4.7 Qwen3 Reranking 原理与使用#
在第3.4节内容中,我们介绍了基于 Qwen3 基座模型训练而来的 Qwen3 Embedding 模型,下面继续介绍同样基于 Qwen3 基座模型优化得到的 Reranking 模型。
4.7.1 Qwen3 Reranking 原理#
Qwen3 Reranking 模型接收文本对(例如用户查询与候选文档)作为输入,利用单塔结构计算并输出两个文本的相关性得分,整体网络结构如图4-11所示。
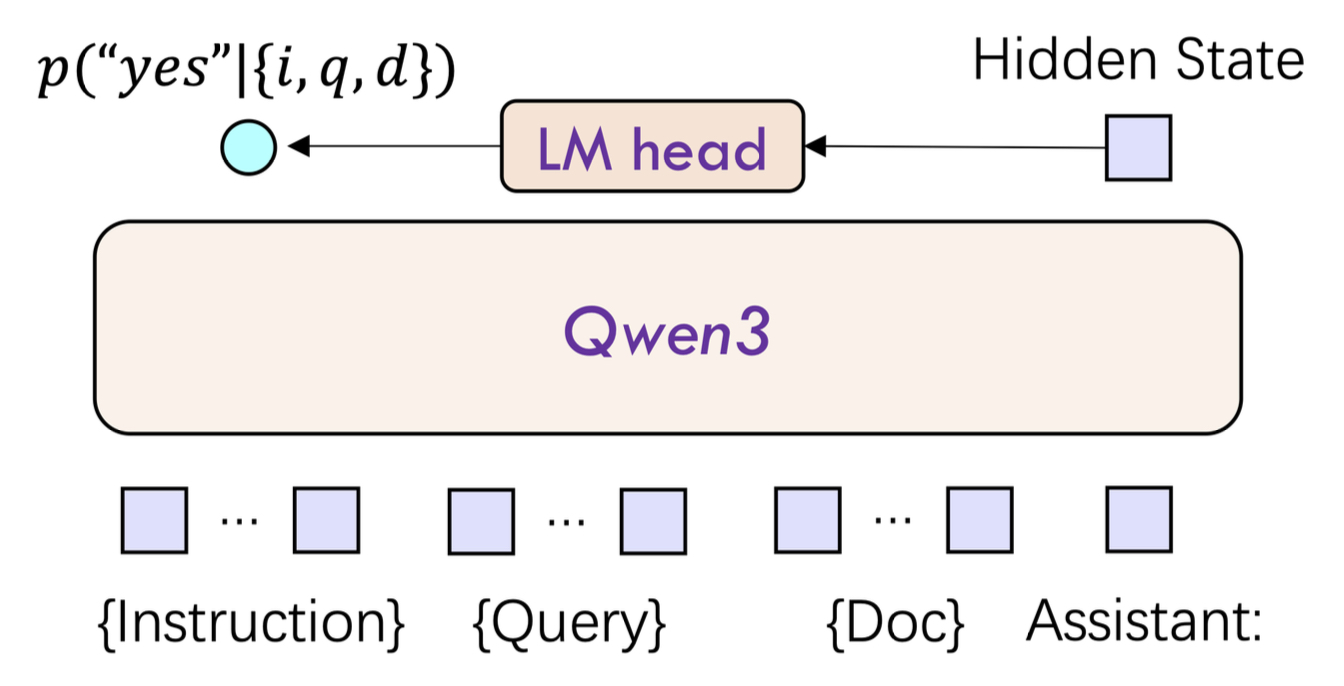
根据图4-9可以看出,模型的输入包含3个部分指令、用户请求 Query 与候选文档 Doc;中间部分则是 Qwen3 模型的网络结构,最后模型的输出则是取最后一个时刻, yes 这个词元对应概率值的归一化结果作为 Query 与 Doc 之间的相关性得分。
4.7.2 Qwen3 Reranking 使用#
在大致清楚 Qwen3 Reranking 模型的原理以后,我们再来看如何通过 Dashscope SDK 进行使用,示例代码如下[2]:
1 import dashscope
2
3 def text_rerank():
4 resp = dashscope.TextReRank.call(
5 model="qwen3-rerank", query="什么是文本排序模型",
6 documents=["文本排序模型广泛用于搜索引擎和推荐系统中,它们根据文本相关性对候选文本进行排序",
7 "量子计算是计算科学的一个前沿领域",
8 "预训练语言模型的发展给文本排序模型带来了新的进展"],
9 top_n=10, return_documents=True,
10 instruct="Given a web search query, retrieve relevant passages that answer the query.")
11 print(resp)
12
13 if __name__ == '__main__':
14 text_rerank()在上述代码中,第5行query 为查询内容,最大长度不能超过 4000 个词元。第6~8行documents 为待排序的候选文档列表,每个元素是一个字符串,qwen3-rerank 最多支持传入 500 个候选文档。第9行top_n 指定返回排序后的 top_n 个文档,默认返回全部文档,如果指定的值大于文档总数将返回全部文档;return_documents 指定是否在排序结果中返回文档原文,默认值false,可以减少网络传输开销。
例如对于上面的示例,return_documents 为 True 和 False 的返回结果分别如下所示:
{"status_code": 200, "request_id": "5bfa7b33-e28e-9692-ba35-73bcff712b5d", "code": "", "message": "", "output": {"results": [{"index": 0, "relevance_score": 0.9268843113697627, "document": {"text": "文本排序模型广泛用于搜索引擎和推荐系统中,它们根据文本相关性对候选文本进行排序"}}, {"index": 2, "relevance_score": 0.7576926327242663, "document": {"text": "预训练语言模型的发展给文本排序模型带来了新的进展"}}, {"index": 1, "relevance_score": 0.3011433941310506, "document": {"text": "量子计算是计算科学的一个前沿领域"}}]}, "usage": {"total_tokens": 105}}
{"status_code": 200, "request_id": "a612e0b4-983c-9806-8627-7fe41dcc94c6", "code": "", "message": "", "output": {"results": [{"index": 0, "relevance_score": 0.9231909275968047, "document": null}, {"index": 2, "relevance_score": 0.7583153661357789, "document": null}, {"index": 1, "relevance_score": 0.3147970015658894, "document": null}]}, "usage": {"total_tokens": 105}}第10行instruct 则是用于添加自定义排序任务类型说明,通过该参数可以指导模型采用不同的排序策略,建议使用英文撰写。
对于问答检索任务来说可设置为 "Given a web search query, retrieve relevant passages that answer the query." ,其侧重点在于寻找问题的答案。模型会优先评估文档是否解答了用户请求中的问题。
示例:对于 Query “如何预防感冒?”,文档 “勤洗手是预防感冒的有效方法” 会获得高分;而文档 “感冒是一种常见疾病”虽然主题相关,但因未提供答案,得分会显著更低。
对于语义相似度排序任务来说可以设置为 "Retrieve semantically similar text.",其侧重点在于判断语义的等价性,模型会评估请求与文档的核心含义是否一致,而不管具体措辞或句式。
示例:在FAQ场景中,用户请求 “如何修改密码?” 与候选问题 “忘记密码怎么办?” 在语义上高度相似应获得高分,模型会关注两者是否指向同一个用户意图。
同时,如不指定该参数,将默认按问答检索任务进行排序,更多任务指令可参考 Code/Chapter05/task_prompts.json 文件中的示例。
以上完整示例代码可参见 Code/Chapter04/C06_qwen_reranker.py 文件。
4.7.3 Qwen3 Reranking 实现#
可以发现,Dashscope SDK 来使用 Qwen3 Reranking 模型还是非常简单的,不过它内部到底是如何处理的呢?图4-9中的 LM head 到底长什么样的?下面我们来做一个简单的介绍,看看如何手动实现这一步 [3]。
从图4-9可知,首先我们需要根据 Query 、Doc 以及 Instruction 来构建模型的输入。但是从结构图我们可以看到应该还要有指令来约束模型的输出结果为 $p(\text{'yes'}|\{i,q,d\})$,也是就是说 Instruction 是开放给用户使用的用户指令,而底层应该还有一个系统级指令。具体地,可以通过如下方式来构建输入:
1 def format_instruction(instruction, query, doc):
2 prefix = "<|im_start|>system\nJudge whether the Document meets the requirements based on the Query and the Instruct provided. Note that the answer can only be \"yes\" or \"no\".<|im_end|>\n<|im_start|>user\n"
3 suffix = "<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\n"
4 if instruction is None:
5 instruction = 'Given a web search query, retrieve relevant passages that answer the query'
6 output = f"{prefix}<Instruct>: {instruction}\n<Query>: {query}\n<Document>: {doc}{suffix}"
7 return output对于上述代码来说,其作用便是将instruction, query, doc, prefix, suffix拼接到一起,即 {prefix}<Instruct>: {instruction}\n<Query>: {query}\n<Document>: {doc}{suffix}。从 prefix 可以明显看出,这里通过指令对模型的输出做了明确约束。
进一步,可以通过如下方式来计算每条用户请求和参考文档之间的相似性得分:
1 def compute_logits(inputs, token_true_id, token_false_id):
2 batch_scores = model(**inputs).logits[:, -1, :]
3 true_vector = batch_scores[:, token_true_id]
4 false_vector = batch_scores[:, token_false_id]
5 batch_scores = torch.stack([false_vector, true_vector], dim=1)
6 batch_scores = torch.nn.functional.log_softmax(batch_scores, dim=1)
7 scores = batch_scores[:, 1].exp().tolist()
8 return scores在上述代码中,第1行 inputs 为函数 format_instruction() 返回后经过词元化后的结果,即为原始输入的词元 ID;token_true_id 和 token_false_id 分别为 “yes” 和 “no” 这两个单词在词表中的 ID。第2行是取前向传播隐藏状态最后一个时刻的结果,此时 batch_scores 的形状为 [batch_size, vocab_size]。第3~5行分别取所有样本在 “yes” 和 “no” 这两个词元上的预测 logits 值,并将两者拼接到一起,最后 batch_scores 的形状均为 [batch_size, 2]。第6~7行则是使用 Softmax 对每个样本的预测结果进行归一化得到概率值。
最后,可以通过如下方式来运行得到结果:
1 if __name__ == '__main__':
2 tokenizer = AutoTokenizer.from_pretrained(data_info.QWEN3_RERANKER_06B_DIR, padding_side='left')
3 model = AutoModelForCausalLM.from_pretrained(data_info.QWEN3_RERANKER_06B_DIR).eval()
4 token_false_id = tokenizer.convert_tokens_to_ids("no")
5 token_true_id = tokenizer.convert_tokens_to_ids("yes")
6 max_length = 8192
7 instruction = 'Given a web search query, retrieve relevant passages that answer the query'
8 queries = ["What is the capital of China?",
9 "Explain gravity"]
10 documents = ["The capital of China is Beijing.",
11 "Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."]
12 pairs = [format_instruction(instruction, query, doc) for query, doc in zip(queries, documents)]
13 inputs = tokenizer(pairs, padding=True, return_attention_mask=True,
14 max_length=max_length, return_tensors="pt")
15 scores = compute_logits(inputs, token_true_id, token_false_id)
16 print("scores: ", scores) # scores: [1.0, 1.0]在上述代码中,分别计算了 queries 和 documents 中每一条请求与之对应的候选文档之间的相似性评分。进一步,只需要对上面的代码进行封装和后处理,便可以得到一个和 dashscope.TextReRank.call() 同样效果的模块,这里我们就不再赘述。
到此,我们就把 Qwen3 Reranking 模型的原理与使用方法介绍完了,以上完整示例代码可参见 Code/Chapter04/C07_qwen_reranker_imp.py 文件。在下一节内容中,我们将会继续介绍如何基于第4章内容构建的 RAG Agent 来实现向量检索结果的重排序。
引用#
[1] Zhang Y, Li M, Long D, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models[J]. arXiv preprint arXiv:2506.05176, 2025.