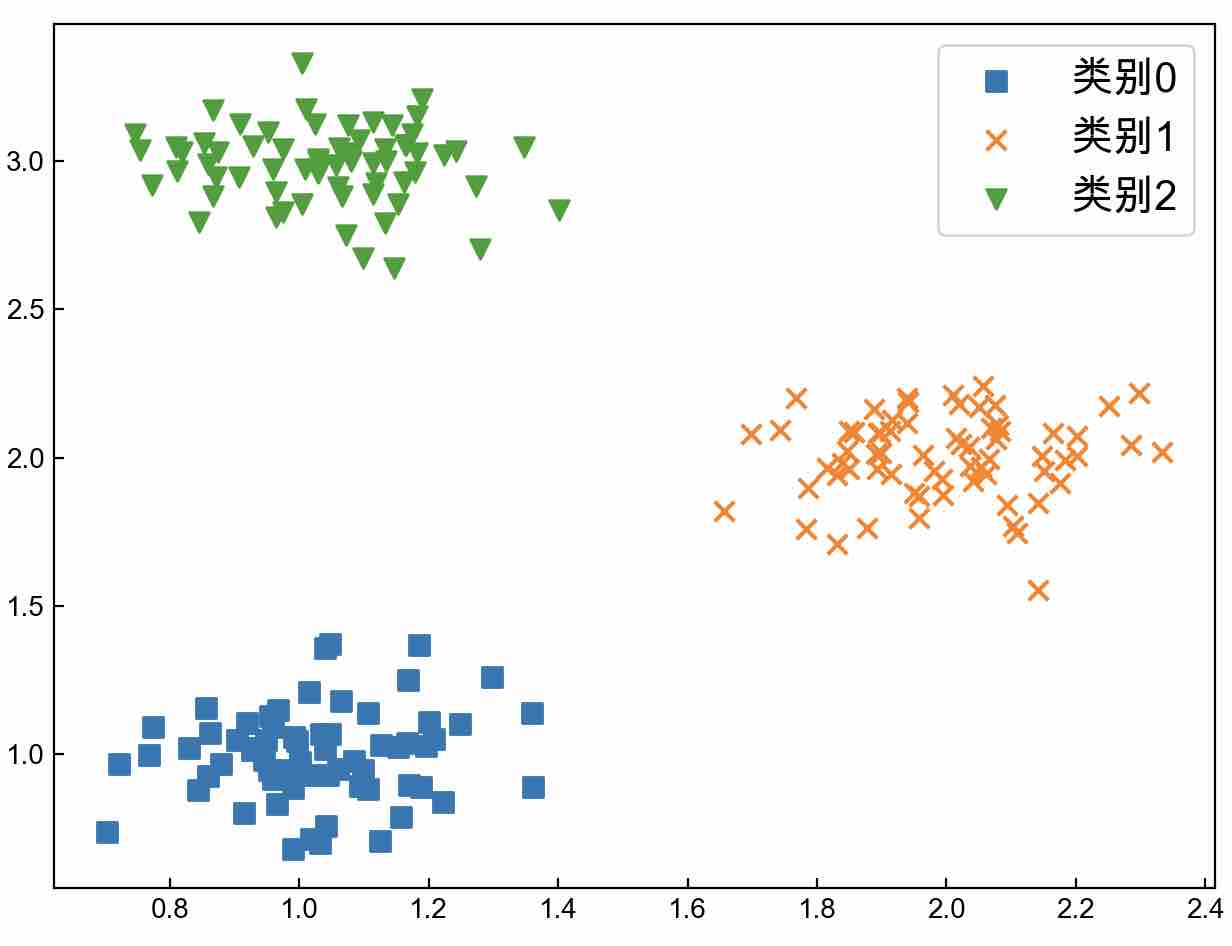
如图3-5所示,此图为一个可视化的数据集,它一共包含3个类别。
当利用One-vs-all的分类思想来解决图3-5中的多分类问题时,可以可视化成如图3-6所示的情况。
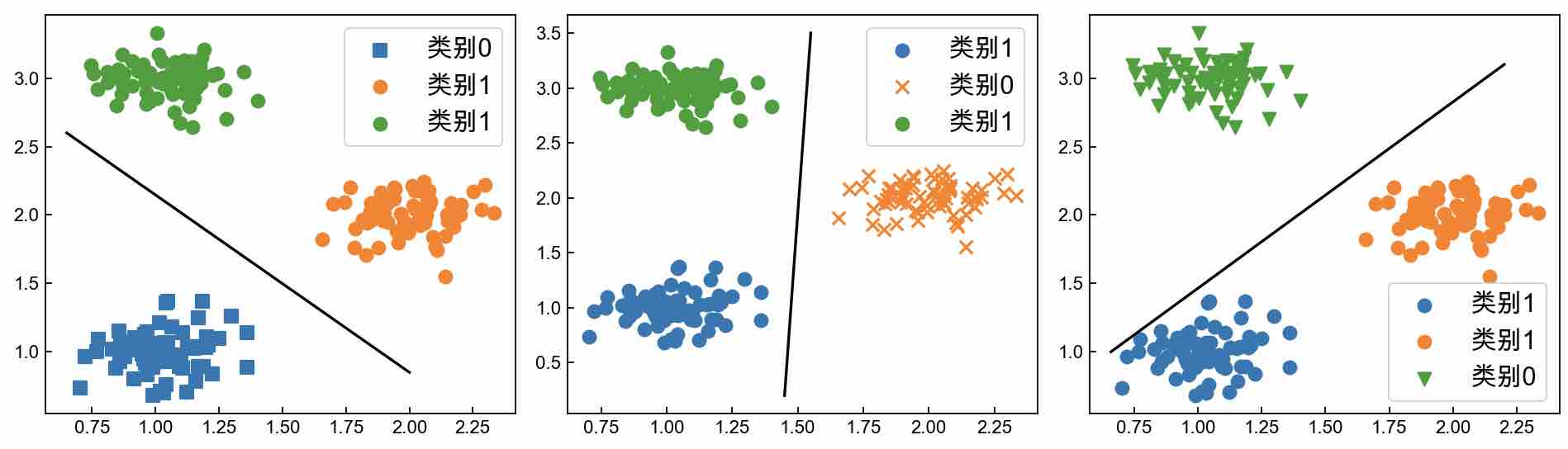
在图3-6中,以从左往右的划分方式划分数据集,然后分别训练3个二分类的逻辑回归模型$h_0(x)$、$h_1(x)$和$h_2(x)$,分别表示样本$x$属于第0、第1和第2共3个类别的概率,最后在预测的时候只要选择概率最大时分类模型所对应的类别即可。
3.2.2 多分类示例代码#
在scikit-learn中,可以借助LogisticRegression类中的multi_class='ovr'参数来完成整个多分类的建模任务,完整代码见 AllBookCode/Chapter03/C04_one_vs_all_train.py 文件。
1. 载入数据集
在这里,我们同样使用了sklearn中内置的一个分类数据集iris进行示例。首先需要载入这个数据集,代码如下:
1 from sklearn.datasets import load_iris
2 def load_data():
3 data = load_iris()
4 x, y = data.data, data.target
5 return x, yiris数据集一共包含3个类别,每个类别中有50个样本,并且每个样本有4个特征维度。同时,scikit-learn中也内置了很多丰富的其它数据集来方便初学者使用,具体信息可以参见官网 [1]。
2. 训练模型
在数据集载入完成后,便可以通过sklearn中的LogisticRegression完成整个建模求解过程,代码如下:
1 def train(x, y):
2 model = LogisticRegression(multi_class='ovr')
3 model.fit(x,y)
4 print("得分: ", model.score(x, y))
5 # 得分:0.95到此,对于多变量逻辑回归的分类方法与建模过程就介绍完了。不过细心的读者可能会发现,上面代码中的最后一行输出了一个0.95的得分,它表示什么含义呢?这里的0.95其实指的模型分类的准确率,意思是有95%的样本被模型正确分类了,具体计算原理可见3.3节内容。
3.2.3 小结#
在本节内容中,我们首先以图示的方式介绍了如何用Onevsall的思想来用逻辑回归模型解决多分类的任务场景,然后介绍了如何借助开源库sklearn来完成整个多分类任务的建模过程。接下来,我们将开始学习分类模型中的常见评估指标。