4.5 AlexNet网络#
在第3章及本章开篇内容中,我们多次提及如何有效地对输入数据进行特征提取,然后再将提取得到的特征输入到下游任务模型是深度学习中的一个重要研究方向,而这又尤其体现在图像处理领域中。自卷积操作问世以来,如何设计一个有效的网络结构就成为了一个热门的研究方向。研究者们通过设计不同网络结构来对输入的图像进行特征提取,并且都希望设计出的模型能够表现出强大的学习能力,以此来提高下游任务的精度。
2012年AlexNet[1]模型在ImageNet图像识别(关于该数据集的介绍见5.4.1节内容)大赛中一战成名,在1000分类的测试集上分别取得了$62\%$的Top-1准确率和$83\%$的Top-5(即预测概率最大的前5个中包含有正确标签)的成绩,其名称也取自于第一作者的名字Alex Krizhevsky。在本节内容中我们将会详细介绍AlexNet网络模型的原理及其实现过程。
4.5.1 AlexNet动机#
虽然传统的机器学习模型可以通过扩充数据集来提升模型在图像识别这方面的效果,但是在现实环境中物体的呈现形式变化多样,因此想要模型有一个较好的效果则需要使用更大的数据集。同时,为了使得模型能够从数百万张图片中学习识别上千个类别我们就需要一个具有强大学习能力的模型。然而,在这样一个复杂的任务场景中即使是使用像ImageNet这样大规模的数据集也无法完全解决这个问题,因此模型还应该具有相应的先验知识来弥补在数据上的不足。
基于这样的想法,论文作者采用了卷积作为基础模块来构建网络,并通过增加卷积层的深度和宽度来控制模型的学习能力。此外,AlexNet模型的设计还包括使用了GPU来加速网络训练,这也是该模型成功的一个关键因素。AlexNet的提出标志着深度学习在计算机视觉领域的应用开始得到广泛的认可和使用。
4.5.2 AlexNet结构#
简单来说,AlexNet的整体网络结构可以看做是以LeNet5模型为基础的改进版本。AlexNet采用了5层卷积加3层全连接的网络结构,如图4-31所示便是论文中AlexNet模型的网络结构图。
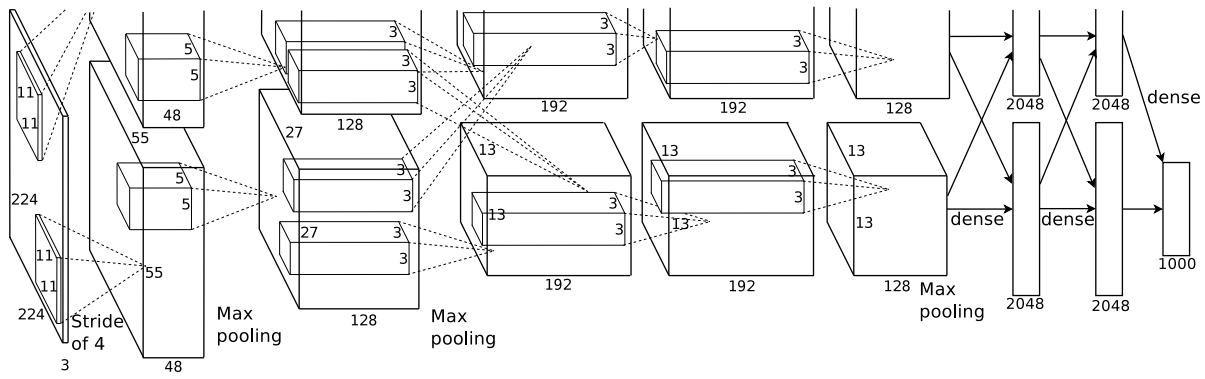
从图4-31可以发现,整个网络结构分为了上下两层,其原因在于受限于当时GPU显存的大小不得已而为之。但现在就大可不必这样做,直接将两者合并在一起即可,因此可以重新将其画成如图4-32所示的形式。
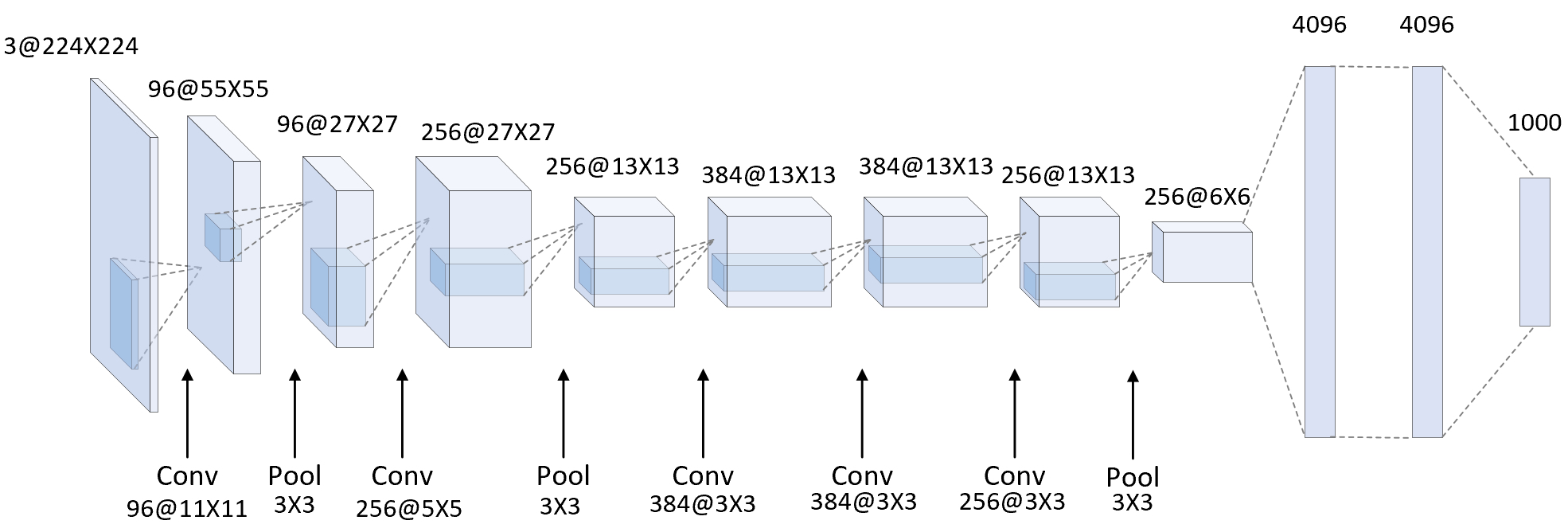
如图4-32所示便是重画后的网络结构图,其中网络结构上面的标识表示各个操作之后结果的维度信息,下面的标识表示各个操作对应的参数信息。根据图4-32可知,虽然AlexNet与LeNet的设计理念非常相似,但也有着显著的区别。AlexNet第1层中卷积窗口的大小是11,这是因为ImageNet数据集中图片的大小是MNIST的近10倍,所以需要更大的卷积窗口来进行特征提取。第2层中的卷积窗口大小减小到5,之后全采用大小为3的卷积窗口进行卷积。此外,第1、第2和第5个卷积层之后都使用了窗口大小为3、步幅为2的最大池化层,紧接着最后一个卷积层的是2个输出个数为$4096$的全连接层。最后,据图4-32所示的网络结构可以得出表4-2中所示的参数信息。
| 网络层 | 输入形状 | 参数 | 输出形状 | 参数量 |
|---|---|---|---|---|
| ①卷积层 | [1,3,224,224] |
kernel=[3,11,11,96],S=4,P=2 |
[1,96,55,55] |
$34944$ |
| 池化层 | [1,96,55,55] |
kernel=[3,3],S=2 |
[1,96,27,27] |
$0$ |
| ②卷积层 | [1,96,27,27] |
kernel=[96,5,5,256],S=1,P=2 |
[1,256,27,27] |
$614656$ |
| 池化层 | [1,256,27,27] |
kernel=[3,3],S=2 |
[1,256,13,13] |
$0$ |
| ③卷积层 | [1,256,13,13] |
kernel=[256,3,3,384],S=1,P=1 |
[1,384,13,13] |
$885120$ |
| ④卷积层 | [1,384,13,13] |
kernel=[384,3,3,384],S=1,P=1 |
[1,384,13,13] |
$1327488$ |
| ⑤卷积层 | [1,384,13,13] |
kernel=[384,3,3,256],S=1,P=1 |
[1,256,13,13] |
$884992$ |
| 池化层 | [1,256,13,13] |
kernel=[3,3],S=2 |
[1,256,6,6] |
$0$ |
| ⑥全连接层 | [1,256,6,6] |
weight=[256*6*6,4096] |
[1,4096] |
$37752832$ |
| ⑦全连接层 | [1,4096] |
weight=[4096,4096] |
[1,4096] |
$16781312$ |
| ⑧全连接层 | [1,4096] |
weight=[4096,1000] |
[1,1000] |
$4097000$ |
其中输入形状和输出形状的4个维度分别为[batch_size,in_channels,width,height],卷积核形状的4个维度分别为[in_channels,w,w,out_channels]。从表4-2可以看出,AlexNet网络结构的参数量大约在6千万左右,而倒数第1个全连接几乎就占了$60\%$左右。假如每个权重参数均使用32位浮点数进行表示,则每个权重参数将占用4个字节,则AlexNet模型的大小约为230MB。
除此之外,AlexNet还将Sigmoid激活函数替换成了更加简单的ReLU激活函数(尽管之前在实现LeNet时我们已经使用了ReLU激活函数)。一方面,ReLU激活函数在计算上会更加简单,它并没有Sigmoid中的求幂运算;另一方面,当Sigmoid激活函数的输出值接近0或1这些区域时,其梯度几乎为0,从而造成无法通过梯度下降算法来更新模型的这部分参数,而ReLU激活函数在正区间的梯度恒为1。进一步,在AlexNet中还引入了两种新的方法来提高模型分类的准确率:①通过丢弃法(详见3.10.12节内容)来控制全连接层的模型复杂度,而之前的LeNet5并没有;②引入了大量的图像增广技术,如翻转、裁剪和颜色变化等来增加样本的多样性,以此提高模型的泛化能力。
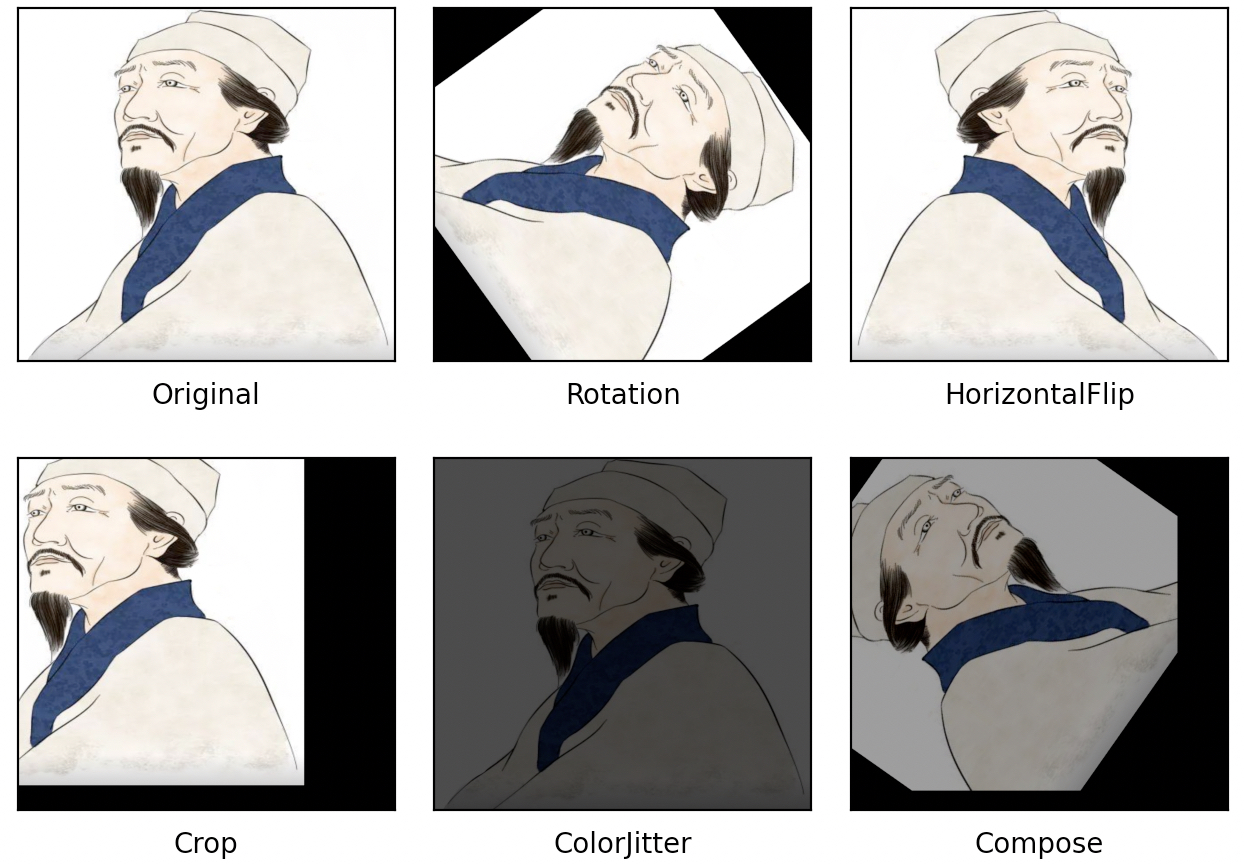
如图4-33所示,左上角“Original”表示最原始的图片,“Rotation”表示经过旋转后的结果,“HorizontalFlip”表示经过水平翻转后的结果,“Crop”表示结果裁剪后的结果,“ColorJitter”表示经过明暗变化、对比度、饱和度和色调调整后的结果,“Compose”将前面几个变化组合在一起后的结果。上述完整示例代码可以参见Code/Chapter04/C04_AlexNet/img_augmentation.py文件。
4.5.3 AlexNet实现#
在介绍完AlexNet整个模型的相关原理后,我们再来看如何通过PyTorch来实现整个网络模型。以下完整示例代码可以参见Code/Chapter04/C04_AlexNet文件。
1. 前向传播
首先需要实现模型的整个前向传播过程。从图4-32可知,整个模型整体分为卷积和全连接两个部分,因此可以通过定义两个Sequential()来分别进行表示,实现代码如下所示:
1 class AlexNet(nn.Module):
2 def __init__(self, in_chs=3, num_classes=1000, dropout=0.5):
3 super(AlexNet, self).__init__()
4 self.conv = nn.Sequential(
5 nn.Conv2d(in_channels=in_chs,out_channels=96,kernel_size=11,stride=4,padding=2),
6 nn.ReLU(inplace=True),
7 nn.MaxPool2d(kernel_size=3, stride=2),
8 nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2),
9 nn.ReLU(inplace=True),
10 nn.MaxPool2d(kernel_size=3, stride=2),
11 nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
12 nn.ReLU(inplace=True),
13 nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
14 nn.ReLU(inplace=True),
15 nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
16 nn.ReLU(inplace=True),
17 nn.MaxPool2d(kernel_size=3, stride=2))
18 self.fc = nn.Sequential(
19 nn.Flatten(),
20 nn.Linear(in_features=256 * 6 * 6, out_features=4096),
21 nn.ReLU(inplace=True),
22 nn.Dropout(p=dropout),
23 nn.Linear(in_features=4096, out_features=4096),
24 nn.ReLU(inplace=True),
25 nn.Dropout(p=dropout),
26 nn.Linear(in_features=4096, out_features=num_classes))在上述代码中,第2行in_chs和num_classes分别用来指定输入图片的通道数和分类类别数,以此来适应不同的数据集。第4~17行是AlexNet中对应的卷积部分,其中inplace=True表示直接对当前层的输入变量进行原地修改,而不再定义新的中间变量,这是由于nn.ReLU层并没有额外的参数,所以可以将ReLU后的结果直接赋值到输入的变量中,从而避免了新的存储开销。第18~26行是对应的全连接网络部分。这里分成两部分来写的好处是可以增加代码的可读性,同时也易于修改或者复用。当然,如果方便依旧可以将这些操作都放到一个 nn.Sequential()中。
在定义完卷积核全连接这两个模块后,需要再定义forward方法来完成整个前向传播的计算过程,实现代码如下所示:
1 def forward(self, img, labels=None):
2 feature = self.conv(img)
3 logits = self.fc(feature)
4 if labels is not None:
5 loss_fct = nn.CrossEntropyLoss(reduction='mean')
6 loss = loss_fct(logits, labels)
7 return loss, logits
8 else:
9 return logits在上述代码中,第2~3行对应的便是上面卷积核全连接模块两个部分的计算过程。第4~7行便是根据输入标签计算得到损失值并返回。第8~9行是在推理时直接返回前向传播的计算结果。
2. 构造数据集
在完成模型的前向传播过程后便可以根据需要来完成数据集的构建。在这里,我们使用到的是另外一个比较常见的图片分类数据集FashionMNIST。从名字可以看出,该数据集同MNIST有着相似的地方,即图片的大小、通道数和分类类别数都相同,只是图像内容由手写体数字变成了衣物。
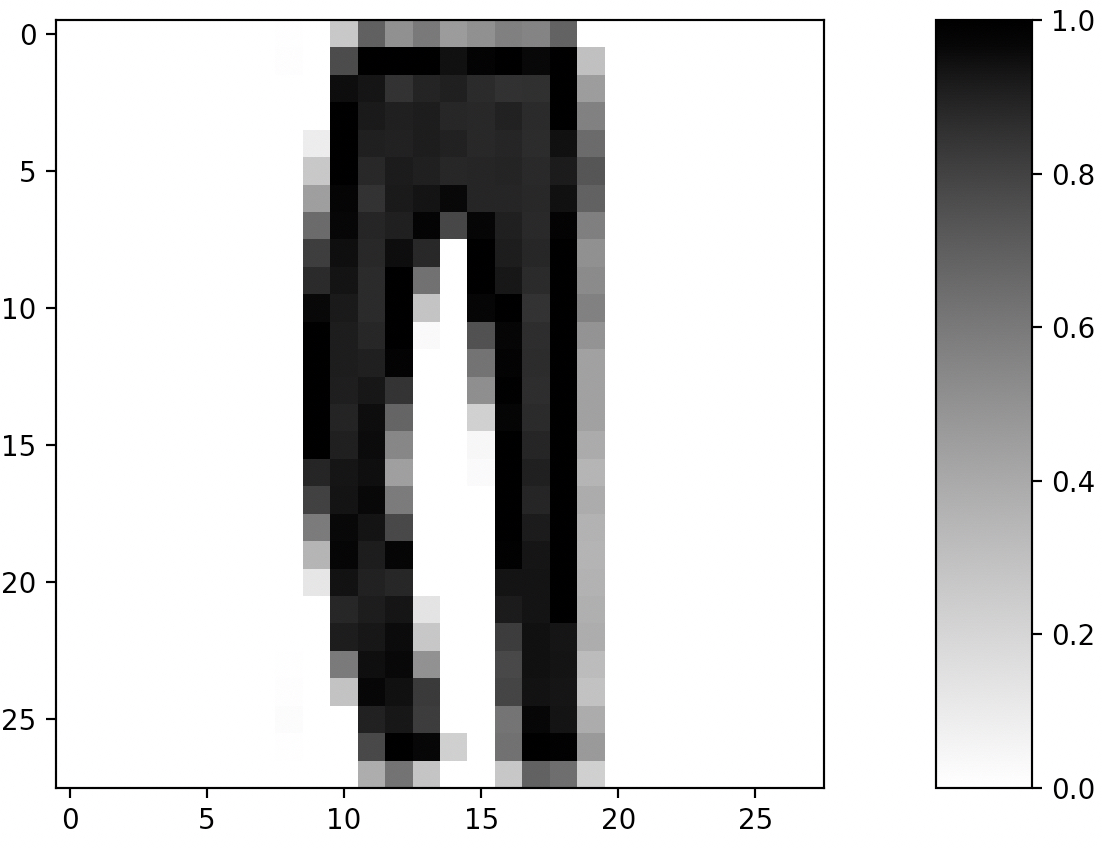
如图4-34所示便是FashionMNIST数据集的可视化结果,可以看出其大小为$28\times28$,通道数为1。进一步,我们可以通过如下方式来构造该数据集对应的迭代器,示例代码如下所示:
1 def load_dataset(config, is_train=True):
2 trans = [transforms.ToTensor()]
3 if config.resize is not None:
4 trans.append(transforms.Resize(size=config.resize,
5 interpolation=InterpolationMode.BILINEAR))
6 if config.augment and is_train:
7 trans += [transforms.RandomHorizontalFlip(p=0.3),
8 transforms.ColorJitter(0.2, 0.3, 0.5, 0.5)]
9 trans = transforms.Compose(trans)
10 dataset = FashionMNIST(root='~/Datasets/FashionMNIST', train=is_train,
11 download=True, transform=trans, )
12 iter = DataLoader(dataset, batch_size=config.batch_size, shuffle=True,
13 num_workers=1, pin_memory=False)
14 return iter在上述代码中,第1行config表示传入的配置信息,is_train表示指定当前的训练还是测试状态。第2行是初始化一个列表用来保存需要对原始数据集进行的张量变换操作,其中ToTensor()的作用是将载入的原始图片由$[0,255]$的范围缩放至$[0.0,1.0]$的取值范围并把每张图的形状转换为[channel,height,width]。第3~5行用于将输入的$28\times28$的图片变成$224\times224$的形状,因为FashionMNIST的大小是$28\times28$。第6~8行用于判断是否需要对训练集进行图像增强,以此在一定程度上去提高模型的泛化能力,但是在测试集上不需要。第9行用于将所有的变换操作组合到一起。第10~11行则是返回训练集或测试集并进行对应的数据变换。第12~13行构造对应的迭代器,其中num_workers和pin_memory参数均是用于提高模型训练时GPU的利用率,前者用来指定加载数据时子进程的个数,可以调成2、4、8等但并不是越大越快,后者用来指定是否锁定页内存(显存),如果是锁定页内存则存放在内存里的数据在任何情况下都不会与主机的虚拟内存进行交换,以此来提高GPU的利用率,一般适用于较大内存(显存)的主机。
3. 模型训练
进一步,需要实现一个train函数来完成整个模型的训练,实现代码如下所示:
1 def train(config):
2 train_iter, test_iter = load_dataset(config,True),load_dataset(config,False)
3 model = AlexNet(config.in_channels, config.num_classes)
4 if os.path.exists(config.model_save_path):
5 logging.info(f" # 载入模型{config.model_save_path}进行追加训练...")
6 checkpoint = torch.load(config.model_save_path)
7 model.load_state_dict(checkpoint)
8 optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
9 writer = SummaryWriter(config.summary_writer_dir)
10 model = model.to(config.device)
11 max_test_acc = 0
12 global_steps = 0
13 for epoch in range(config.epochs):
14 for i, (x, y) in enumerate(train_iter):
15 x, y = x.to(config.device), y.to(config.device)
16 ......
17 global_steps += 1
18 if i % 50 == 0:
19 acc = (logits.argmax(1) == y).float().mean()
20 writer.add_scalar('Training/Accuracy', acc, global_steps)
21 writer.add_scalar('Training/Loss', loss.item(), global_steps)
22 test_acc = evaluate(test_iter, model, config.device)
23 logging.info(f"Epochs[{epoch + 1}/{config.epochs}]--Acc on test {test_acc}")
24 writer.add_scalar('Testing/Accuracy', test_acc, global_steps)
25 if test_acc > max_test_acc:
26 max_test_acc = test_acc
27 state_dict = deepcopy(model.state_dict())
28 torch.save(state_dict, config.model_save_path)在上述代码中,第1行config表示传入的模型配置类实例化对象,关于这部分介绍可参见5.1节内容。第2行则是返回上面构造完成的训练集和测试集迭代器。第3行是根据传入的参数来实例化一个AlexNet模型,由于这里我们使用的是FashionMNIST数据集,所以输入通道数和类别分别是1和10。第4~7行表示判断本地是否已经存在训练完成的模型,如果存在则载入进行增量训练,关于这部分介绍可以参见5.3节内容。第8行表示定义优化器。第9行表示实例化一个SummaryWriter对象,用于通过Tensorboard工具来可视化整个训练过程,关于这部分介绍可以参见5.2节内容。第10、15行是分别将模型和数据集放到GPU或者是CPU上进行运算。第20~24则是分别将训练或测试过程中模型的准确率和损失进行可视化。第25~28行是根据判断条件对当前时刻的模型进行持久化保存。
在运行上述代码中之后,便可看到如下所示输出结果:
1 Epochs[1/5]--batch[0/938]--Acc: 0.125--loss: 2.302
2 Epochs[1/5]--batch[50/938]--Acc: 0.4688--loss: 1.257
3 Epochs[1/5]--batch[100/938]--Acc: 0.7344--loss: 0.7736
4 ...
5 Epochs[1/5]--Acc on test 0.8375
6 Epochs[2/5]--Acc on test 0.8842
7 Epochs[3/5]--Acc on test 0.8911
8 Epochs[4/5]--Acc on test 0.9039
9 Epochs[5/5]--Acc on test 0.9024可以看到,大约在3个Epochs后,模型在测试集上的准确率就达到了0.9055。不过AlexNet对于FashionMNIST数据集来说可能过于复杂,我们也可以适当简化模型来使训练速度更快,同时保证准确率不会出现明显下降的情况。在模型训练过程中也可以通过Tensorboard来可视化整个模型的训练过程,如图4-35所示。
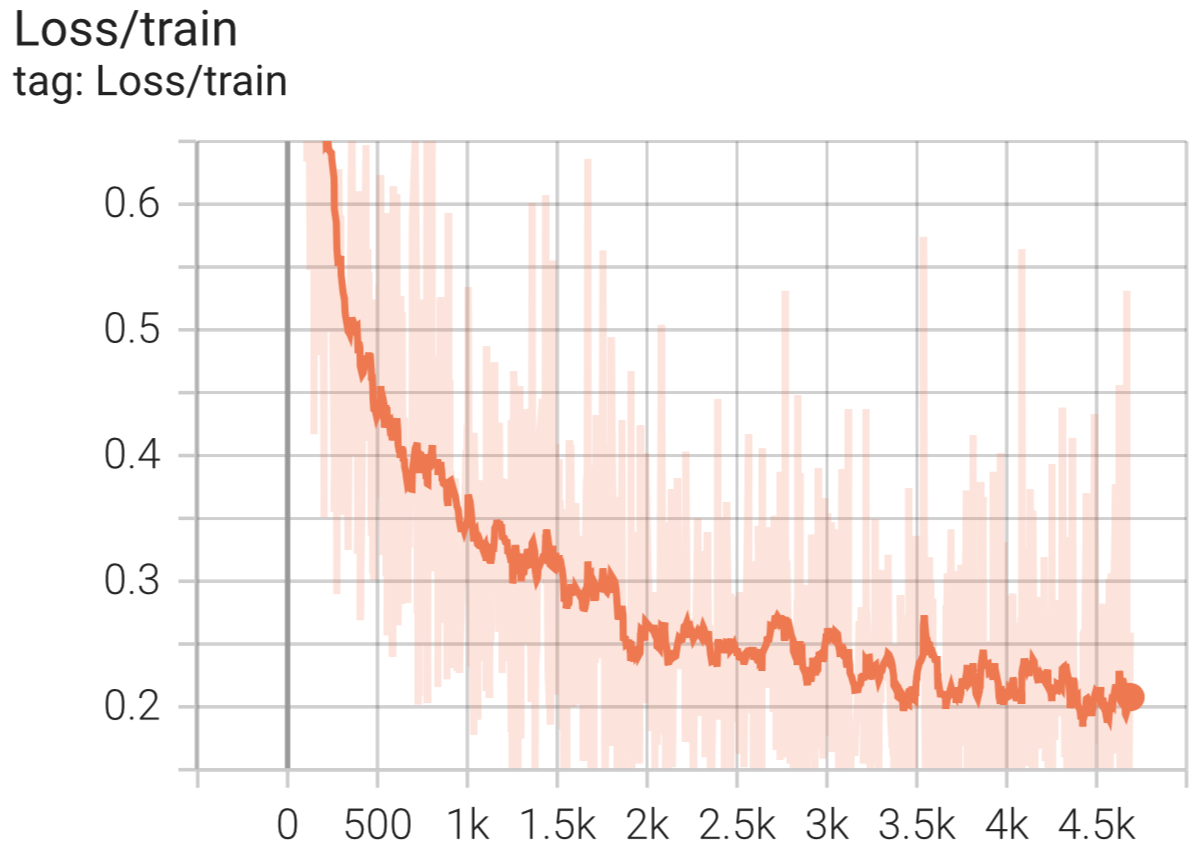
根据图4-35可以看出,模型大约在4000个小批量样本迭代过程后便开始逐步进行了收敛阶段。
4. 模型推理
最后,在完成模型训练以后便可以载入训练时持久化到本地的模型对新样本进行推理预测,实现代码如下所示:
1 def inference(config, test_iter):
2 model = AlexNet(config.in_channels, config.num_classes)
3 model.to(config.device)
4 model.eval()
5 if os.path.exists(config.model_save_path):
6 logging.info(f" # 载入模型进行推理……")
7 checkpoint = torch.load(config.model_save_path)
8 model.load_state_dict(checkpoint)
9 else:
10 raise ValueError(f" # 模型{config.model_save_path}不存在!")
11 first_batch = next(iter(test_iter))
12 with torch.no_grad():
13 logits = model(first_batch[0].to(config.device))
14 y_pred = logits.argmax(1)
15 print(f"真实标签为:{first_batch[1]}")
16 print(f"预测标签为:{y_pred}")在上述代码中,第2行表示实例化一个AlexNet模型,但此时模型的权重参数是随机状态。第4行是将模型切换至推理状态,如果是训练状态同一个输入在经过Dropout层后会产生不同的结果。第5~8行是用载入的权重参数来重新初始化模型。第11行是从测试集中取第1个小批量样本来进行测试。第12~13行则是对测试样本进行推理计算。最终输出结果如下所示:
1 # 真实标签为: tensor([5, 1, 7, 0, 5, 8, 4, 1, 9, 5, 8, 8,...])
2 # 预测标签为: tensor([5, 1, 7, 0, 5, 8, 4, 1, 9, 5, 8, 8,...])4.5.4 小结#
在本节内容中,我们首先介绍了AlexNet网络模型动机原理和模型结构,并对模型中的参数量也进行了简单的介绍;然后介绍了如何通过PyTorch来实现AlexNet网络模型,并同时介绍了在PyTorch中如何通过GPU来对模型进行训练;最后,我们还介绍了如何载入持久化的模型在新数据样本上完成模型的推理预测任务。在下一节内容中,我们将开始介绍卷积网络中的第3个经典模型VGG。
引用#
[1] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C] Advances in neural information processing systems, 2012, 1097-1105.
[2] 阿斯顿·张、李沐、扎卡里 C. 立顿等,动手学深度学习[M],2版. 北京:人民邮电出版社, 2019.