9.2 Word2Vec词向量#
在9.1节内容中,我们详细梳理了自然语言处理发展时所经历的3个核心阶段,并且同时提到目前主流的是基于深度学习的语言模型。在本节内容中我们将会介绍第1种基于神经网络的将单词表示为连续向量的自然语言处理技术——Word2Vec。
9.2.1 Word2Vec动机#
在基于深度学习的语言模型中一个关键的问题就是如何有效地表示文本信息。在早期的建模方法中通常都是使用基于手工设计的特征表示来表示文本,例如词袋模型中的词频或TF-IDF权重、独热编码等方法。但这些特征通常都是离散且稀疏的,难以捕捉到词与词之间的语义关系。例如独热编码就没有任何相似性或者其它关系上的概念,如果我们将点积作为相似性的衡量方法那么此时任意两个向量之间的相似度都将是0。因此,研究人员开始寻求一种更有效的文本表示方法,并且希望能够利用神经网络的能力来自动学习词的向量化表示。
基于这样的动机,谷歌公司托马斯[1]等人于2013年提出了一种基于神经网络技术的Word2Vec模型来生成词向量(Word Embedding)或(Word Vector)。Word2Vec通过使用浅层神经网络模型来学习词的分布式表示(Distributed Representations),其核心思想是基于大量文本语料库的统计信息,将每个词分别映射到一个低维连续的向量空间中,使得具有相似语义的词在向量空间中的距离更近。这种分布式表示可以更好地捕捉词之间的语义关系,使得近义词之间的相似性和词之间的语义类比能够通过计算得到。例如计算"king" - “man” + “woman”,可以得到一个向量表示"queen",即实现了词之间的类比关系[2]。
9.2.2 Word2Vec模型#
整体来看Word2Vec模型的网络结构主要有两种:连续词袋模型(Continuous Bag of Words,CBOW)和跳元(Skip-gram)模型。CBOW模型的目标是在固定滑动窗口内根据第$t$个词的上下文词来预测第$t$个词对应的概率分布,即第$t$个词;Skip-gram模型则刚好与CBOW模型相反,它的目标是根据第$t$个词来预测其上下文各个词的概率分布。从这里我们可以看出,不管是CBOW模型还是Skip-gram模型都不需要人工额外标注数据,因此它们都属于自监督模型,下面开始分别进行介绍。
9.2.3 连续词袋模型#
1. 连续词袋模型原理
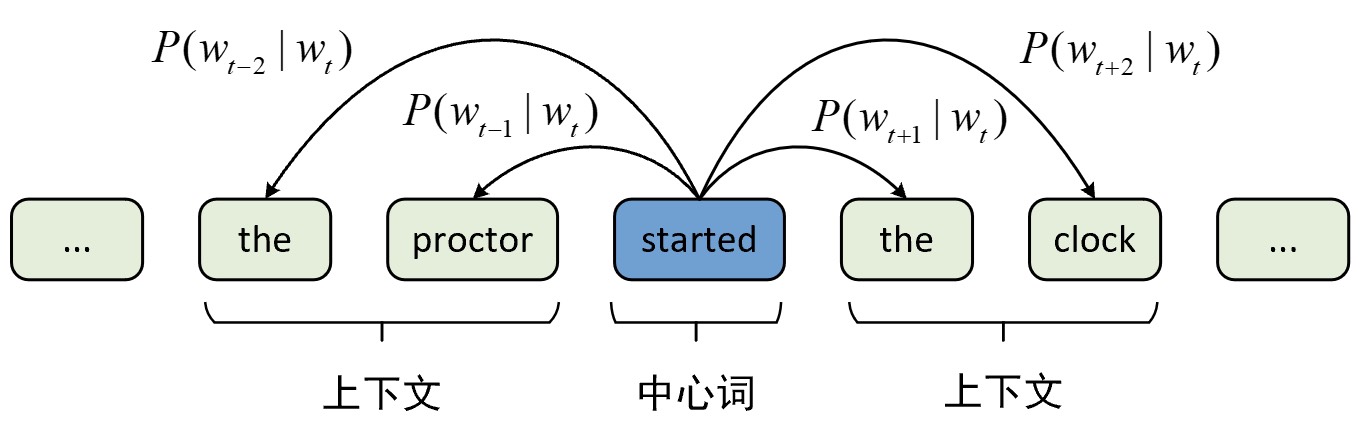
如图9-4所示便是CBOW的原理示意图,此时滑动窗口的长度为$m=2$,CBOW的原理是文本序列$S$在所有滑动窗口下,通过已知的上下文词来最大化中心词出现的条件概率。
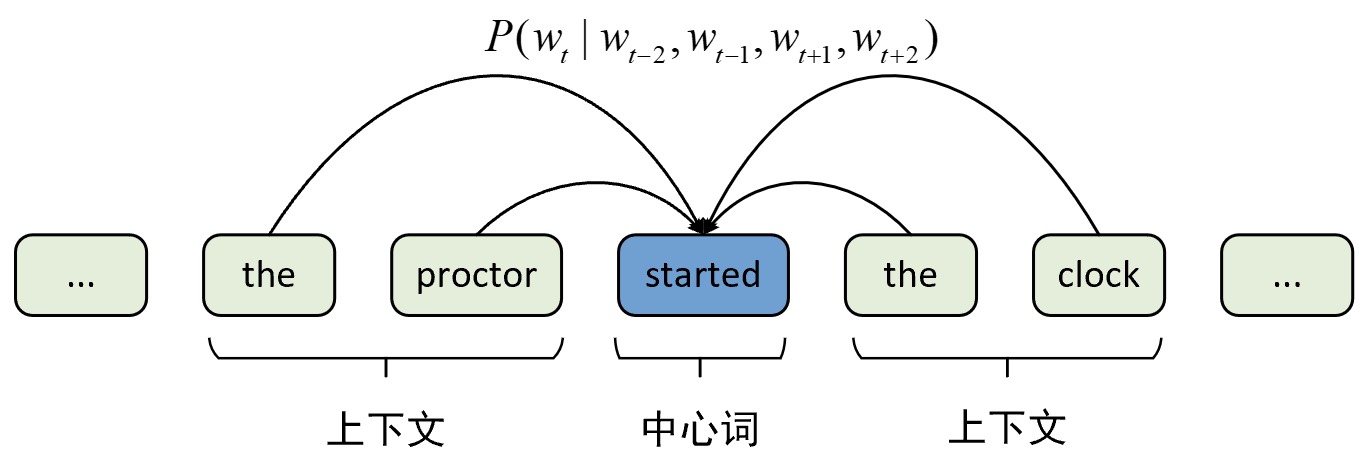
在文本序列$S$中,对于每个位置$t=1,2,...,T$来说,在滑动窗口长度为$m$的情况下,CBOW模型的目标便是最大化所有给定上下文词$w_{t-m},..,w_{t-1},w_{t+1},...,w_{t+m}$时,中心词$w_t$对应的条件概率,如式(9-6)所示便是CBOW模型需要最大化的似然函数
$$ \mathcal{L}(\theta)=\prod_{t=1}^TP(w_{t}|w_{t-m},...,w_{t-1},w_{t+1},...,w_{t+m};\theta)\tag{9-6} $$其中$\theta$便是需要求解的模型参数。
进一步,同时对式(9-6)两边取自然对数,且令$\hat{w}=\{w_{t-m},...,w_{t-1},w_{t+1},...,w_{t+m}\}$有
$$ \begin{aligned} J(\theta)=-\frac{1}{T}\log \mathcal{L}(\theta) &=-\frac{1}{T}\sum_{t=1}^T\log P(w_t|w_{t-m},...,w_{t-1},w_{t+1},...,w_{t+m};\theta)\\[3ex] &=-\frac{1}{T}\sum_{t=1}^T\log P(w_t|\hat{w};\theta) \end{aligned} \tag{9-7} $$此时$J(\theta)$便是我们需要最小化的目标函数,而接下来的问题便是如何计算条件概率$P(w_{t}|\hat{w};\theta)$。
现在假设$p_w$和$q_w$分别为词$w$作为中心词和上下文词时各自对应的词向量,则在给定上下文词$o$的情况下中心词$c$的条件概率为
$$ P(c|o)=\frac{\exp(q_o^Tp_c)}{\sum\limits_{w\in \mathcal{V}}\exp(q^T_op_w)}\in \mathbb{R}\tag{9-8} $$其中$\mathcal{V}$表示词表中所有的词。
之所以可以通过式(9-8)来建模此时的条件概率是因为离得越近的两个词总体上语义应该越相似,而点积的大小在一定程度上则可以反映两个向量的相似性,点积越大则表示两个向量越相似[2]。因此,在建模上述条件概率时本质上可以看做是对于已知上下文词时,模型需要在词表中找到与之尽可能相似的词。
此时,由式(9-7)和式(9-8)可得
$$ \begin{aligned} J(\theta)&=-\frac{1}{T}\sum_{t=1}^T\log \frac{\exp(q_{\hat{w}}^Tp_{w_t})}{\sum\limits_{w\in\mathcal{V}}\exp(q^T_{\hat{w}}p_w)}=-\frac{1}{T}\sum_{t=1}^T\left(q_{\hat{w}}^Tp_{w_t}-\log\sum\limits_{w\in\mathcal{V}}\exp(q^T_{\hat{w}}p_w)\right) \end{aligned} \tag{9-9} $$因为在CBOW模型中,待预测的中心词有多个上下文词,因此在实际处理时式(9-9)中的$q_{\hat{w}}$一般取滑动窗口中所有上下文词词向量的均值。最终,式(9-9)便是模型需要最小化的目标函数,虽然看起来略显复杂但是本质上它就是$\text{Softmax}$和交叉熵的组合。
2. 连续词袋模型建模
在实际模型构建过程中,CBOW模型将首先取上下文中每个词$w_i$对应词向量$v_i\in \mathbb{R}^n$的均值;然后再与隐藏层权重参数$U\in \mathbb{R}^{n\times|\mathcal{V}|}$作用并取$\text{Softmax}$后得到对应的条件概率分布;最后使用交叉熵损失函数来完成模型的训练过程,整体结构如图9-5所示。
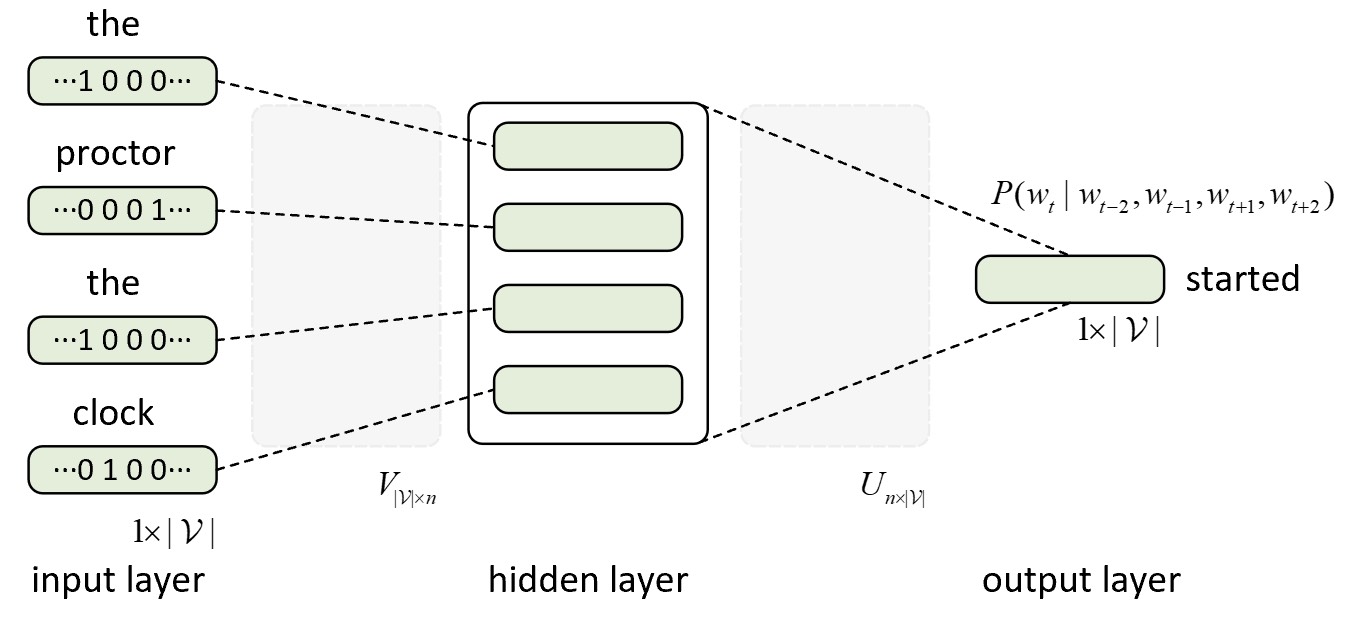
在图9-5中,左侧输入层为上下文词的独热编码表示形式,其中$|\mathcal{V}|$表示词表的长度;中间为隐藏层,每一行表示根据对应上下文词独热编码索引得到的输入词向量表示,这也被形象的称为词嵌入(Word Embedding);输入层和隐藏层之间的权重矩阵$V\in \mathbb{R}^{|\mathcal{V}|\times n}$为输入词向量矩阵,其中第$i$行$v_i$表示词表中第$i$个词$w_i$对应的输入词向量,而这也模型训练完毕后每个词真正的词向量表示;隐藏层与输出层之间的权重矩阵$U\in \mathbb{R}^{n\times |\mathcal{V}|}$为输出词向量矩阵,其中第$i$列$u_i$表示词表中第$i$个词$w_i$对应的输出词向量,用于同$v_i$计算得到对应的条件概率分布。
例如对于图9-5中的示例来说,假设3个上下文词"the"、“proctor"和"clock"对应的词向量分别为$v_i$、$v_j$和$v_k$,且取均值后上下文词的整体表示为$\hat{v}=\frac{1}{2m}(v_{i}+v_{j}+v_{i}+v_{k})$,则中心词对应的条件概率分布为
$$ \hat{y}=\text{Softmx}(z)=\frac{\exp(z)}{\sum\limits_{i=0}^{|\mathcal{V}|-1}\exp(z_i)},\;z=\hat{v}U\in\mathbb{R}^{1\times|\mathcal{V}|} \tag{9-10} $$最后使用交叉熵损失函数便可以同中心词真实的概率分布计算得到损失值并求解得到整个模型。
从这里我们可以看出,上下文词和中心词是分别来自不同的词向量矩阵,即图9-5中的矩阵 $V$ 和 $U$。使用不同的嵌入矩阵模型能够更好地捕捉词汇在不同角色中的语义差异和非对称关系,提供更灵活、精细的语义表示。这种设计也避免了使用单一嵌入矩阵时可能产生的冲突和局限性,从而提升了模型的表达能力和性能。在实际的实验中,使用两个不同的嵌入矩阵在许多自然语言处理任务上表现更好。
9.2.4 跳元模型#
1. 跳元模型原理
如图9-6所示便是Skip-gram的原理示意图,此时滑动窗口的长度为$m=2$,Skip-gram的原理是文本序列$S$在所有滑动窗口下,通过已知的中心词来最大化滑动窗口中所有上下文词出现的条件概率。